

NEON技术如何实现移动端视频高效解码AV1?
描述
ARM的NEON技术,其基本原理是让处理器在每个时钟周期内完成更多工作。dav1d 0.3.1中,在解码1080p视频时,基于NEON开发的dav1d可以毫不费力地达到30 fps的流畅度。
多媒体解码是一项数据规模的挑战。解码几个像素对现代处理器来说小菜一碟,但当多媒体文件升级至每秒6200万像素的数据规模时,一般的处理器就会不堪重负。
因此,ARM的NEON技术应运而生。这项基于ARMv7与ARMv8指令集的扩展技术,其基本原理是让处理器在每个时钟周期内完成更多工作;同时,支持单指令多数据(SIMD)操作也令其在单个指令中不会一次性处理一个庞大或精确的数据,而是处理多个较小的数据。
NEON允许在单个指令中处理128位数据。几乎在所有情况下,128位都是精确有用的方法。如果我们有一个128位精度的坐标系,我们甚至可以在仙女座星系指定每个点且精确度可达0.00006皮米,这是什么概念呢?要知道最小的原子氢原子的直径也才32pm,而仙女座星系距离地球有250万光年!
很明显,如果是为了清晰且流畅呈现用户上传的视频,我们并不需要如此夸张的精确度,这也就是为什么在大多数情况下每个像素的色彩深度为8位,而若想实现HDR则需要10或12位的色彩深度。使用NEON则可通过将128位的数据精度拟合成每像素8或16位色彩深度,以防止出现路由错误。
总而言之,NEON可在单个操作中适应多个数据精度,且当视频解码器需要对大量数据进行处理时,使用NEON是一个不错的主意。
dav1d中的NEON
dav1d是由VideoLAN维护的AV1解码器,VideoLAN则是VLC媒体播放器、x264与x265视频编码器的主要推动者。很多开发人员为将此项目打造成可在几乎任何CPU上运行且处理速度最快的AV1视频编码器做出了不可磨灭的贡献。
回顾2018年12月的dav1d 0.1.0,我在不同规格的ARMv8处理器上比较基于C语言开发的dav1d与基于NEON汇编的dav1d(感谢Janne Grunau和MartinStorsjö提供的这些数据),尽管当时只有少数功能通过NEON加速,但性能仍相对于平均提高了80%。

