

SoC芯片中内部总线模块的设计
接口/总线/驱动
描述
在芯片设计中,芯片内部总线的设计往往决定了芯片的性能、功耗与各模块设计的复杂度。我们设计总线往往会依据两方面的原则:一是芯片设计流程其内在的需求,二是所针对的应用对交换宽带、延时、效率、灵活性的需求。
针对芯片总线设计流程内在的需求,高效总线结构设计通常遵循的基本原则包括:同步设计、可综合、无三态信号、低延时、单触发延、支持多主控及总线仲裁(支持DMA及多CPU核)、高时钟频率独立性、支持突发(高效率)和低门数。遵循这些基本原则可以帮助我们规避很多设计上的风险,提高总线效率与IP复用度。当然,实际上述有些原则如“三态总线”,可以而且应当在某些应用中使用,只是不建议芯片及设计工程师轻易地突破这些规范,增加风险。南山之桥微电子公司在高端芯片设计中使用了三态总线技术来解决超宽总线的布线聚集与时序匹配问题。
应用的需求往往会决定总线的形式,如SoC芯片中往往会采用嵌入式CPU的总线结构。反过来说,我们选用哪一款CPU,除了成本、性能、功耗、快速精确的时序仿真模型、编译环境和可用IP外,还有重要的一点就是其总线设计是否简单、高效与有利于发挥其它设计模块的效率。

