

赛灵思解读异构计算
描述
什么是异构计算?
异构计算,可能在很多人看来感觉高深莫测,我们可以先用一个比喻来简单的解释一下。比如在做简单的整数算数时,知道算法口诀的人,心算即可,但遇到比较复杂的算数问题时,就得需要一个计算器了,而在这个运算过程中,一些简单的计算可以提前由心算完成再输入计算器,比如计算“(5+2)÷26”,可能我们直接就输入“7÷26”了。又或者是完全交给计算器进行计算,但这也需要人脑控制手指进行计算器的数值输入,此时你的大脑与计算器就构成了完成这道数学计算任务的“异构计算系统”。
日常生活中最常见的异构计算——人脑+计算器
就像你的大脑的结构与计算器完全不一样,异构计算,顾名思义就是在系统内,参与计算的执行单元在指令集架构(ISA, Instruction Set Architectures)层面是不同的。最为典型的例子,就是通用计算图形处理器(GPGPU,General-Purpose computing on Graphics Processing Units),与现场可编程门阵列 (FPGA,Field-Programmable Gate Array)和传统CPU平台组成的异构计算系统。从严格意义上讲,ISA相同,只是不同大小的处理核心的组合,并不算是异构计算,比如英特尔的x86处理器+MIC(集成众核加速器),以及ARM处理器的big.LITTLE大小核心的混合设计。
异构计算简史
为什么要用异构计算,想想开头的例子就清楚了,如果人脑就是主流的通用处理器的话,那么异构计算就是为这个处理器额外配备的“计算器”或工具,用来执行更高复杂度的计算或应用,而这种复杂度主要指的就是超大规模的并行处理,对于更擅长串行处理的CPU来说是一个极大的互补。
异构计算的概念本身其实并不新鲜,最早可以追溯到30年前(在某些定义中,则是以指令集的处理模式来区分异构与否,但基本上已并非是主流概念),可要谈到异构计算的真正崛起,则要从2001年用GPU实现通用矩阵计算开始,而标志性事件发生在2005年,GPU终于在执行LU分解(用于解线性方程组)的性能方面战胜了CPU,从那之后,基于GPU的大规模并行计算方案开始崭露头角。
CPU+GPGPU是目前最为知名的异构计算组合,也是第一代异构计算的典型代表
2007年,NVIDIA推出了专门用于简化GPU应用编程的统一计算设备架构(CUDA,Compute Unified Device Architecture),它标志着GPU的通用计算应用开发开始走向易用、成熟。时至今日,GPU+CPU的异构计算平台已经越来越多的出现在高性能计算系统中(HPC),大大弥补了CPU在浮点运算方面的能力。
当然,在GPGPU之前其实还有多种芯片在向通用计算领域迈进,其中之一就是FPGA,它是最可匹敌GPGPU的异构计算技术。
2012年英特尔发布的Atom E6x5C嵌入式处理器,就已经在单Socket封装上整合了Altera的FPGA,但这个FPGA的主要任务不是计算,而是针对不同应用场景的I/O定制化与指定的信号处理,很难用于通用场合