有无NEON 代码对dav1d 0.1.0的影响
几个月后,更多基于NEON的应用逐渐出现。在得到最终结果之前,让我们先来探究一下哪些让NEON的性能如此出色。
功能及其加速
解码视频需要多个步骤,每个步骤由一项单独的函数执行,多个函数组合成视频解码处理流程;这些步骤也会根据编码器、参数与视频内容酌情增减修改。dav1d的开发人员严重依赖一个名为checkasm的工具以测试特定功能所需的时间。他们使用汇编语言编写代码并用checkasm测试,如果一些步骤的处理速度足够快那么它们就会被合并。
在MartinStorsjö的测试中,他使用了两个编译器(Clang 9和GCC 7)与三个不同的内核:Arm Cortex-A53、Arm Cortex-A72和Arm Cortex-A73。第一个是一般性能的有序核心,后两个是高性能的无序核心。
下表显示了当前基于NEON加速所有功能所得到的测试结果。其中的数字表示速度——基于C语言开发的dav1d带来了5秒钟的加速而基于NEON开发的dav1d则带来了2.5秒加速。
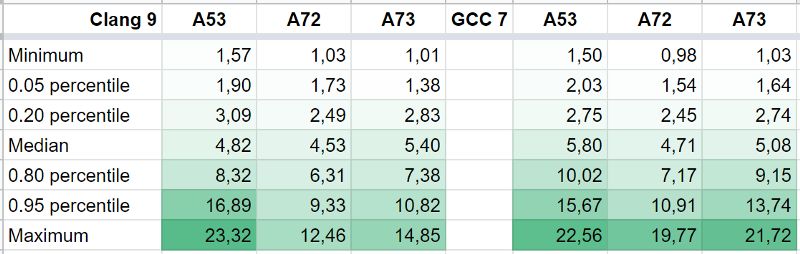
这张表的信息量远不止这些。首先,我们可以看到加速结果的分布区间非常广泛,从几个百分点到20+都涵盖在里面;其次我们还看到在大多数情况下,Clang编译器可以更好地优化基于C代码的dav1d(可以看到NEON的加速成绩更小);除此之外我们还可以发现,一般性能且有序的A53内核,其加速成绩比高性能且无序的A73内核高,而A73的效率又高于A72,其原因可能是前者的解码带宽降低。
需要明确的是,由于NEON的多项功能并非全部满负荷运行,这里的平均加速成绩并不能完全代表其整体性能。对于当前的NEON来说,其性能取决于核心和编译器。尽管计算加权平均值可以在一定程度上从侧面反映出大致性能水平,但每个视频(编码器、编码器设置、内容都不同)却存在很大差异。
但一般来说,基于NEON汇编语言形成的大多数函数,在性能优化方面会比基于编译器优化的C语言所形成的函数快4到5倍,在某些特殊情况之下可能会超过20倍。
dav1d 0.3.1性能
我将会从以下图表开始介绍:
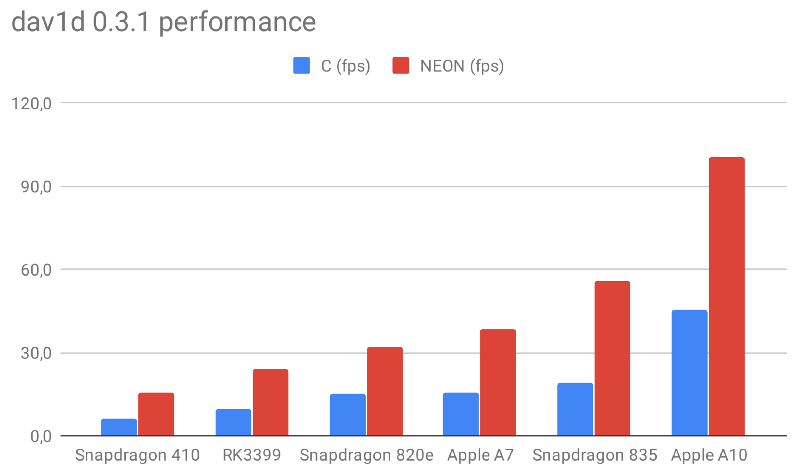
测试此1080p视频我们可以观察到结果存在巨大差异:基于编译器优化的C语言(使用Clang)开发的dav1d,其在Apple A7与Snapdragon 835平台甚至无法达到24 fps的帧率,而基于NEON开发的dav1d可以毫不费力地达到30 fps的流畅度,而Apple A10则从45 fps跃升至100 fps以上。如此性能提升对于移动设备来说意味着更低的功耗与更高效的资源利用。
如果将结果标准化,我们可以仔细查看确切的加速成果:
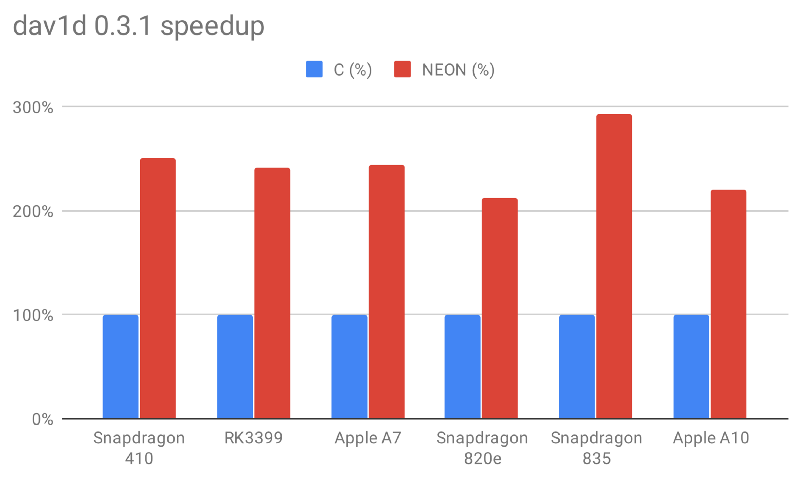
Snapdragon 835中的Cortex-A73所获得的加速最为明显,几乎是基准的3倍。其他核心平均值略低,为基准的2.5倍。这意味着从基于优化后的C语言开发的dav1d所实现的1倍性能提升到基于NEON开发的dav1d 0.1.0所实现的1.8倍性能提升,再到dav1d 0.3.1高达2.5倍的性能提升,NEON的优化成果十分显著。
展望未来
dav1d的Arm64开发还远未完成,现在需要实现的最重要功能是提高移动端的NEON整合速度(同时推广用于PC的AVX2和SSSE3),发展空间巨大。我们希望可实现比平均基准三倍以上的性能优化,同时更好的自动矢量化也可提供很多帮助,但主要的驱动程序仍然需要开发者的智慧和勤奋。
-
微软Teams应用整合AV1编解码器,降低带宽需求,提升画面清晰度2024-03-28 2081
-
谷歌计划在Android系统升级中采用libdav1d替换libgav1,提高AV1视频性能2024-02-28 3368
-
硬解之后,NVIDIA Ada架构GPU新增AV1编码2023-05-12 5530
-
Linux内核的媒体子系统正在准备完善AV1解码2021-08-17 2257
-
探究学术界AV1编码优化技术的进展2021-05-24 4459
-
剖析AV1硬件的采用及未来发展2021-05-13 4654
-
谷歌 YouTube 和 Netflix 未来将支持 AV1 硬件解码2021-02-01 3310
-
在Webex中使用AV1需要什么?2021-01-19 3642
-
智能电视将全面普及AV1视频解码2021-01-18 2369
-
NVIDIA安培架构RTX 30系列显卡支持AV1开放视频格式2020-10-19 7232
-
AV1硬件解码将在Intel处理器上实现2020-09-05 5622
-
MediaTek将携手爱奇艺共同推动AV1视频内容的发展2020-05-22 2514
-
MediaTek携手爱奇艺共同推动AV1视频内容发展2020-05-20 2029
-
NGcodec谈FPGA编码在HEVC和AV1上现状与未来2018-06-22 2636
全部0条评论

快来发表一下你的评论吧 !
