

UIUC推出最新DNN/FPGA协同方案 助力物联网终端设备AI应用
可编程逻辑
描述
UIUC、IBM 和 Inspirit IoT, Inc(英睿物联网)的研究人员提出 DNN 和 FPGA 加速器的协同设计方案(DNN/FPGA co-design),通过首创的「Auto-DNN」网络搜索引擎 +「Auto-HLS」加速器生成技术,自动生成适用于终端设备的 DNN 模型及 FPGA 加速器设计。在使用相同的终端设备,由该协同设计自动生成的物体检测方案在检测精度、速度和效能方面均大幅领先现时最优的 DAC'18 System Design Contest 冠军方案。
嵌入式 FPGA 助力 AI 应用灵活部署
现时,大量的 AI 应用被部署在物联网设备中以满足实际场景需求。纵使云端服务器能分担大部分 AI 应用的计算压力,部分对实时性要求高的任务受限于网络延时,还是需要在终端设备处理,如自动驾驶车辆、无人机上的物体识别,场景分割任务等。在物联网终端设备中部署 DNN,设计者需要克服 DNN 精度要求高、实时性要求强、能耗要求低、终端设备可用资源少等困难。
通过在终端中使用嵌入式 FPGA 作为 DNN 加速器,设计人员可获得更低的延时和能耗(对比 CPU/GPU 解决方案),以及更高的灵活度和更短的产品上市周期(对比 ASIC 解决方案)。然而,在资源受限的嵌入式 FPGA 中部署 DNN 加速器依然困难重重。
高质量 AI 应用需要 DNN/FPGA 协同设计
通常,DNN 及 FPGA 加速器会被分成两步独立设计。
一方面,DNN 设计会优先满足精度需求,并在部署时寄望硬件加速器能提供足够高的吞吐率和实时性能。但由于 DNN 在设计初期缺乏对目标硬件特性的考量,网络结构会过分复杂并产生冗余,容易超出目标硬件可承受范围。
另一方面,DNN 加速器在架构确定后会通过比例缩放计算和存储单元以适应不同大小的 FPGA。在硬件资源极度受限时,过分缩小加速器会大幅减慢 DNN 推理计算效率,最终导致无法满足应用实时性、吞吐率等要求。
上述独立设计方法需要经历多次反复设计 DNN 及加速器,如在 DNN 设计时尝试网络剪枝、稀疏化、参数量化等以减少网络推理计算量,在加速器设计时尝试不同核心计算单元、调试并行参数等以适配硬件可用资源。这类设计需要探索巨大的设计空间,异常繁琐和耗时。
为此,作者认为业界需要一种更高效的自动 DNN/FPGA 协同设计方案:在设计 DNN 时充分考虑加速器架构、资源约束等硬件因素;并且,同时生成高度优化的 FPGA 加速器以用于物联网终端设备。
自动客制化 DNN/FPGA 加速方案
本文提出的协同设计流程(图 1)共包含 4 个主要模块:1)DNN 结构模板 Bundle-Arch;2)网络搜索引擎 Auto-DNN;3)低延时加速器基础架构 Tile-Arch;4)加速器生成器 Auto-HLS。其中,前两个模块用于 DNN 结构搜索,而后两模块对应 FPGA 加速器设计。
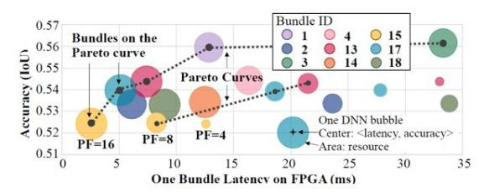
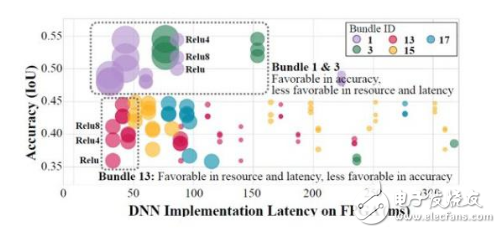
协同设计第一步是搭建 Bundle 并对 Bundle 建立计算延时和资源消耗模型。对于给定的 AI 任务(分类、物体检测等),系统从硬件 IP 池中选取神经网络组件并组合成多个 Bundle(如图 1 左下的 Bundle 1 包含了 Conv3x3,Conv5x5,Pooling 和 Relu 共 4 个 IP)作为 DNN 基本结构,并通过分析模型获取每一个 Bundle 在目标 FPGA 上的延时和资源消耗。这确保 DNN 在设计之初就包含了足够的硬件信息。
在第二步,该方案选择前 N 个满足性能和资源要求且精度最高的 Bundle 搭建原型网络。在对 Bundle 作粗 / 细粒度评估后,每一个 Bundle 将被置于「硬件性能 - DNN 精度」空间,并将硬件性能指标相近的 Bundle 分为一组。每组精度最高的若干个 Bundle(共 N 个)会被选中并交由下一步处理。
最后一步,Auto-HLS 产生精准硬件性能信息协助 Auto-DNN 更新原型网络。基于 Bundle 的 DNN 结构(图 2)拥有网络层数多寡、通道数增减等不同配置。Auto-DNN 使用随机坐标下降(SCD)算法探索 DNN 配置,并借助 Auto-HLS 产生的硬件性能信息(如运算延时、资源消耗等)为反馈,选择最适合目标硬件且精度最好的设计。
-
FPGA助力可穿戴应用快速创新【物联网大会演讲PPT】2015-01-21 3438
-
机智云5.0推出IoT套件GoKit4.0 可实现物联网应用协同开发2017-09-25 3343
-
润和软件HiHope推出HarmonyOS物联网系列模组Neptune,助力HarmonyOS生态2020-12-31 3505
-
国产开源IoTOS:腾讯物联网操作系统TencentOS Tiny的探索与实践 精选资料分享2021-07-21 1977
-
边缘智能市场要素:海量需求,物联网切分2022-08-23 2245
-
终端设备的基本描述2019-02-28 5045
-
物联网终端操作系统是怎么样的2019-11-13 1795
-
Emtelle新光纤终端设备助力高效部署FTTH2020-01-14 3149
-
科技小达人多款4G无线工业物联网网关终端设备选型表2020-01-15 6543
-
小米选择是德科技平台验证5G智能手机和物联网终端设备2022-04-21 2754
-
物联网终端设备需要什么样的天线?2023-04-03 1663
-
物联网终端的功能特点 物联网终端通用组成部分2023-05-30 3602
-
物联网终端设备的工作原理和功能讲解2023-02-03 3222
-
AI网关助力边缘物联网2024-04-15 1457
-
云翎智能低轨卫星物联网组网:煤矿设备智能管控与人员定位终端的星地协同方案2025-09-04 789
全部0条评论

快来发表一下你的评论吧 !