FPGA于1985年诞生,很快就开始尝试在通用计算领域的运用,可以说比GPGPU的出现还要早。GPGPU所擅长的浮点运算,FPGA同样也在积极参与,但成果远没有GPGPU显著(看看超级计算机全球TOP500的排名配置就知道了)。在整数型运算方面,虽然FPGA更有优势,可惜那时的计算量除非个别应用,普遍并不大,CPU自己就能搞定,所以FPGA加速更多用于细分应用市场,应用规模相对来说并不大。不过,随着物联网、大数据、人工智能、机器学习等新兴的大规模数据处理需求的不断涌现,现在它的机会要来了,而且底层互联 技术也比当前的异构系统更为先进,它就是由OpenPOWER CAPI所开辟的新一代异构计算平台,主打CAPI+FPGA的组合。
而在我看来,它们其实是开启了第二代异构计算的时代。
FPGA如何为应用加速?
从第一款FPGA芯片于1985年由Xilinx(赛灵思)正式推出至今,已经有30年了,它是在可编程阵列逻辑(PAL,Programmable Array Logic)、通用阵列逻辑(GAL,Generic Array Logic)、复杂可编程逻辑器件(CPLD,Complex Programmable Logic Device) 等技术的基础上进一步发展的产物。与CPU不同的是,它的逻辑是硬件可编程的,而CPU则是通过软件编程来执行相应的计算,和专用集成电路(ASIC,Application Specific Integrated Circuit)相比,它又相当于一种半成品的逻辑芯片,ASIC则是针对某类应用进行专门的固化设计,以达到最优的性能。
从字面意思上就可以想像得到FPGA是一个可随意定制内部逻辑的阵列,并且可以在用户现场进行即时编程,以修改内部的硬件逻辑,这一点是CPU和ASIC都无法做到的。要想明白FPGA的原理,的确需要一定的数字电路基础,在此只做简要的介绍,以解释为什么FPGA可以在某些工作上比CPU更为出色。
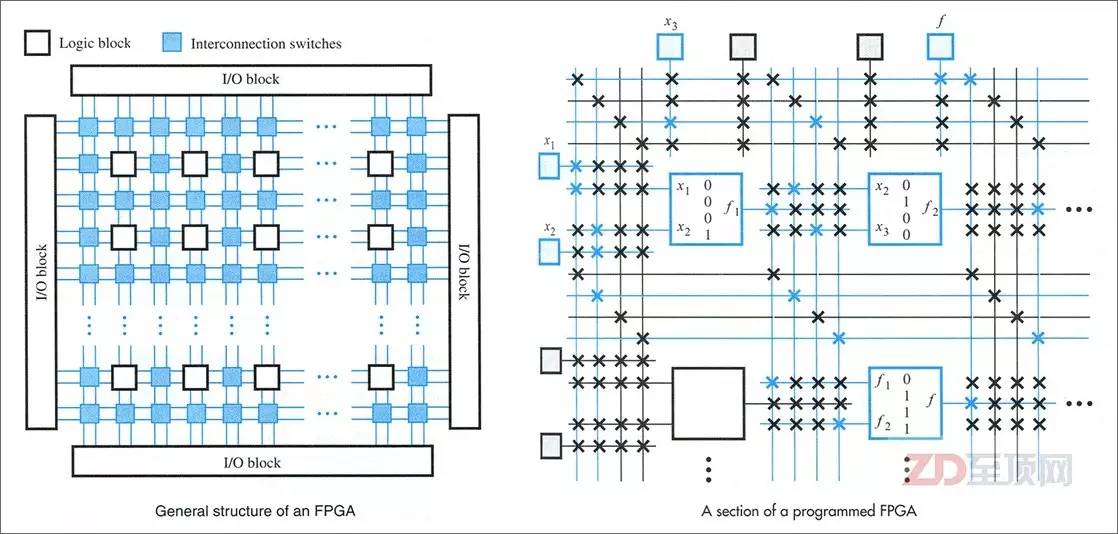
FPGA的内部主要是由用于实现硬件逻辑的逻辑块(LB,Logic Block)、负责LB互联的内部互联交换节点(IS,Interconnection Switch)以及负责输入输出的I/O Block组成,它们都是可编程的,而随着技术的进步,FPGA芯片里也越来越多的集成相关的固定器件与硬核(IP)电路,如乘法器、数字信号处理器(Digital Signal Processor)等,以进一步加速相关的运算,并完善相关的功能(比如I/O)
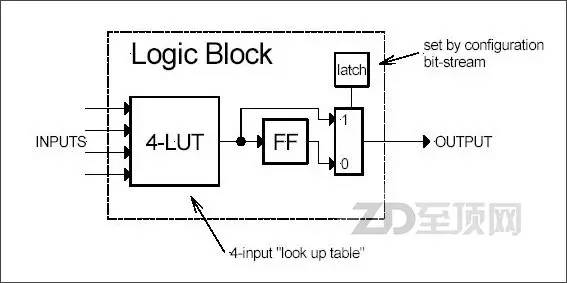
LB是FPGA内的基本逻辑单元,是FPGA可实现逻辑编程的基础,而在LB中最常用的逻辑编程器件就是查找表(LUT,Look Up Table,又称直译表),通过编程它可以实现输入与输出的直接对应关系,从而实现了输入与输出的硬逻辑,在应用时,直接根据输入的值,通过LUT给出相应的输出值。输入的组合根据输入端口数量而定,比如4个端口就可实现16种输入组合(2的4次方),而一个LB可以包含有多个LUT,实现更复杂的逻辑组合
