

solr中的cache的实现原理
处理器/DSP
描述
Solr简介
Solr是一个独立的企业级搜索应用服务器,它对外提供类似于Web-service的API接口。用户可以通过http请求,向搜索引擎服务器提交一定格式的XML文件,生成索引;也可以通过Http Get操作提出查找请求,并得到XML格式的返回结果。
要想知道solr的实现原理,首先得了解什么是全文检索,solr的索引创建过程和索引搜索过程。
全文检索
首先举个例子:比如现在有5个文档,我现在想从5个文档中查找出包含“solr工作原理”的文档,此时有两种做法:
1.顺序扫描法:对5个文档依次查找,包含目标字段的文档就记录下来,最后查找的结果可能是在2,3文档中,这种查找方式叫做顺序扫描法。
顺序扫描法在文档数量较少的情况下,查找速度还是很快的,但是当文档数量很多时,查找速度就差强人意了。
2.全文检索:对文档内容进行分词,对分词后的结果创建索引,然后通过对索引进行搜索的方式叫做全文检索。
全文检索就相当于根据偏旁部首或者拼音去查找字典,在文档很多的情况,这种查找速度肯定比你一个一个文档查找要快。
solr中的cache的实现原理
搭建过solr的人肯定对solrconf.xml不陌生,在《query》《/query》中有多个cache,比如filterCache、queryResultCache,documentCache。这个博客就是介绍这三个cache的意思、配置以及他们的使用。
我们直接看代码,对于这三个cache的使用是在solrIndexSearcher中,他有下面的属性
private final boolean cachingEnabled;//这个indexSearcher是否使用缓存
private final SolrCache《Query,DocSet》 filterCache;对应于filterCache
private final SolrCache《QueryResultKey,DocList》 queryResultCache;//对应于queryResultCache
private final SolrCache《Integer,Document》 documentCache;//对应于documentCache
private final SolrCache《String,UnInvertedField》 fieldValueCache;//这个稍后再说
在SolrIndexSearcher的构造方法中可以发现对上面的几个cache的赋值:
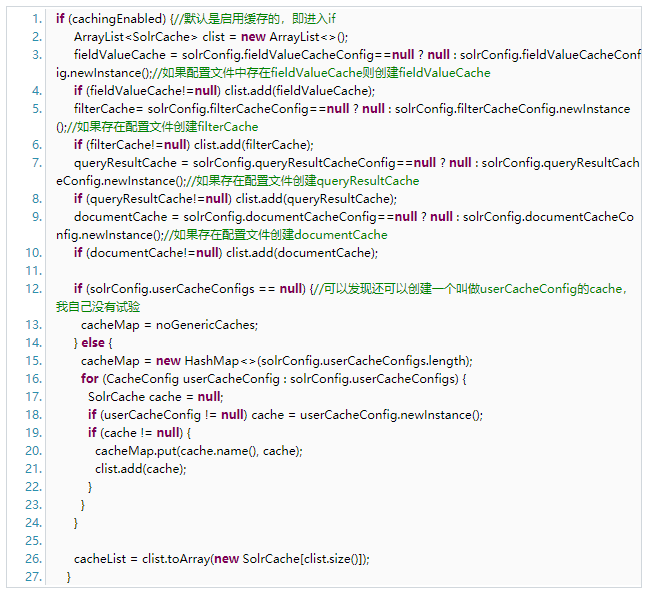
通过上面的代码可以发现,如果在solrconf.xml中配置了对应的cache,就会在solrIndexSearcher中创建对应的cache。
solrconf.xml中cache的实现原理:
我们以《filterCache class=“solr.FastLRUCache” size=“512” initialSize=“512” autowarmCount=“0”/》这个为例:创建这个cache的实现类是FastLRUCache,他的实现原理就是封装了concurrentHashMap,最大可以存放512个缓存的key,初始大小为512个,autoWarmCount这个稍后再说。在solr中默认有两个cache,一个是刚才说的FastLRUCache,还有一个是LRUCache,他的实现原理是LinkedHashMap+同步,很明显这个的性能要比前一个要差一些,所以可以将LRUCache都换为FastLRuCache。不过这两个cahce都是基于lru算法的,貌似也不适合我们的需求,最好是lfu的,所以可以通过改变这些配置,使用一个基于lfu算法的cache,当然这个不是这篇博客的内容。我们先看一下这个FastLRUCache的实现:
1、初始化cache的方法:

