

赛灵思系列为嵌入式系统工程设计群体带来高性能和灵活性
描述
赛灵思 Zynq-7000 All Programmable SoC 系列代表了嵌入式设计的新局面,为嵌入式系统工程设计群体带来前所未有的高性能和灵活性。这些产品在单个器件上集成了特性丰富的双核 ARM Cortex-A9 MPCore 处理系统和赛灵思可编程逻辑。3,000 多个互联点将片上处理系统 (PS) 与片上可编程逻辑 (PL) 相连,使两个片上系统之间的性能达到了任何双芯片处理器 FPGA 都无法匹敌的高度。赛灵思在 2011 年发布这款 Zynq SoC 器件时,便立即得到了很多精通硬件设计语言和方法以及嵌入式软件开发的嵌入式系统工程师和架构师的追捧。如今,首款 Zynq SoC 已被用于无线基础设施、智能工厂和智能视频/视觉等多种嵌入式应用领域,并且快速成为高级驾驶员辅助系统约定俗成的标准平台。
为了让这款性能卓越的器件能够被具有很强软件背景但没有 HDL 经验的嵌入式工程师所用,赛灵思在今年年初推出了基于 Eclipse 的 SDSoC 集成开发环境,使软件工程师能够对 Zynq SoC 中的可编程逻辑和 ARM 处理系统进行编程。
我们仔细了解一下 Zynq SoC [1] 的特性以及软件工程师如何利用 SDSoC 环境来创建用任何其他“处理器+FPGA”系统均无法实现的系统设计。为进行研究,我们将使用包含一个 Zynq Z-7020-1 器件的赛灵思 ZC702 评估板 [2] 作为硬件平台。
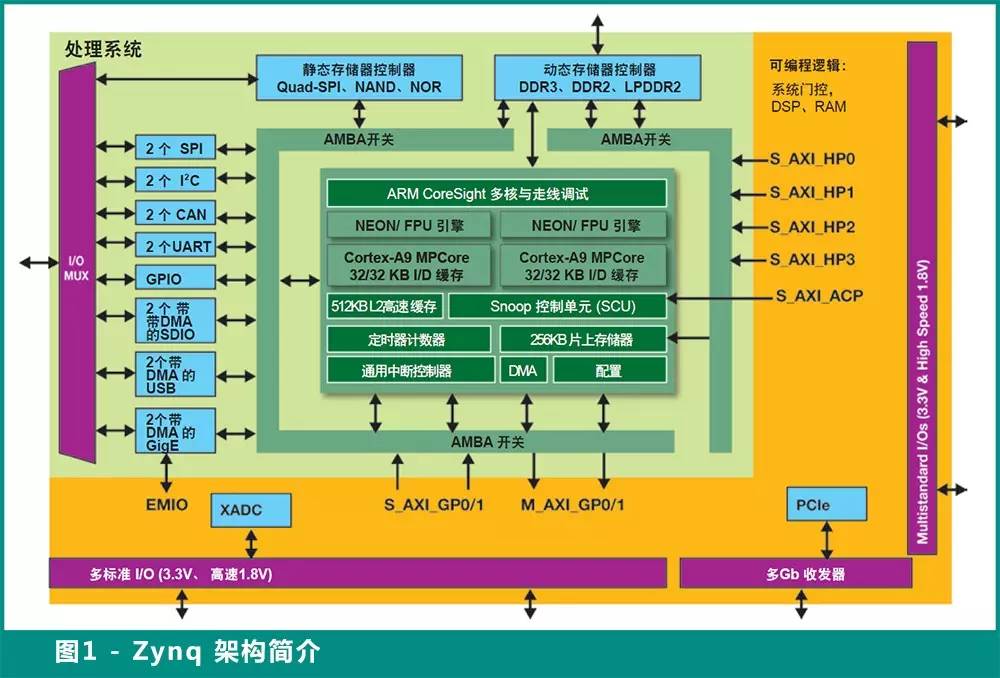
如图 1 所示,Zynq SoC 包含两大功能模块:PS(包含应用处理器单元、存储器接口、外设和互联)和 PL(传统的 FPGA 架构)。
PS 和 PL 通过与 ARM AMBA AXI4 接口兼容的互联链路紧密耦合在一起。四个高性能 (HP) AXI4 接口端口将 PL 连接到 PS 中的异步 FIFO 接口 (AFI) 模块,从而在 PL和 PS 存储器系统(DDR 和片上存储器)之间提供一条高吞吐量的数据路径。AXI4 加速器一致性端口 (ACP) 允许直接从 PL 主设备对 L1 和 L2 高速缓存进行低时延的一致性访问。通用 (GP) 端口包含可从 PS 和 PL 访问的低性能通用端口。