FPGA的内部总体架构,主要是由实现硬件逻辑的逻辑块(LB)、负责LB互联的内部互联交换节点(IS)以及负责输入输出的I/O Block组成。由于几乎所有的逻辑电路都是通过不同门电路的组合来实现的,所以FPGA其实就是提供了数量众多的门电路,让用户用硬件描述语言(HDL,Hardware Description Language)自行设计它们各自的逻辑状态与相互之间的逻辑关系,从而让被编程的FPGA变成为某种专用芯片,所以说FPGA是ASIC的半成品,不无道理。
事实上,FPGA在早期的一个重要的用途就是为了更好的设计ASIC,毕竟等ASIC生产出来再实验的成本太高。而通过FPGA可以进行复杂的逻辑测试,来验证ASIC的设计,并通过可编程进行反复的优化。当逻辑优化到相当水平后,再以更为直接的逻辑实现方法形成ASIC电路,以达到更好的性能。随着FPGA自身的性能、能力与可实现逻辑的复杂度的不断提升,现在FPGA已经逐渐可以直接代替一些中等规模的ASIC来使用,并在整体功耗上,保持对CPU的明显优势。
在国内率先开发CAPI+FPGA加速卡解决方案的,恒扬科技股份有限公司大数据采集与分析产品经理张军,这样形容FPGA,“FPGA就是一张白纸,(最终的逻辑电路)想画什么完全由设计师决定,而 CPU等软件编程的器件就像铅笔画(已经有了框架),设计师是在上面涂色彩。” 事实上,FPGA可以实现怎样的能力,主要就取决于它所提供的门电路的规模。
现在主流的FPGA内部均采用了SRAM编程方式(SRAM本身就是一个逻辑部件可用于LUT,而SRAM晶体管可用于内部互联链路的选通组合),可以实现快速的硬件编程,并能无限次的重复使用。虽然SRAM的特性决定了关机后内部逻辑组合就会消失,但基于SRAM的编程在每次开机时都可以从外部的Flash芯片即时加载FPGA配置文章,加载(编程)速度为毫秒级,所以完全不影响使用。在处理性能上,由于FPGA的逻辑实现是通过硬件编程来获得,所以开发人员可以将指定的算法逻辑,直接以FPGA内部不同门电路的硬逻辑组合来实现,而且现在越来越多的FPGA内部都增加了固化的乘法器、DSP等处理单元,进一步加快了相关运算的处理速度。
从某种角度上说,FPGA内部其实并没有所谓的“计算”,最终结果几乎是“电路直给”,因此执行效率就大幅提高。当然,由于采用的是通用的门电路组合,在某些处理效率上FPGA仍然不及ASIC极致,但是可重复更新内部逻辑的灵活性,再加上在固定算法上远高于CPU的执行效率,让FPGA在应用领域迅速得到重视。然而需要指出的是,用FPGA的门电路实现整数运算逻辑,要比实现浮点运算逻辑简单得多,所以FPGA的加速优势也更多的体现在整数性运算,而整数运算正是当前主流企业级应用的主要运算方式,而这也是为什么GPGPU更多的用于浮点运算领域(如HPC),FPGA更多用于整数加速领域的一大原因。
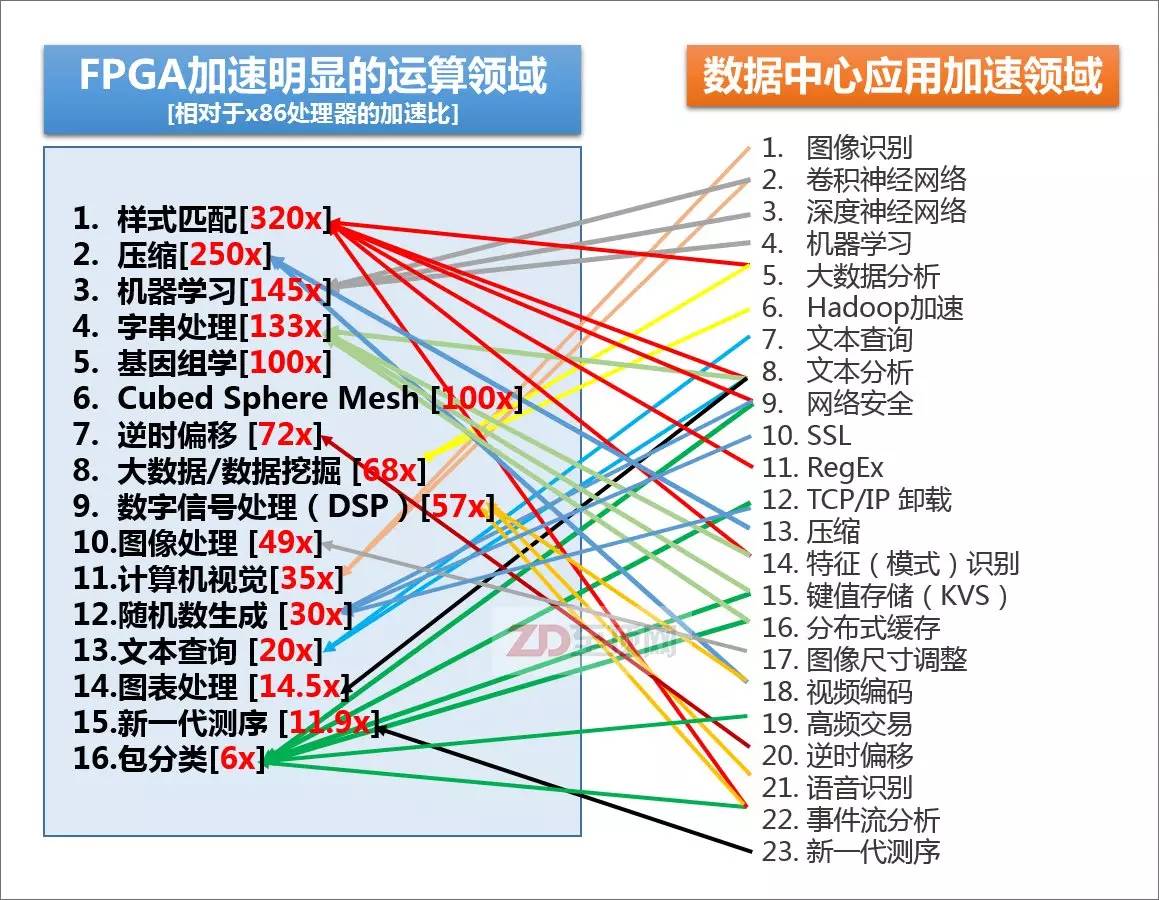
