

自编码器介绍
编码与解码
描述
自编码器(Autoencoder,AE),是一种利用反向传播算法使得输出值等于输入值的神经网络,它先将输入压缩成潜在空间表征,然后通过这种表征来重构输出。
自编码器是一种能够通过无监督学习,学到输入数据搞笑表示的人工神经网络。输入数据的这一高效表示称为编码,其维度一般远小于输入数据,使得自编码器可用于降维。自编码器可以用用于特征检测,也可以随机生成与训练数据类似的数据,这被称作生成模型。比如,可以用人脸图片训练自编码器,可以生成新的图片。
一个自编码器接收输入,将其转换成高i笑傲的内部表示,然后再输出输入数据的类似物。自编码器通常包括两部分:encoder(也称为识别网络)将输入转换成内部表示,decoder(也称为生成网络)将内部表示转换成输出
由于内部表示的维度小于输入数据,这称为不完备自编码器。
自编码器的理解
自编码器能从数据样本中进行无监督学习,这意味着可将这个算法应用到某个数据集中,来取得良好的性能,且不需要任何新的特征工程,只需要适当地训练数据。
但是,自编码器在图像压缩方面表现得不好。由于在某个给定数据集上训练自编码器,因此它在处理与训练集相类似的数据时可达到合理的压缩结果,但是在压缩差异较大的其他图像时效果不佳。这里,像JPEG这样的压缩技术在通用图像压缩方面会表现得更好。
训练自编码器,可以使输入通过编码器和解码器后,保留尽可能多的信息,但也可以训练自编码器来使新表征具有多种不同的属性。不同类型的自编码器旨在实现不同类型的属性。
通过施加不同约束,包括缩小隐含层的维度和加入惩罚项,使每种自编码器都具有不同属性。自编码器吸引了一大批研究和关注的主要原因之一是很长时间一段以来它被认为是解决无监督学习的可能方案,即大家觉得自编码器可以在没有标签的时候学习到数据的有用表达。
再说一次,自编码器并不是一个真正的无监督学习的算法,而是一个自监督的算法。自监督学习是监督学习的一个实例,其标签产生自输入数据。要获得一个自监督的模型,你需要想出一个靠谱的目标跟一个损失函数,问题来了,仅仅把目标设定为重构输入可能不是正确的选项。
基本上,要求模型在像素级上精确重构输入不是机器学习的兴趣所在,学习到高级的抽象特征才是。
事实上,当你的主要任务是分类、定位之类的任务时,那些对这类任务而言的最好的特征基本上都是重构输入时的最差的那种特征。
自编码器的架构
自编码器由两部分组成:
1)编码器:这部分能将输入压缩成潜在空间表征,可以用编码函数h=f(x)表示。
2)解码器:这部分能重构来自潜在空间表征的输入,可以用解码函数r=g(h)表示。
此类架构的基本结构单元为自动编码器,它通过对输入特征X按照一定规则及训练算法进行编码,将其原始特征利用低维向量重新表示。
自编码器若仅要求X≈Y,且对隐藏神经元进行稀疏约束,从而使大部分节点值为0或接近0的无效值,便得到稀疏自动编码算法。一般情况下,隐含层的神经元数应少于输入X的个数,因为此时才能保证这个网络结构的价值。
编码维数小于输入维数的欠完备自编码器可以学习数据分布最显著的特征。我们已经知道,如果赋予这类自编码器过大的容量,它就不能学到任何有用的信息。
如果隐藏编码的维数允许与输入相等,或隐藏编码维数大于输入的 过完备(overcomplete)情况下,会发生类似的问题。在这些情况下,即使是线性编码器和线性解码器也可以学会将输入复制到输出,而学不到任何有关数据分布的有用信息。
再介绍以下栈式自编码器。和其他神经网络一样,自编码器可以有多个隐层,这被称作栈式自编码器。增加隐层可以学到更复杂的编码,但千万不能使自编码过于强大。
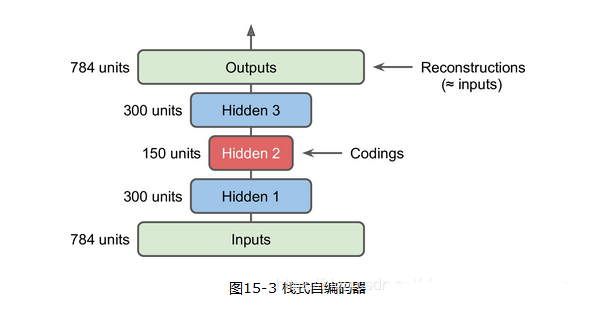
栈式自编码器要求权重对称,这就使得模型参数减半,加快了训练速度并降低了过拟合风险。
再看看去噪自编码器,它的过程如下,就是在输入阶段九加入噪声
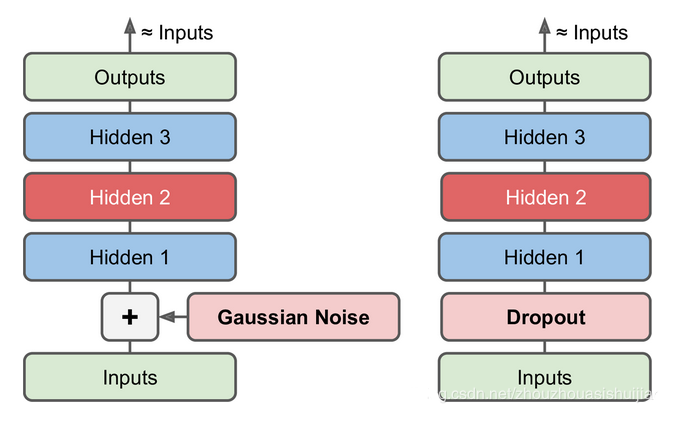
另外聊聊它的稀疏性
如果隐藏节点数目过多,甚至比可视节点数目还多的时候,自编码器不仅会丧失这种能力,更科恩那个会习得一种恒等函数。所谓稀疏性,就是对一对输入图像,隐藏节点中被激活得节点数远远小于被抑制得节点数目。那么使得神经元大部分得时间都是被抑制,称作稀疏性限制。
-
磁电编码器和光电编码器的区别2024-10-12 5109
-
自编码器的原理和类型2024-07-09 3942
-
堆叠降噪自动编码器(SDAE)2023-01-11 7983
-
基于交叉熵损失函欻的深度自编码器诊断模型2021-06-18 1068
-
自编码器神经网络应用及实验综述2021-06-07 1122
-
可实现骨骼运动重定向的通用双向循环自编码器2021-04-21 1032
-
自编码器基础理论与实现方法、应用综述2021-03-31 1219
-
基于变分自编码器的海面舰船轨迹预测算法2021-03-30 1468
-
基于稀疏自编码器的属性网络嵌入算法SAANE2021-03-27 1146
-
基于变分自编码器的异常小区检测2020-12-03 1686
-
稀疏自编码器及TensorFlow实现详解2019-06-11 4457
-
是什么让变分自编码器成为如此成功的多媒体生成工具呢?2018-04-19 14511
-
编码器,编码器是什么意思2010-03-08 3466
全部0条评论

快来发表一下你的评论吧 !