在传统的以硬件设计为核心的流程中,通过使用赛灵思的 Vivado Design Suite 在 Zynq SoC 上设计嵌入式系统大致需要四个步骤:
系统架构师确定硬件-软件分区方案。计算密集型算法最适合硬件。特性分析结果是鉴别性能瓶颈以及在数据移动成本与加速优势之间进行权衡研究的基础。
硬件工程师处理被分到硬件中的功能,并将它们转换或设计成 IP 核,例如,用 Vivado 取代 VHDL 或 Verilog ;用 Vivado 高层次综合 (HLS) 实现 C/C++ 高层次综合[3],或者用 Vivado System Generator for DSP 实现模型化设计 [4]。
然后,工程师使用 Vivado IP Integrator [5]创建整个嵌入式系统的模块化设计。整个系统的开发需要用到不同的数据移动工具(AXI-DMA、AXI Memory Master、AXI-FIFO 等),以及连接 PL IP 与 PS 的AXI 接口(GP、HP 和 ACP)。一旦 IP Integrator 中所有设计规则检查都通过,就可将项目导出至赛灵思软件开发套件 (SDK) [6]。
软件工程师使用赛灵思 SDK 开发针对 PS 中 ARM处理器的驱动程序和应用。
最近几年,赛灵思对 Vivado Design Suite 的简便易用性实现了显著提高,该套件能够让工程师缩短 IP 开发时间以及 IP 模块连接步骤(上述步骤 2 以及步骤 3 的部分内容)。就 IP 开发而言,采用这些最新设计技术(例如在 Vivado HLS 工具中实现 C/C++ 高层次综合;用 Vivado System Generator for DSP 实现模型化设计)可以显著缩短开发和验证时间,同时让设计团队能够使用高层次抽象探索更大的架构范围。对于使用 VHDL 或 Verilog 需要数周才能完成的设计,利用新型工具只需数天就能完成。
SDSoC 环境会自动安排所有必要的赛灵思工具,以生成针对 Zynq SoC 的完整软硬件系统,而且所需的用户介入程度很小。