赛灵思总结的,目前FPGA相对于主流的x86处理器,在某些领域里的加速比,以及目前数据中心里可用到FPGA加速的领域,可以说80-90%的大规模并行密集应用都可以被FPGA加速,尤其是以整数型运算为主的应用,加速效果更为明显。当然,并不是说FPGA不能用于浮点运算,但相对来说,整数型加速对于FPGA更容易实现,相较GPGPU也有更明显的优势。另外,请注意很多IT基础设施的底层信息处理方面,如安全、加密、网络加速、键值存储也在FPGA的应用范畴之内,其“实用性”显然比GPGPU更为广泛
但是,传统的FPGA加速设计,均是以I/O总线与CPU平台相连,比如常见的PCIe,在系统内部以一个I/O设备存在,所以在实际的应用中,对于应用开发者本身来说仍然有较大的难度。这次CAPI的出现,则从根本上解决了这个难题,从而让FPGA的加速优势得以获得更充分的发挥。
OpenPOWER CAPI简介
OpenPOWER是以IBM、NVIDIA、Mellanox、Google、TYAN为首的5家公司,于2013年8月发起的一个技术推广联盟,截止到2015年6月,OpenPOWER会员数量超过了130家,来自于中国的厂商就超过了20家。
OpenPOWER所推广的技术就是基于IBM POWER8及以后的处理器与平台技术,这其中POWER8处理器所具备的一致性加速处理器接口(CAPI,Coherent Accelerator Processor Interface)就是一个重要的技术点,也正是它让FPGA迅速成为了新一代异构计算的亮点。
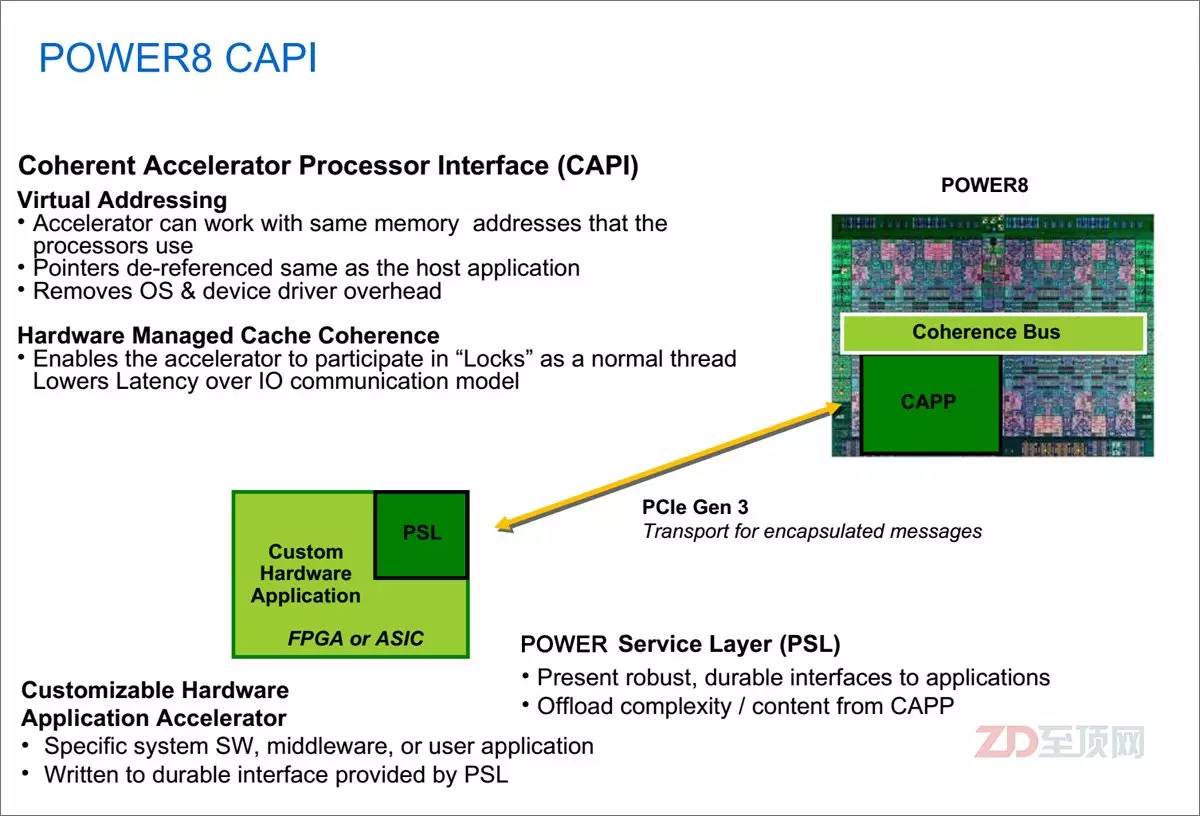
CAPI的基本原理就是通过在POWER处理器(从POWER8开始)内部设置一致性加速处理器代理(CAPP,Coherent Accelerator Processor Proxy),而在外置的加速卡上,则内置POWER处理器服务层(PSL,POWER Service Layer),其与CAPP配合,为加速卡在CPU上打通了一个“后门”。加速卡(PSL)与CPU(CAPP)之间采用成熟的PCIe总线+CAPI协议进行数据传输,但不用走复杂的PCIe I/O模式,并获得了与CPU对等访问虚拟内存地址的能力。目前POWER8内部共有两个CAPP,每个CPU可外接两个CAPI加速卡
CAPI最为关键的重点就在于一致性(Coherent),确切的说它包含两个概念,它们之间是相辅相成的。第一个就是虚拟地址空间访问的一致性,这与传统的总线地址或物理地址访问的模式有了本质的区别。虚拟地址空间访问的一致性,是CAPI加速器实现与CPU对等访问的根本体现,否则在应用编程上仍然要有较大的调整。
一致性的第二个含义就是缓存一致性,在IBM提供的PSL硬核模块(可以集成于合作伙伴的芯片,或写入FPGA)中包含有256KB的缓存,而在CPU内部,CAPP则负责维护CAPI一侧的缓存行目录,以保证CPU级的缓存一致性(CC,Cache Coherency )。这就相当于在CPU内部额外增加了一个特殊的处理核心(给CPU开了一个外挂),其对于内存的访问能力与其他“正常的”CPU核心是一致的,纳入到统一的CC体系,这就与传统的通过PCIe插卡实现加速的方式有了本质的不同。