在FastLruCache中还有一些put,get,clear这些显而易见的方法(对生成的ConcurrentLRUCache对象操作),另外还有一个warm方法比较重要,我专门在一篇博客中写他的作用。
接下来我们进入到ConcurrentLRUCache类中,看看他的实现。
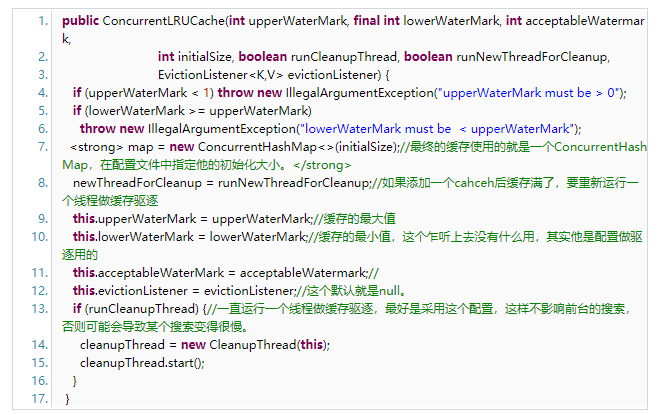
再看一下他的添加方法:

看到这里就明白了solr自带的缓存的实现原理了。(markAndSweep方法我没有完全看懂,不过不影响我们的理解)
在缓存中还有一个重要的方法是获得这个缓存的使用情况: public NamedList getStatistics() 方法,返回一个类似于map的结构,我们看看FastLRUCache的代码:
public NamedList getStatistics() {
NamedList《Serializable》 lst = new SimpleOrderedMap《》();
if (cache == null) return lst;
ConcurrentLRUCache.Stats stats = cache.getStats();//这里的stats就是用来记录缓存使用的情况的,比如大小,添加次数,访问次数、查询未命中次数,驱逐次数。
long lookups = stats.getCumulativeLookups();//这个是查询总的次数,包括命中的次数+未命中的次数
long hits = stats.getCumulativeHits();//查询的有效命中次数
long inserts = stats.getCumulativePuts();//添加缓存的次数
long evictions = stats.getCumulativeEvictions();//累计的驱逐次数
long size = stats.getCurrentSize();//大小
long clookups = 0;
long chits = 0;
long cinserts = 0;
long cevictions = 0;
// NOTE: It is safe to iterate on a CopyOnWriteArrayList
for (ConcurrentLRUCache.Stats statistiscs : statsList) {//这个是对于多个SolrIndexSearcher之间的统计,不过现在我做测试发现并没有开启,也就是统计的还是一个SolrIndexSearcher生存期间的缓存使用情况,
clookups += statistiscs.getCumulativeLookups();
chits += statistiscs.getCumulativeHits();
cinserts += statistiscs.getCumulativePuts();
cevictions += statistiscs.getCumulativeEvictions();
}
lst.add(“lookups”, lookups);//返回的结果包括这些:
lst.add(“hits”, hits);
lst.add(“hitratio”, calcHitRatio(lookups, hits));
lst.add(“inserts”, inserts);
lst.add(“evictions”, evictions);
lst.add(“size”, size);
lst.add(“warmupTime”, warmupTime);
lst.add(“cumulative_lookups”, clookups);
lst.add(“cumulative_hits”, chits);
lst.add(“cumulative_hitratio”, calcHitRatio(clookups, chits));
lst.add(“cumulative_inserts”, cinserts);
lst.add(“cumulative_evictions”, cevictions);
if (showItems != 0) {//showItem的意思是将多少个缓存的key展示出来,展示最近搜索的,
Map items = cache.getLatestAccessedItems( showItems == -1 ? Integer.MAX_VALUE : showItems );
for (Map.Entry e : (Set 《Map.Entry》)items.entrySet()) {
Object k = e.getKey();
Object v = e.getValue();
String ks = “item_” + k;
String vs = v.toString();
lst.add(ks,vs);
}
}
return lst;
}
-
Cache的原理和地址映射2023-10-31 3267
-
Python 中怎么来实现类似 Cache 的功能2023-10-17 1708
-
使用Spring Cache实现缓存2023-05-11 1782
-
CPU Cache伪共享问题2022-12-12 1315
-
什么是 Cache? Cache读写原理2022-12-06 4445
-
Solr如何管理索引库2019-06-03 1673
-
高速缓冲存储器Cache的原理、设计及实现2019-04-02 3482
-
如何使用Solr和Lucene进行数字化古籍书库的研究与实现2019-01-23 1033
-
全文检索Solr集成HanLP中文分词2018-11-29 752
-
Cache中Tag电路的设计2010-05-08 775
-
嵌入式CPU指令Cache的设计与实现2009-08-05 892
全部0条评论

快来发表一下你的评论吧 !