赛灵思通过 Vivado IP Integrator 可进一步强化流程。Vivado Design Suite 的这个功能使设计人员只需要在图形用户界面 (GUI) 中连接 IP 模块,就可以设计复杂的硬件系统(嵌入式或非嵌入式),从而实现快速的硬件系统集成。
新的 Vivado Design Suite 功能可帮助设计与开发团队简化 Zynq SoC 的使用。但对于以硬件为中心的优化流程而言,要缩短探索不同数据移动工具和 PS-PL接口(步骤 3 的一部分)以及写入和调试驱动程序与应用(步骤 4)所需的开发时间,办法并不多。如果整个系统不能满足吞吐量、时延或占位面积等方面的设计要求,那么设计团队不得不修改步骤 3 中的系统连接,以重构硬件架构。这些修改会不可避免地导致步骤 4 中的软件应用发生变化。有些情况下,加速不足或者硬件利用率过高会迫使开发团队重新考虑最初的软硬件分区。多个硬件和软件团队将不得不再次反复设计系统,以探索可能满足最终要求的其他架构。
这些实例表明手动进行系统优化对上市时间的影响。系统优化对于紧密集成的系统(例如 Zynq SoC)很关键,因为瓶颈经常发生在 PS 与 PL 之间的系统连接上。
SDSoC 环境能大大简化 Zynq SoC 开发过程,可将步骤 2、3、4 实现高度自动化,以缩短总开发时间。该开发环境会生成必要的硬件和软件组件,用以同步硬件和软件并保存源程序语义,同时支持任务级并行处理和流水线化的通信与计算,从而实现高性能。SDSoC 环境会自动安排所有必要的赛灵思工具(Vivado、IP Integrator、HLS 和 SDK),以生成针对Zynq SoC 的完整软硬件系统,而且所需的用户介入程度很小。
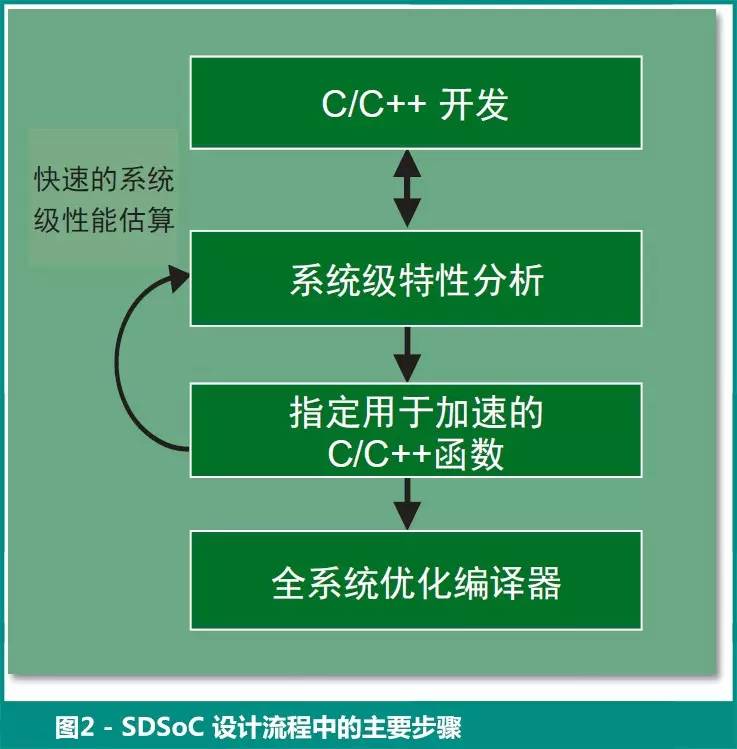
假设我们已有一个针对 PS 的完全用 C/C++ 描述的应用,而且已经决定将哪些功能分配到 PL 以实现加速,那么 SDSoC 开发流程大致按照如下所示(图2):
SDSoC 环境使用快速估算流程(通过调用内含的Vivado HLS)构建应用项目。这样在数分钟内就能大致估算出性能和资源情况。