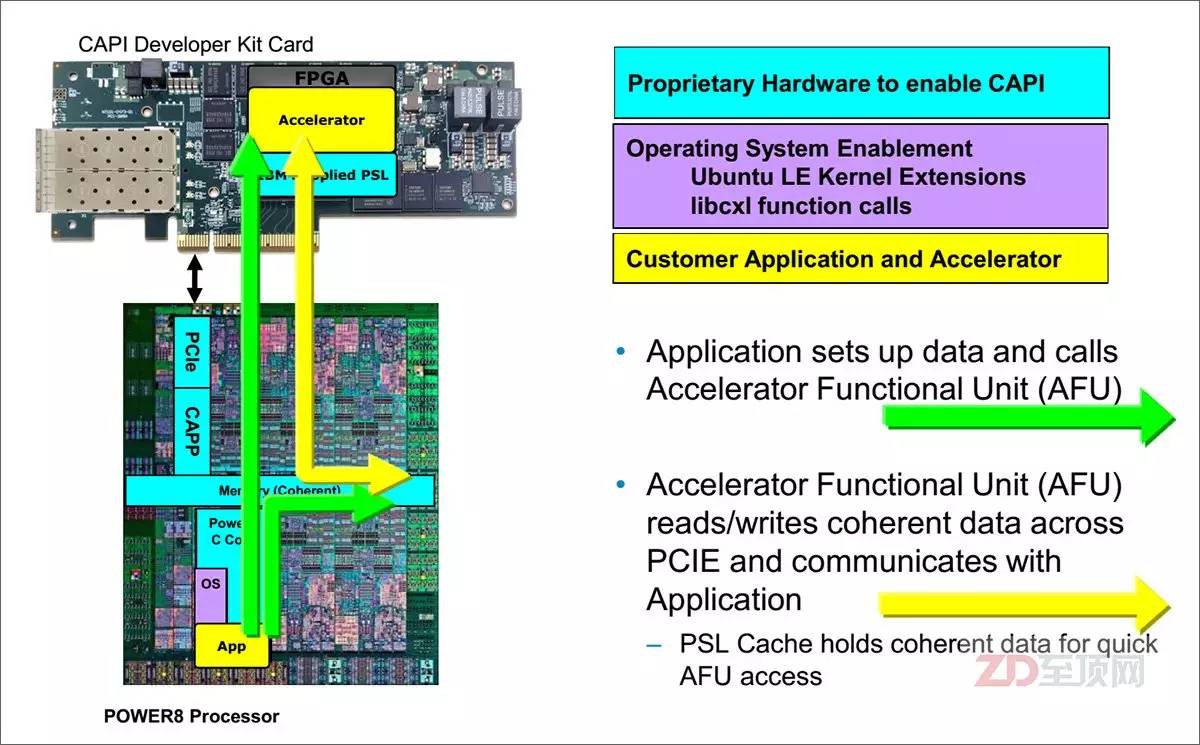
在具体的FPGA加速应用中,应用透过CAPP与PSL的连接,挂载(绑定)加速卡,PSL与CAPP一起协同,让FPGA里的加速功能单元(AFU,Accelerator Functional Unit)实现与CPU的对等访问——可直接看到应用所指向的虚拟内存地址,并通过PCIe总线与应用沟通
在CAPI+FPGA的应用中,用户先将相关应用的加速算法,以HDL(目前主要是Verilog HDL和VHDL)写入FPGA,构成加速功能单元(AFU),它就是上文提到的那个“外挂的特殊CPU核心”。然后再通过PSL与CAPP的协同,将AFU“嵌入”到CPU里,被应用发现并直接调用。AFU可以直接读写应用所管理的虚拟内存空间,以一种嵌入式的外挂处理模式实现应用的加速。从某种意义上说,“外挂”的AFU的作用有点像CPU的加速指令集(比如SSE、MMX等),但可灵活变换且效率明显更高。
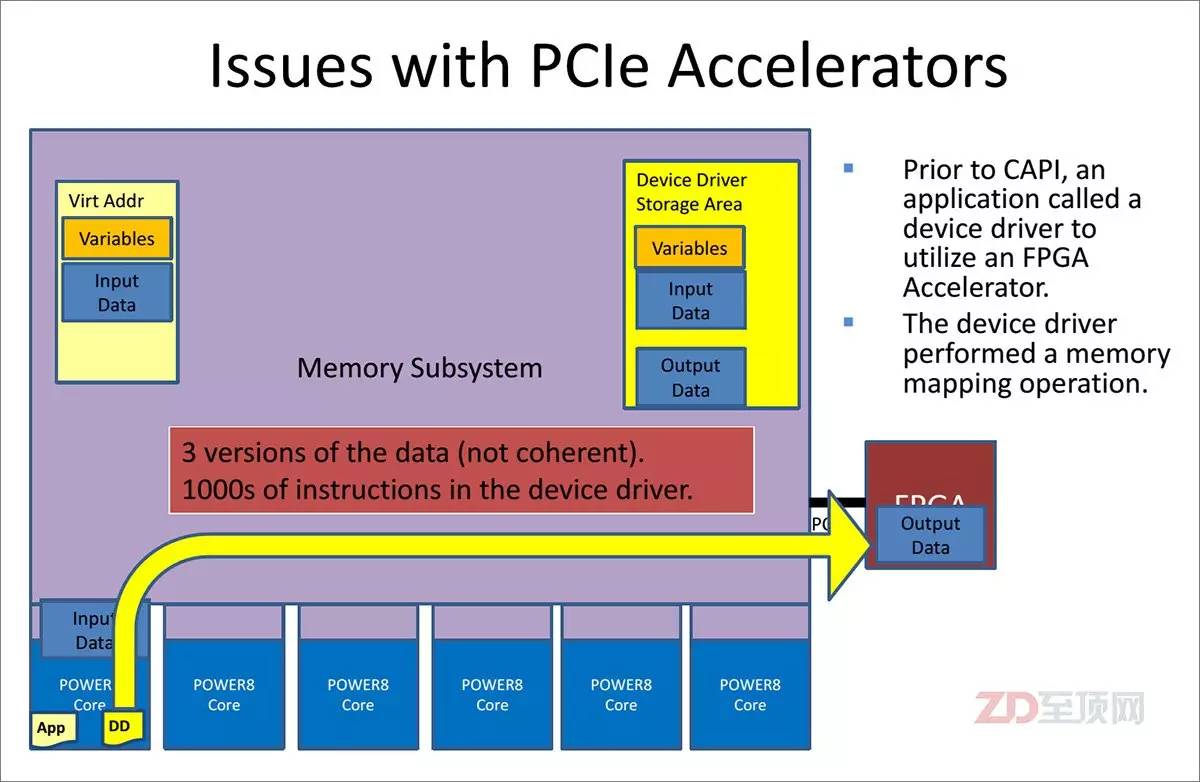
在非CAPI加速体系中,传统的加速卡是以一个I/O设备存在的,这必然需要虚拟地址的重新影射,从而在内存中会生成3个数据副本,并需要大量的驱动访问指令,后果就是延迟的增加
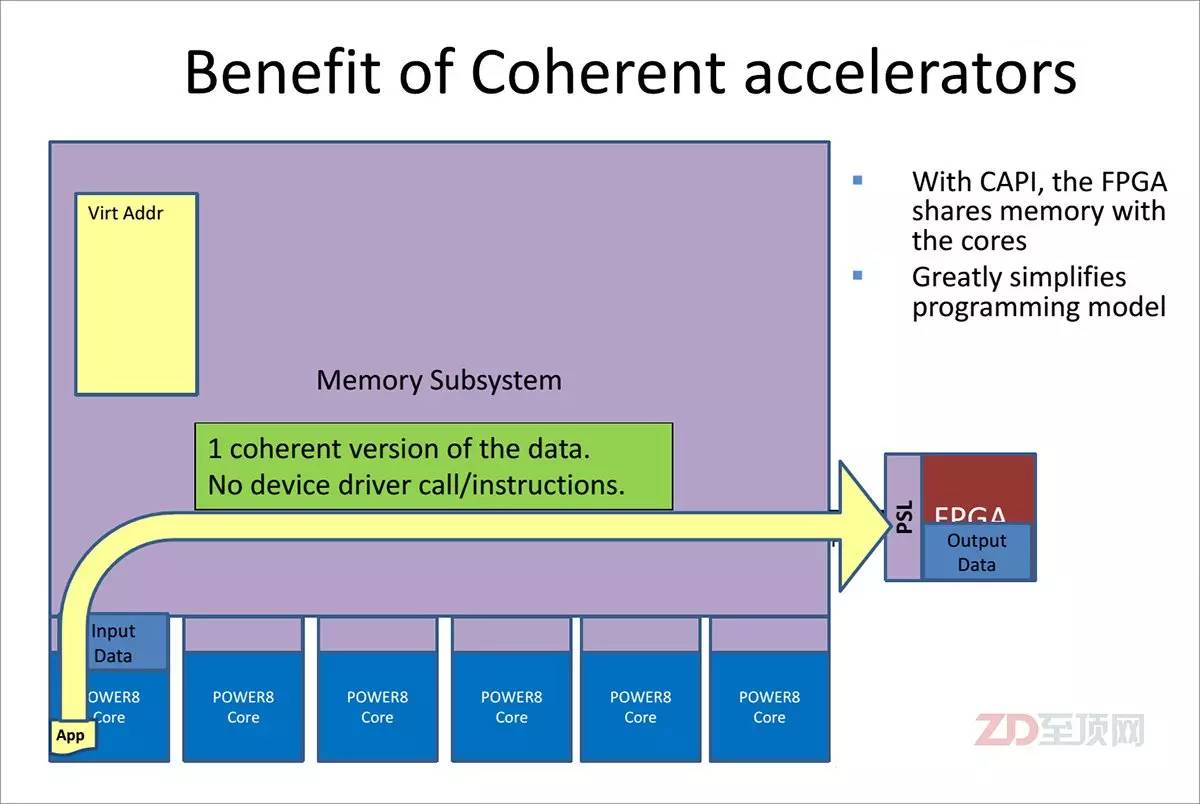
在CAPI体系下,CAPI加速器与CPU实现了对等访问,共享虚拟地址,数据无需转手,直接在加速器与应用之间进行沟通。在实际使用时也很简单,CAPI加速卡可以安装在任何提供PCIe3.0接口的OpenPOWER Linux服务器上。应用软件只需要调用一个CAPI函数,即可直接利用CAPI加速,而在对Linux更新驱动后,即可直接调用原有IM/GM等兼容接口函数
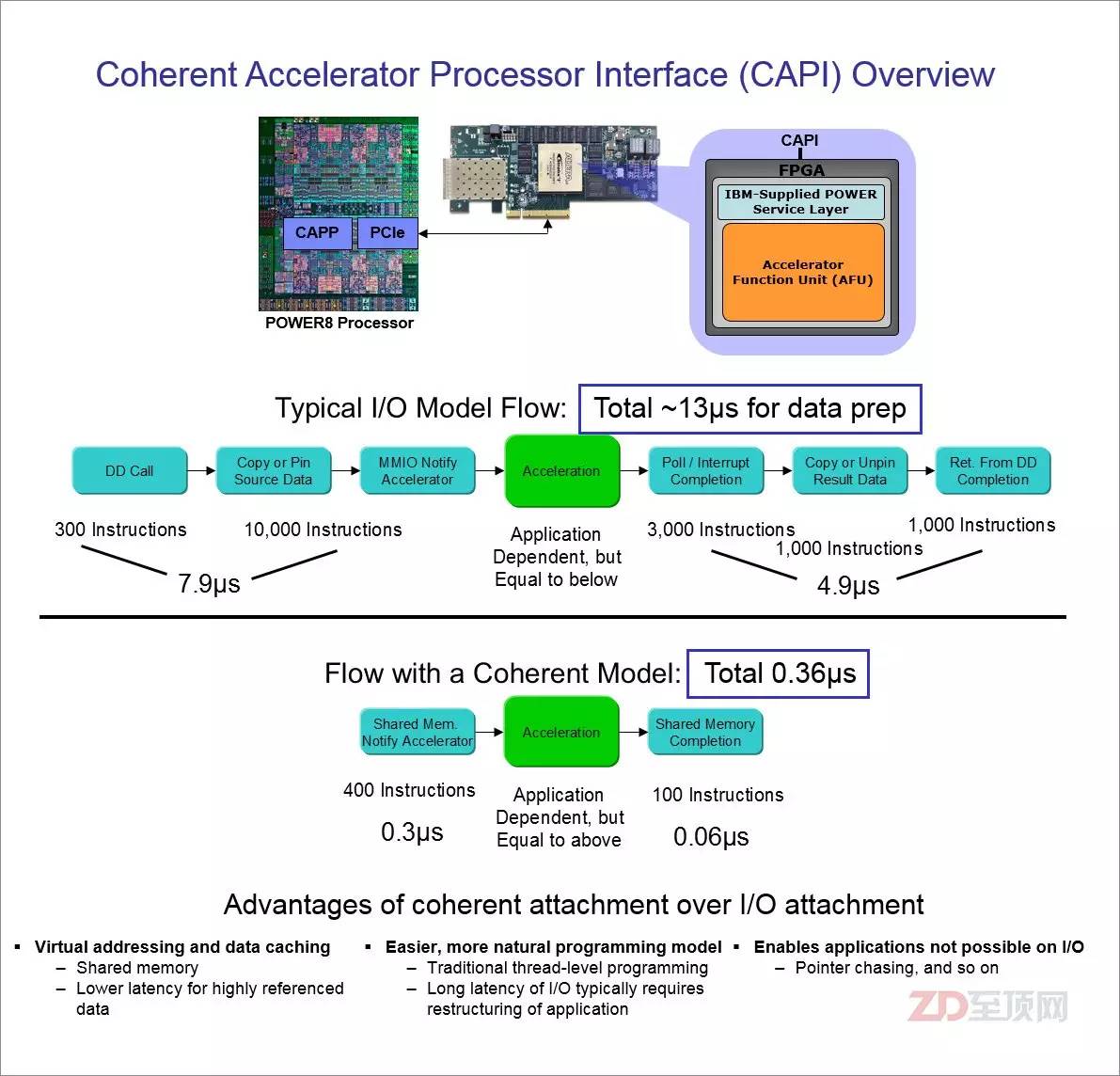
由于CAPI接口并非传统意义上的I/O驱动模式,直接走硬件代理与CPU沟通,所以从应用的全局视角,数据的访问步骤明显减少(FPGA与CPU对等访问),让数据访问效率大幅度提高,总延迟约是传统模式的1/36,同时这种应用加速设计,对于应用的编程修改影响最小
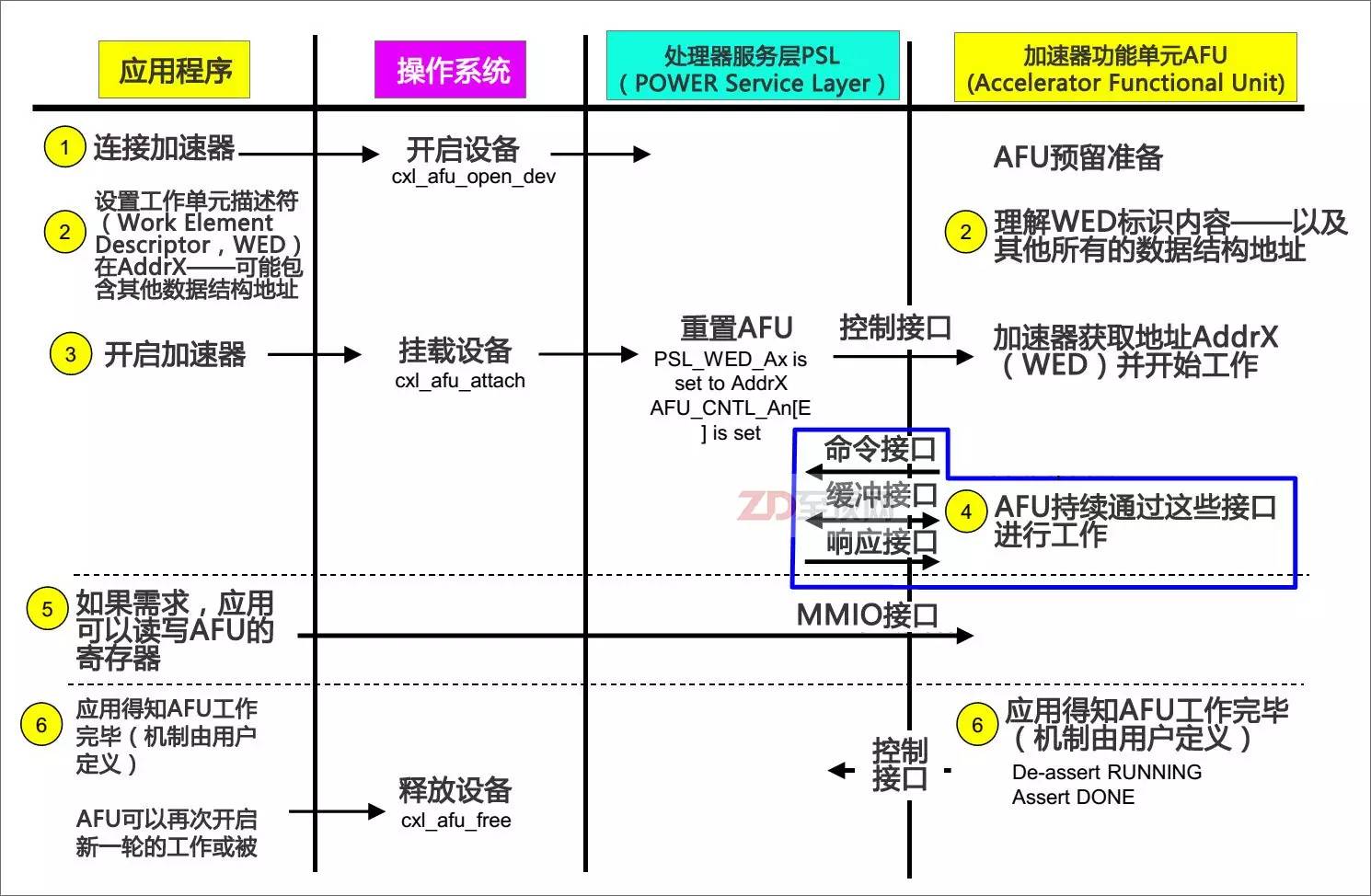
CAPI加速器从准备加速到完成加速的沟通流程相当的简洁明了,可以基本总结为——应用:CAPI加速器,我看到你了;CAPI加速器:应用,我已经为你准备好了;应用:我要处理的数据在内存地址AddrX处,剩下的工作就交给你了;CAPI加速器:好的,没问题;(开始循环加速)……CAPI加速器:报告应用,已经处理完毕;应用:好的,你先休息吧,有事我再叫你