以现在较流行的ARM处理器来说,采用AMBA总线标准,其中高速芯片通常采用的AHB总线有以下几个特质:流水线式、非三态总线、支持多主控、总线仲裁与集中地址译码、应答响应机制(非实时)、支持突发。
总之,AHB总线适宜于发挥CPU的效率,符合高效总线设计的原则,但是其本身也有总线位宽限制(主要是指令集位宽)与SPLIT(切分)选项支持的复杂度。在笔者参与的设计中有一半以上不支持SPLIT选项以降低设计与验证开销,限于篇幅在此不展开阐述。最主要的问题是SoC中CPU总线一般采用应答机制,也就是非实时的,数据的处理采用中断响应机制以发挥效率。处理特定实时数据并没有固定的延时与稳定的吞吐率,那么就需要设计一个模块来处理实时数据到非实时总线之间的平滑过度问题。笔者以此模块设计为例,阐述非实时总线中实时数据切换的设计理念与几个实用技术。例子中实时数据传递采用TDM总线形式(Time Division Multiplexed,时分复用),我们称此模式为TDM模块。
TDM模块设计
TDM模块一端的界面是多路音频信号的输入与输出,另一端是AHB总线,音频数据的输入/输出,通常采用帧结构TDM形式(见图1)。其中,sp_io_xclk代表音频数据采样时钟,sp_io_xfs代表帧同步头,下面两行分别是输出与输入数据。可见,这是一个含帧格式的多通道时分实时数据传输格式。关于AMBA总线,有大量介绍资料,此处不赘述。
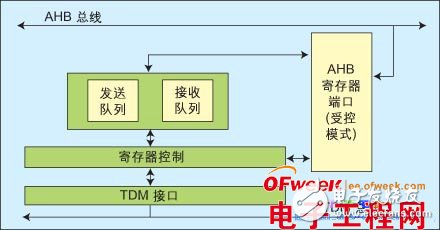
在这个模块的设计中,我们考虑了以下几个原则:平滑匹配数据传输速度、低延时与低资源占用(逻辑与存储资源)、高效使用AHB总线宽带、提高CPU处理效率、可靠性与错误处理、可控性与可观性。最基本的思路是:采用FIFO(先入先出)技术暨队列来缓冲数据传输,同时要尽量少缓存数据在队列中,以满足低延时与低资源的占用;同时采用AHB burst模式提高总线利用带宽;最后,还要提供寄存器读写来控制传输参数与状态存储,采用AHB从控模式(Slave)。初步的设计结构如图2。
DMA技术的使用时机
在这个初步设计中,缓存队列的长度计算主要取决于AHB burst的速度与频率。要少缓存数据,就要频繁进行AHB传递,也就是频繁中断CPU,这降低了CPU的处理效率。
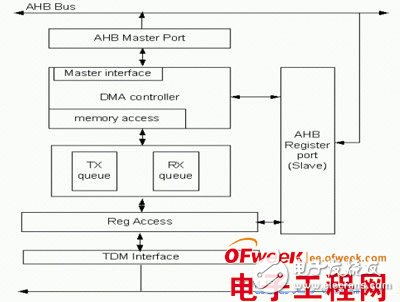
这看起来是无解的矛盾,我们可以采用DMA(Direct Memory Access,直接存储读写)技术解决。一般SoC芯片都有外接DDR/SDRAM作为最终的数据与程序缓存,TDM模块可以直接向DRAM传输实时数据,而不用频繁地中断CPU,实质上是把片内缓存的需求转移到了片外(假设总线带宽足够),既降低了队列长度又降低了中断CPU的频率,从而解决了这一对矛盾。
DMA技术实质上也是模块主动掌握总线主动权,要求采用AHB总线主控模式,最终框架结构会变成图3所示。
延时与DMA应用的矛盾
细心的读者会发现DMA的采用增加了处理延时,这不是与我们的原则矛盾吗?这里牵涉到对嵌入式CPU中音频处理算法的理解,大多数是音频压缩算法,一般都要求有一定的音频片断长度以保障压缩率与减少CPU中RTOS的调度开销。另外一些音频处理程序如回响消减DSP算法,经常采用64拍有限滤波器处理大于16ms的回响拖尾。另一些高度压缩算法(如以有限激励参数模型为基础的算法)要求对更长的音频片断做处理。所以从算法的角度,SoC系统的音频处理延时理论下限为多算法处理单元的最大值。我们只要保证DMA的传输数据延时小于这个下限就可以了,这样就充分利用了SoC系统的最小延时,进而计算DMA片断的长度也有了依据。
回到队列长度的计算上,我们现在只需要考虑TDM模块得到AHB总线使用权之间的间隙与TDM数据输入的速度差的最坏值就可以了。
队列深度=最长AHB总线获得间隔×TDM输入速率
AHB总线轮询(poll)间隙取决于总线上有几个主控模式模块与仲裁的优先级策略。一般建议实时模块享有较高优先级,当然随之而来的要求是总线申请的频度不能太高。平衡这一对矛盾的解决办法超越本文论述的范畴,读者可以从“固定权重加优先级竞争”的仲裁机制入手来设计AHB总线仲裁器。
动态切换时机与影子寄存器的使用
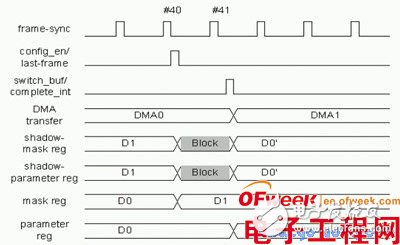
在实际应用中,我们常常发现帧格式中很多时分信道并没有音频数据,这时就要采用时分掩码来屏蔽这些信道以阻止无效数据占用带宽。问题是时分信通中是否有数据是动态变化的,动态变化的数据要求时分掩码参数也要动态分配。但是怎么切换呢?这里采用“影子寄存器”技术,原理是两套寄存器,一套参数应用于当前帧,另一套应用于下一帧。利用帧同步头的一个时钟周期实时切换。而SoC中的CPU只看到一套寄存器地址,同时配置行为本身放宽了实时要求的限制,实时切换由TDM模块完成,具体图形见图4。
错误的处理--最后一根救命稻草
如大家深知,芯片设计是没有下一次机会的,那么错误的处理就成为了“救命的稻草”。假设TDM模块很久没有得到总线的控制,出现underrun(速率过低)与overrun(速率过高)情况。要采用队列中“high-watermark(高水线)”与“low-watermark(低水线)”技术,在队列接近满与空状态发生前提前预警。预警通常反映了芯片系统中的一些设计问题与当时电压波动、干扰、局部高温等瞬间问题,这时预警信号通常用最高/次高优先级中断发生。ARM CPU本身支持高优先级中断,而我们的队列长度计算现在要重新计算,加上高优先级处理这一段时间,具体的响应时钟周期,读者请查阅相应CPU手册,这也是评价嵌入式CPU与实时操作系统(RTOS)的一项指标。
队列深度=最长AHB总线获得间隔×TDM输入速率+ARM最长中断响应时间×TDM输入速率
本文小结
我们在TDM模块简要设计中,阐述了结合各种基本技术,如从缓存队列到DMA到影子寄存器到动态分配到watermark与利用DSP算法特性,AHB总线特性、帧同步特性以及RTOS特性解决非实时与实时交换、CPU效率与资源占用、延时与DMA配置与动态切换的矛盾,追求最优解决方案的过程与设计思路。
本文并没有给出最初方案的队列计算公式,是因为要考虑的因素过多,从另一个侧面反映了它不是最优方案。好的设计应该是把复杂的需求简单化、模块化,当然实际设计中比这种简化设计要复杂,例如还要解决实时数据传输中双方时钟不同步等问题。但读者只要掌握了基本思路与技术,理解应用特性、CPU特性及RTOS特性与算法,就可举一反三,做出最优的设计。
-
RISC-V芯片中使用的各种常用总线释义2024-12-28 1744
-
蓝牙芯片中的晶振:内部集成与功能解析2024-10-24 6363
-
深入解析TC3xx芯片中的SMU模块应用2024-03-01 4103
-
一文了解SOC的DFT策略及全芯片测试的内容2023-12-22 5287
-
STM32芯片内部的总线系统结构2023-06-22 6650
-
SOC芯片的DFT策略的可测试性设计2023-04-03 10296
-
SoC芯片解析2021-10-27 4044
-
FPGA-SoC芯片中EDAC模块的设计与实现2021-09-27 1173
-
AMBA片上总线在SoC芯片设计中的应用是什么?2021-05-28 1845
-
解析MIPS内核的HDTV-SoC平台总线接口模块2021-04-07 3859
-
基于NAND FLASH控制器的自启动方式实现SOC系统的设计2020-05-20 3180
-
SoC系统级芯片2016-05-24 7223
-
什么是soc芯片2010-09-10 51579
-
SOC总线仲裁算法的研究2009-09-15 1004
全部0条评论

快来发表一下你的评论吧 !