如果我们认为有必要,我们会用适当的指令优化 C/C++ 应用和硬件功能,并重新运行估算直到实现所需的性能和占位面积。
然后,SDSoC 环境构建整个系统。该过程会生成完整的 Vivado Design Suite 项目和比特流,以及一个针对 Linux、FreeRTOS 或裸机的可引导的运行时间软件映像。
用 SDSOC 环境进行硬件 VS 软件的性能估算
线性代数几乎在任何工程领域中都是基础而强大的工具,能够计算求解具有多维变量的方程组。例如,工程师可将线性控制理论系统描述为“状态”和“状态变换”矩阵。图像的数字信号处理是线性代数的另一个典型应用。尤其是,通过 Cholesky 分解进行矩阵求逆被认为是求解方程组或矩阵求逆的最有效的方法之一。现在让我们仔细看一看 32 位浮点实际数据 64 x 64 矩阵的 Cholesky 分解,并作为 Zynq SoC 上软硬件分区的应用实例。
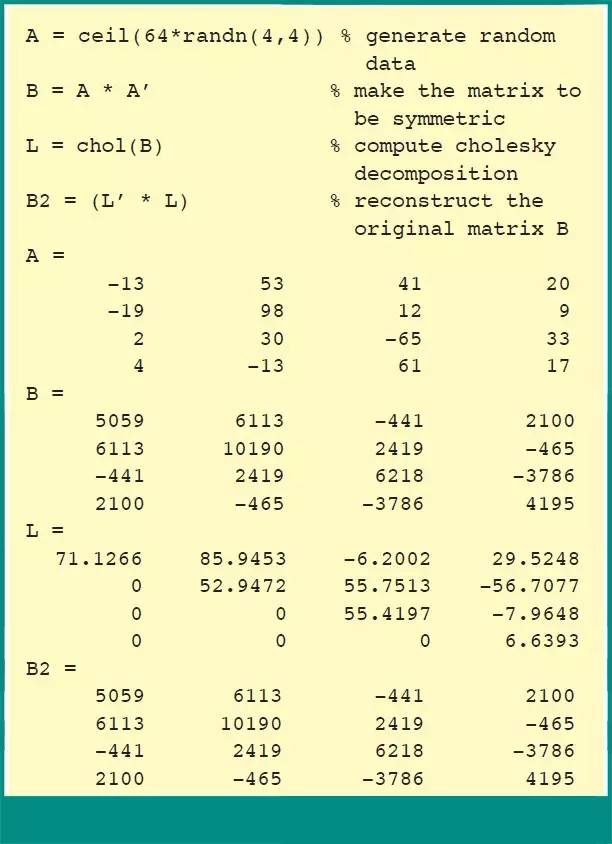
Cholesky 分解将正定矩阵变换为具有严格正对角线的下三角和上三角矩阵的乘积。矩阵 B 在三角矩阵 L 中分解,即 B = L’ * L,其中 L’ 是 L 的转置矩阵,如下面的 4 x 4 矩阵 MATLAB 代码所示:
选择加速器很简单,只需在 SDSoC 环境的图形用户界面 (GUI) 中用鼠标点击特定功能即可。
让我们看看如何估算应用设计的性能和资源利用率,而且无需经过整个构建周期。
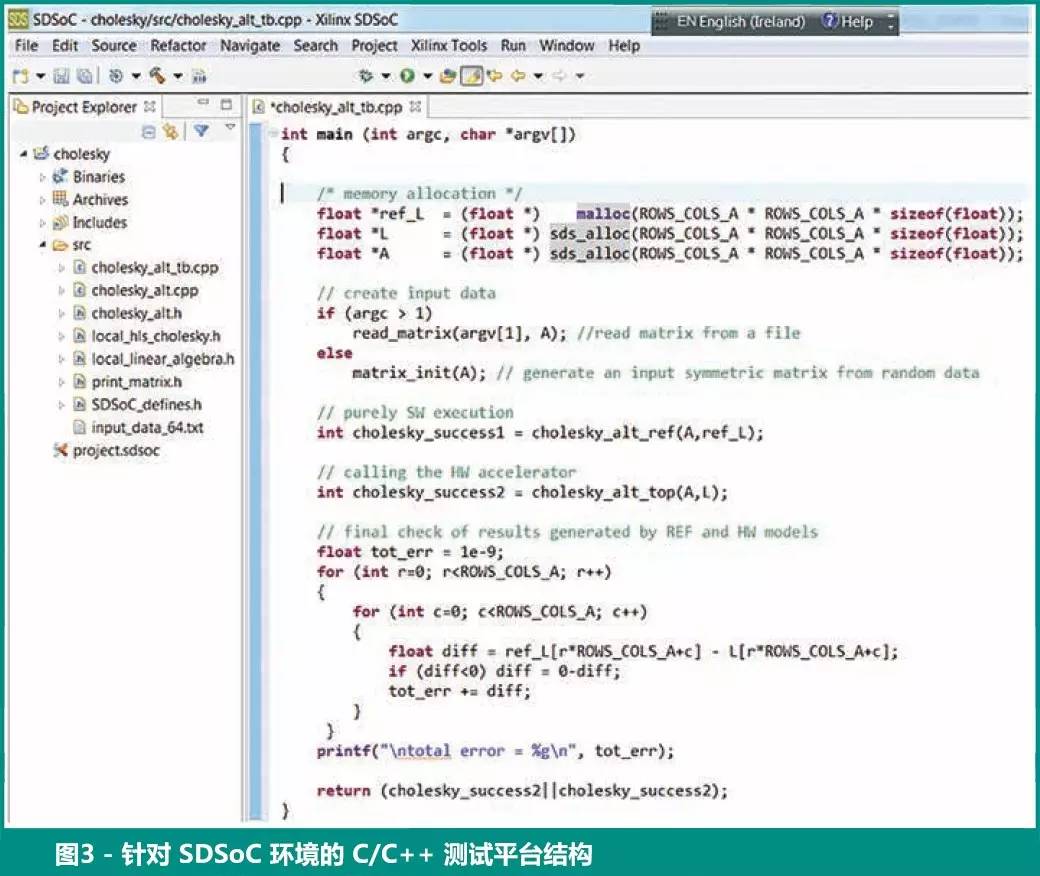
图 3 给出了适合 SDSoC 环境的测试平台结构。主程序为所有空矩阵分配动态存储器并填入数据(从文件中读入或者随机生成)。然后,主程序调用参考软件函数和硬件备选函数。最后,主程序检查两个函数计算出的数值结果以测试有效正确性。