从以上图片可以看出,由于一致性特色的加入,让CAPI加速卡避开了传统I/O设备的驱动模式,直接以“硬件代理”的方式嵌入应用的执行,因此在总体的命令开销方面有明显的减少。这直接带来的效果就是延迟大幅降低——总延迟约只有传统加速模式的1/36,并且带来了更大的好处——由于没有了传统I/O设备层,应用平台为了适配加速器的编程修改非常小,应用开发者完全可以将应用做成自适应模式,在非CAPI平台上采用传统的处理模式,当发现系统有CAPI加速器则自动打开CAPI模式,这显然非常有利于CPAI加速模式在相关应用领域里的普及。
在具体的应用环境中,目前CAPI还不能用于虚拟化平台(比如KVM),但完全支持基于Linux核心的Docker容器平台(现在的CAPI全面支持Ubuntu 14.10)。按照IBM未来的发展规划,新一代CAPI正在路上,它将基于PCIe 4.0规格(也可能会采用新的总线接口),并稍加改动,连接带宽较PCIe 4.0稍微提高,以抵销CAPI协议的开销,从而让加速器可以充分利用到PCIe的带宽。另外,CAPI的虚拟化(多个应用可以分时复用加速器)也将是必然的,融入云计算平台的统一管理也将水到渠成。并且单一PSL未来可以挂载多个AFU,在FPGA内部最多可以同时具备4个AFU,PSL分别为它们保存各自的虚拟空间地址,并与CAPP一起保持缓存一致性,这就相当于给系统同时配备了4个外挂核心。在操作系统方面,未来还将支持AIX、RedHat等OS,这将意味着除了PowerLinux平台,传统的AIX POWER服务器上的应用也将能享受到CAPI加速。
OpenPOWER CAPI+FPGA应用实战
借助于OpenPOWER联盟,很多厂商都投入到了CAPI+FPGA的加速卡设计中,中国的恒扬科技(Semptian)即是其中之一,其最新推出的Semptian NSA-120是一款基于XILINX Kintex UltraScale FPGA的CAPI PCIe板卡,采用PCIE x8 Gen3 接口规格,支持两路DDR3 1600 SODIMM(容量为2x8GB),而首先投入的AFU,是针对大数据存储中常用的纠删码(Erasure Code)的编/解码加速。
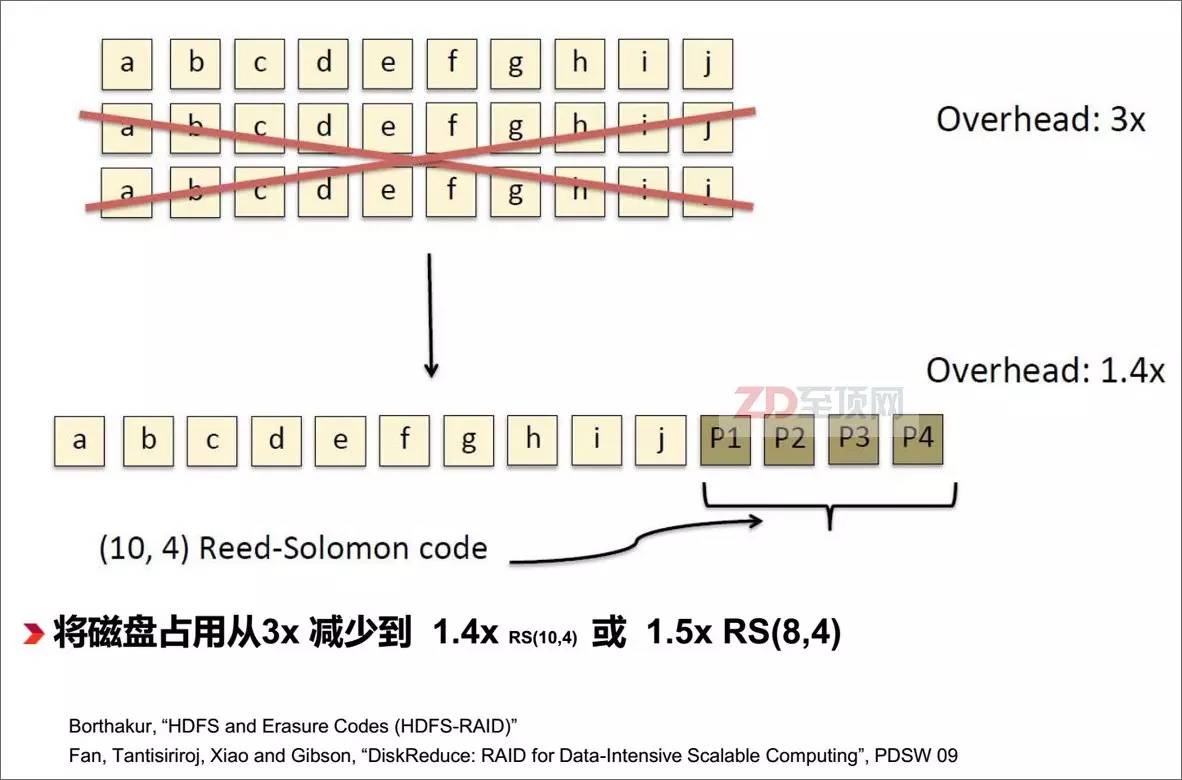
纠删码是应对降低海量分布式存储占用空间的常用手段,相对于传统的3复本冗余的存储模式(相当于3x容量占用),纠删码冗余的存储容量只相当于原数据量的1.4x,降低了超过50%的存储空间需求,但在大规模数据读写过程中,纠删码的实时编/解码运算对于服务器CPU来说将是一个比较大的占用,在分布式应用架构中,这意味着将影响应用本身的性能

通过Semptian NSA-120的加速,获得了明显的纠删码的性能提升,如果再多加一块Semptian NSA-120(双CPU配置时最多可插4块),性能还会加倍提高
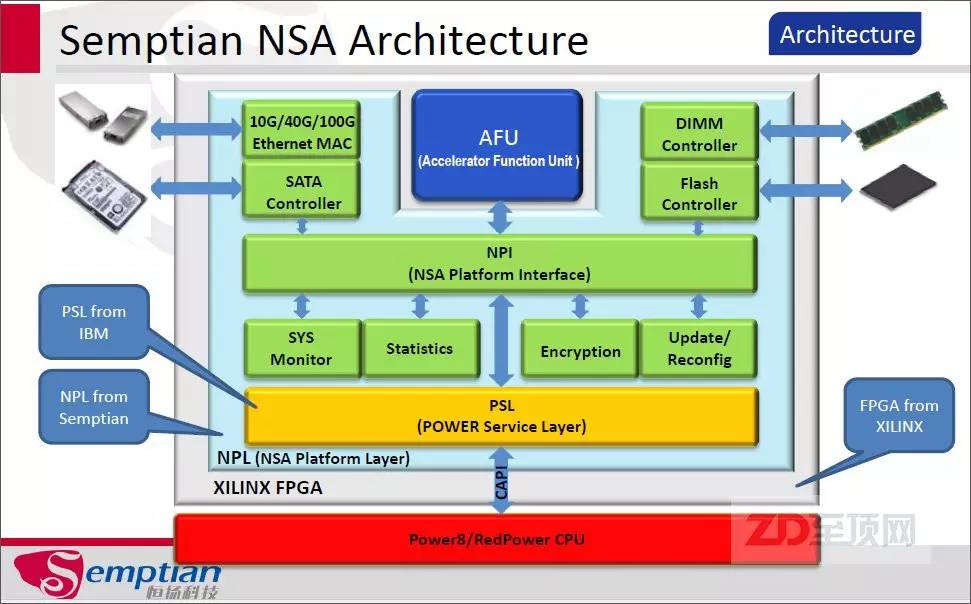
为了进一步方便ISV与AFU的开发者,恒扬科技专门提供了NPL(NSA Platform Layer),即FPGA基础平台,帮助AFU开发者硬件无感知的开发AFU算法单元