注意,这里针对每个输入/输出数组使用了一个名为sds_alloc 的专用存储分配器,以让 SDSoC 环境自动在硬件加速器的每个 I/O 端口之间插入一个 Simple DMA IP;相比之下,malloc 则实例化一个 Scatter-Gather DMA,用以处理分布在物理地址空间中多个非连续页面上的数组。Simple DMA 从占位面积和性能开销上将要比 Scatter-Gather DMA 廉价,但需要 sds_alloc 获得物理上的连续存储空间。
选择加速器很简单,只需在 SDSoC 环境的图形用户界面 (GUI) 中用鼠标点击特定功能即可。如图 4 所示,例程 cholesky_alt_top 标记为 “H”,以表明它将被送到硬件加速器。我们还可以为加速器和数据移动内核选择时钟频率(如图 4 的 SDSoC 项目页面中所示为 100 MHz)。
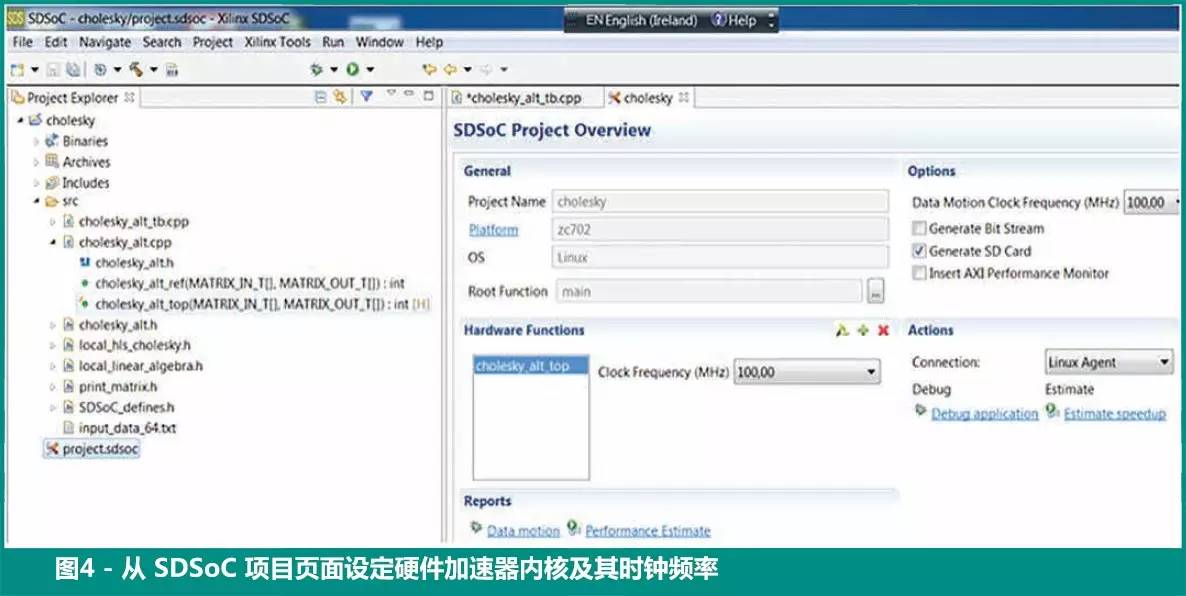
现在,我们可以启动“估算加速”过程。在经过几分钟的编译后,我们就可以在 Vivado 项目中生成所有内核和数据移动网络。SDSoC 环境还生成一个 SD 卡映像,其中包含 Linux 引导映像,里面有 FPGA 比特流以及纯软件版本的二进制应用程序。我们从这个 SD卡引导,并在 ZC702 目标平台上运行应用。
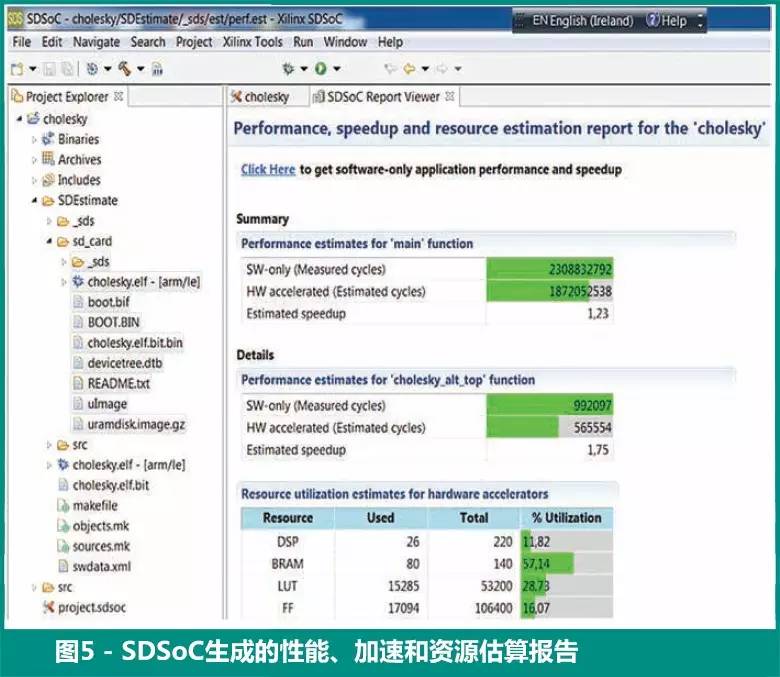
Linux 在开发板上启动之后,我们可执行纯软件应用,然后,SDSoC 环境生成图 5 中的性能估算报告。如果在硬件中而非软件中执行,我们可看到 cholesky_alt_top 函数的 FPGA 资源利用率 (26 DSP、80 BRAM、 15,285 LUT、17,094 FF) 和性能加速 (1.75)。
在主应用程序方面,我们还可以看到总体加速比较低 (1.23),原因在于其他软件开销,例如 malloc 和数据传输。我们的整个应用比较小,主要在于展示 SDSoC 流程和设计方法;我们需要在 PL 中加速更多例程,但这超出了本文的范畴。
使用 SDSoC 环境,只要几分钟就能生成该信息,且无需综合和布局布线这样的 FPGA 编译过程;这些过程根据硬件系统的复杂程度可能需要数小时才能完成。这样的估算通常足以用来分析硬件-软件分区的系统级性能,并让用户能够迅速进行设计迭代以创建出最佳系统。