根据恒扬科技大数据采集与分析产品经理张军的介绍,目前FPGA的编程环境已经有了很大的改善,这其中OpenCL开发平台的发展起到了重要的推进作用。虽然现在仍然很初级,但对于传统的应用开发者来说,借助OpenCL开放的标准化平台,已经可以相对较为容易的上手,而在底层编程部分,仍然会通过FPGA厂商的专用工具进行HDL编译,再写入FPGA。此外,FPGA厂商也在像NVIDIA那样,提供自己的集成开发环境(IDE),它的作用相当于CUDA之于GPGPU,为开发者提供更完整的工具包,加速FPGA的编程。比如赛灵思的 SDAccel开发环境,就可为赛灵思的FPGA加速OpenCL、C和C++内核的开发与部署。相应的CAPI-FPGA加速卡厂商,也会提供底层平台,方便开发者基于自己的板卡进行AFU开发。比如恒扬科技就提供了NPL和相关的SDK,可以让开发者专心于AFU的算法实现。
另一个典型的CAPI加速实例则是外置存储加速,IBM基于CAPI控制卡+自己的FlashSystem全闪存阵列,提供了一套NoSQL数据引擎,由于CAPI将传统的PCIe控制卡的I/O开销省去,大大降低了系统延迟,成为KVS数据平台更好的选择。
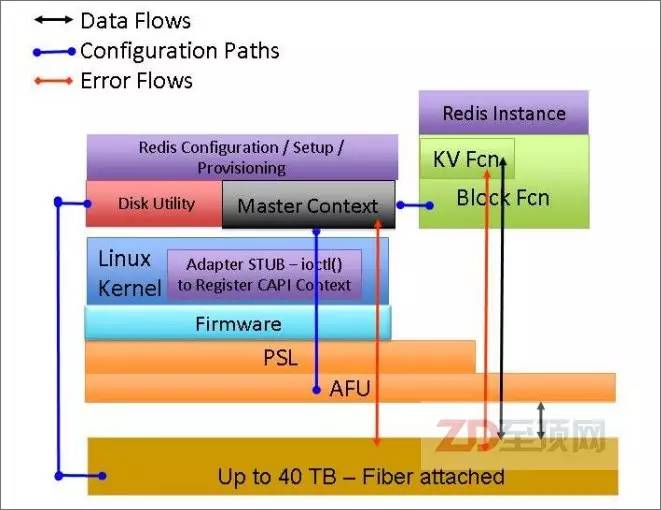
IBM基于支持CAPI+全闪存阵列而推出NoSQL数据加速引擎,配套全闪存阵列可以通过CAPI加速卡直接访问应用内存空间,大大降低了数据传输的延迟,非常有利于单笔数据访问量少,但IO密集的键值存储(KVS,Key-Value Store)平台

通过与非CAPI控制卡连接的性能相对比,可以看出由于CAPI连接不是传统的I/O驱动模式,而近似于CPU直联,所以在IOPS性能与延迟性能上较传统的PCIe控制卡有明显的提升,不过如果是大数据块传输,CAPI控制卡在总带宽上可能会有一定劣势,但到下一代CAPI这将不再是问题
第二代异构计算与未来应用愿景
如果说以GPGPU为主,大幅度提高系统浮点运算能力是第一代异构加速计算的典型特征的话,我们现在可以基本总结出以FPGA为主,所谓的第二代异构计算的一些重要特征:第一:具备缓存一致性和对等的内存访问能力,这是最为重要的特征,与第一代异构计算有了本质的不同,并对应用编程具备了明显的友好性;第二:基于FPGA可灵活配置加速模块,毫无疑问,在第二代异构计算中,FPGA将是一大主角,它本身灵活的可编程性为应用加速提供了丰富的应用场景;第三、它将隆重开启整数运算加速的大门,随着FPGA编程的便利性进一步提高,FPGA的整数型加速将会迅速普及(当然绝不是说FPGA不能用于浮点加速,只是看应用比例),这对于当前的大数据、海量视频处理、图像匹配等新兴需求不谋而合,就像当初GPGPU与科学计算的发展相得益彰一样,第二代异构计算将把相应的整数型应用的性能带到新的高度。
当然,看到这一趋势的不仅仅是IBM与OpenPOWER,CPU巨头英特尔以167亿美元收购FPGA第二大厂Altera的用意也不言自明。在不久前结束的IDF15上(英特尔信息技术峰会2015美国站),英特尔正式发布了CPU通过QPI直联FPGA的方案设计。