了解性能估算结果
当 SDSoC 开发环境针对估算加速进程编译应用代码时,会生成一个中间目录 (图 5 中的_sds),用来放置所有中间项目(Vivado HLS、Vivado IP Integrator 等)。它会特别在源代码中插入对自由运行的 ARM 性能计数器函数 sds_clock_counter() 的调用,以测量程序函数中关键部分的执行时间。这也就是为什么目标板需要在估算加速进程中与SDSoC 环境的 GUI 连接。图 5 中报告的所有数字都在运行执行过程中用这些计数器测量得到。唯一的例外是硬件加速函数,该函数直到整个 FPGA 构建(包括布局布线)完成后才存在。不过,Vivado HLS 会在有效 Vivado HLS 的综合步骤过程中在估算资源利用率的同时计算硬件加速函数的估算周期数。
假设备选硬件加速器函数以 FHW MHz 时钟频率运行,并需要 CKHW 个时钟周期完成整个计算(这是时延概念),并且假设在 ARM CPU 执行时,函数在 FARM MHz 时钟频率下占用 CKARM 个周期,那么,如果计算时间相同,硬件加速器就能实现与 ARM CPU 相同的性能,即 CKHW / FHW= CKARM / FARM。从这个公式中我们得到 CKARM = CKHW*FARM / FHW。这代表加速器能为处理器分担的最大时钟周期数量,以展示将函数迁移到硬件而获得的加速效果。
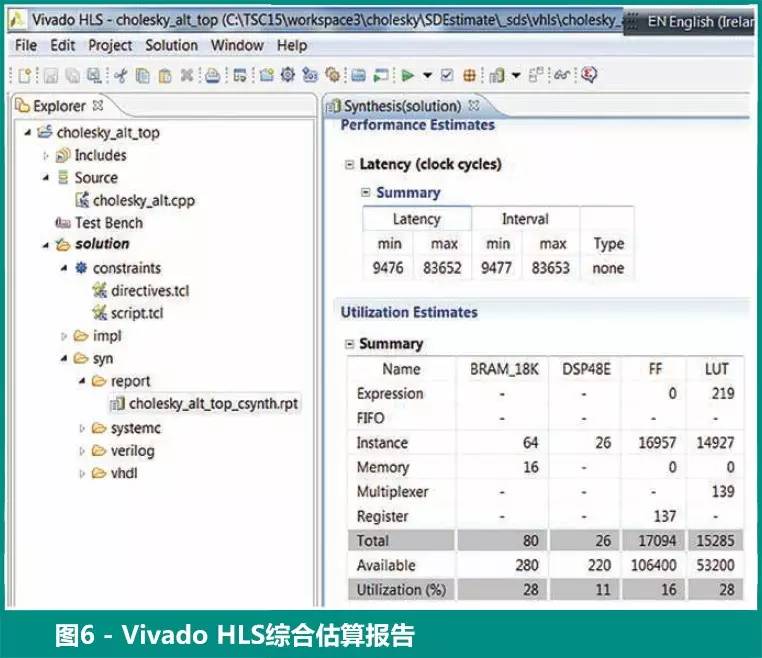
图 6 中报告了 Vivado HLS 综合估算结果。注意,硬件加速器时延为 CKHW = 83,652 个周期,时钟频率 FHW = 100-MHz。在 ZC702板 中,FARM = 666 MHz,而且 CKARM = CKHW*FARM / FHW = 83,653*666/100 = 557,128,获得的硬件加速效果与图 5 中 SDSoC 环境报告的 565,554 个周期达到了很好的匹配。这就是为什么 SDSoC 环境能估算加速器所需的时钟周期数量而又不需要进行实际的布局布线。
用 SDSOC 环境构建硬件-软件系统
在确定硬件加速有效果之后,我们可以用 SDSoC 环境实现整个硬件和软件系统。我们需要做的是添加正确的指令(以 Pragma 命令的形式)来分别指定 FIFO 接口(由于 I/O 阵列的连续扫描);在运行时针对任何加速器调用而需传送的数据量;连接 PL 中的 IP 核与 PS 的 AXI 端口类型;以及数据移动工具的类型。下面的 C/C++ 代码表明了这些指令的使用。注意,实际情况下最后的指令不需要,原因是 SDSoC 环境会因 sds_alloc 的使用而实例化一个 Simple DMA;我们在这里提到它只是为了说清楚。
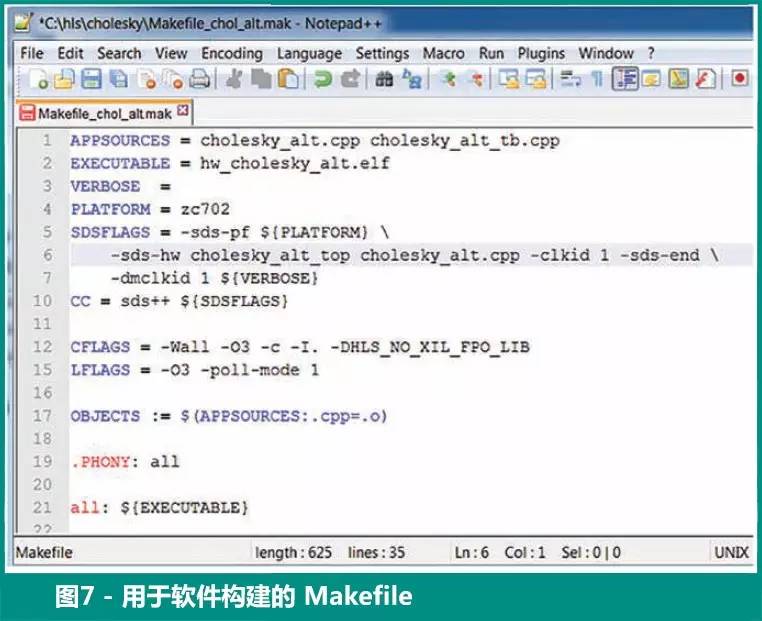
我们可以在 SDSoC 环境的 GUI 中直接在 Release 配置中构建项目,或者,也可使用图 7 中的 Makefile 并从 SDSoC 工具命令语言 (Tcl) 解释器中启动。不管是Vivado Design Suite 中的什么工具,设计人员都可以采用 GUI 或 Tcl 脚本。为了提高加速效果,我们将硬件加速器的时钟频率增加至 FHW =142 MHz(通过-clkid 1 makefile 标志设置)。
FPGA 编译完成后不到半个小时,我们就得到对ZC702 板进行编程的比特流以及在 Linux OS 上执行的可执行连接文件 (ELF) 格式文件。然后,我们在ZC702 板上测量性能:纯软件时是 995,592 个周期,有硬件加速时是 402,529 个周期。因此,cholesky_alt_top 函数的有效性能提升 2.47。
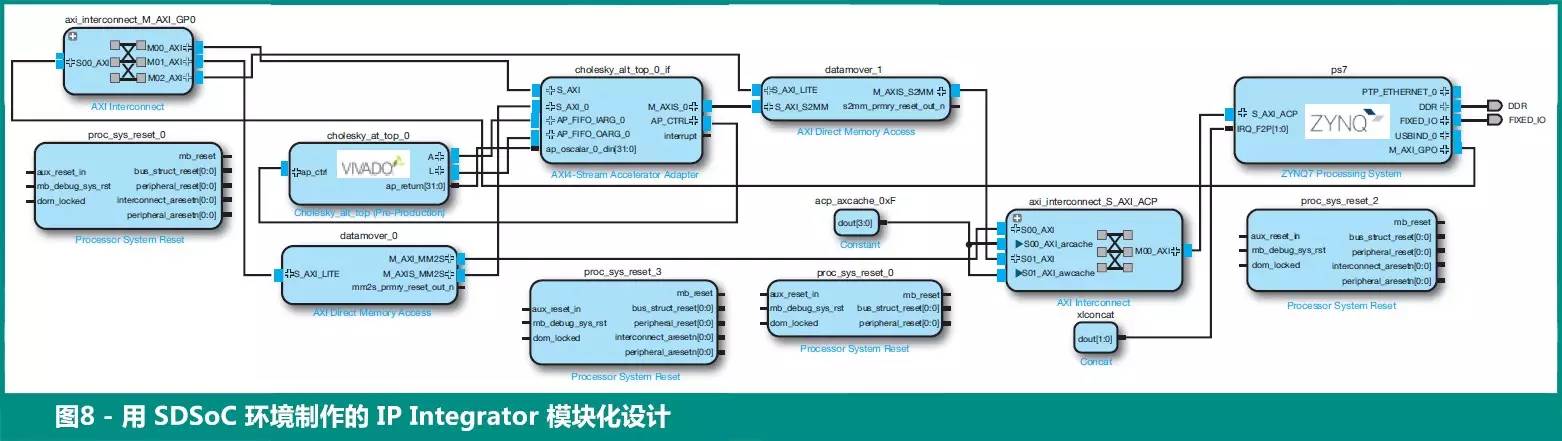
图 8 给出了整个嵌入式系统的方框图;SDSoC 环境将 Vivado IP Integrator 方框图以 HTML 文件报告的形式给出,以使其易于阅读(图 9)。该报告清楚显示,硬件加速器通过简单 AXI4-DMA 连接 ACP 端口,而通用端口用来通过 AXI4-Lite 接口设置加速器。

在嵌入式系统启动并运行时,我们需要花多长时间为 ZC702 板生成 SD 卡?我们需要一个工作日来编写适合 Vivado HLS 和 SDSoC 环境的 C++ 测试平台,然后,用一个小时进行实验以从 Linear Algebra HLS Library 中获得好的结果,再用一个小时的时间通过SDSoC 环境创建嵌入式系统(FPGA 编译过程)。这个过程共需要 10 个小时。我们估算手动完成所有这些工作(步骤 3 用 Vivado IP Integrator,步骤 4 用赛灵思SDK)至少需要两周的辛苦工作,这还不算高效使用这些工具所需的时间。
FPGA 编译完成后不到半个小时,我们就得到对 ZC702 板进行编程的比特流以及在 Linux OS 上执行的 ELF 格式文件。
SDSoC 开发环境使更多嵌入式系统和软件开发人员能够凭借熟悉的嵌入式 C/C++ 开发经验针对 Zynq SoC 开展工作。包括业界首款 C/C++ 全系统优化编译器的 SDSoC 环境提供系统级特性分析、可编程逻辑中的自动软件加速、自动系统连接生成和库,以加快开发速度。
-
多核处理器SoC设计怎么才能满足嵌入式系统应用?2019-08-01 2551
-
请问如何设计一个灵活、高性能的嵌入式系统?2021-04-22 965
-
嵌入式Linux的灵活性2021-11-04 1328
-
赛灵思:面向动态应用的灵活操作系统2011-09-01 1114
-
赛灵思强化嵌入式视觉应用与工业物联网产品系列2017-02-08 333
-
设计灵活、高性能的嵌入式系统解析2017-11-07 782
-
赛灵思扩大生态系统,重塑嵌入式视觉、工业物联网系统设计的未来2018-02-14 4137
-
Arm携手赛灵思助力嵌入式开发人员获取成熟的Arm IP2018-10-11 3854
-
赛灵思全可编程提供SoC产品系列提供系统性能、灵活性和可扩展性2019-07-29 2773
-
性能优良的赛思灵FPGA嵌入式处理器平台2019-06-28 2819
-
嵌入式系统教程之嵌入式系统工程设计的详细资料说明2019-07-23 2347
-
FPGA为嵌入式设计带来了强大的功能与灵活性2023-12-07 1807
全部0条评论

快来发表一下你的评论吧 !