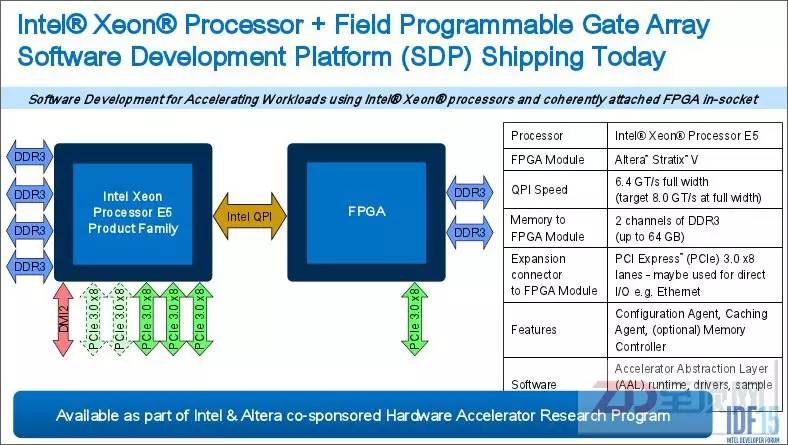
采用QPI接口与CPU互联,明摆着是冲着缓存一致性而来,这与CAPI的思路异曲同工,并且在服务器的配置上给出了新的可能(比如FPGA芯片Socket化或直接板载),这与CAPI有了明显的不同,可谓各有利弊,但共同点都是开启了第二代异构计算的时代
当越来越多的FPGA加速芯片以各种缓存一致性的方式接入系统之后,由于FPGA的SRAM高速编程模式,理论上讲FPGA可以迅速的且无限次的更新内置的AFU,以应对不同的应用加速需求。这就给我们打开了一个想像空间——能否像Docker管理容器镜像那样,基于云+端的概念建立起一个AFU镜像的集散中心呢?事实上,OpenPOWER联盟已经在这么做了——建立AFU镜像商店,并已经落户SuperVessel Cloud(超能云)之上,目前已经有多个AUF镜像可用选择( https://crl.ptopenlab.com:8800/acceleration )。
OpenPOWER CAPI-FPGA加速卡AFU镜像商店的更新流程(笔者猜想绘制,谨供参考)
届时,任何相关的开发者、ISV都可以将自己针对某些具体的FPGA卡(经CAPI认证)所编写的AFU镜像(其实就是FPGA的编程配置文件),上传至AFU商店供其他用户免费或有偿使用。相关的AFU用户则可以像Docker那样,根据自己应用加速的需求与FPGA加速卡的型号,免费或付费下载相应的AFU镜像,通过全局的管理平台,分发给指定服务器上的CAPI更新控制器,由后者与指定的FPGA加速卡(一台服务器可以有多块加速卡,选择更新)PSL内的AFU更新模块一起加载AFU镜像。加载的方式有两种,一种是完整的FPGA重写(所有的门电路重写,包括PSL),另一种则是AFU单独更新。前者需要重起服务器,而后者则可以在线动态更新。目前100万门的FPGA的完整配置文件容量也就在50MB左右,由于是基于SRAM的硬件编程,100ms内即可更新完毕,用户几乎没有察觉,但服务器的加速功能就已经完全改变了。
我们可以试想一下这样的场景,对于某个内置CAPI+FPGA加速器的服务器集群,可以灵活的根据工作负载的需求改变FPGA中的AFU模块,让这个集群迅速具备针对新负载的加速能力,这对于集群高效的多场景灵活复用显然是很有帮助的,而这种模式也是GPGPU、DSP、ASIC等加速方式很难做到的。
展望未来,从某种角度上讲,GPGPU与FPGA在未来的应用系统中,将根据自身的特长有所侧重。如果将CPU比作人的话,GPGPU更像是高级计算器,为人类提供强大的科学计算的能力,做好学术研究,而FPGA更像是为某类工作定制的效率工具,执行大量固定而高度重复化的工作,大幅度提高人类的日常生活与工作效率(比如洗衣机、生产机器人),而人在未来更多的就是负责管理,用好计算器与效率工具——CPU的角色相信也会如此,随着技术的不断发展,更多的浮点与整数运算任务将会被GPGPU、FPGA、DSP、ASIC等不同的加速器所分担。
进化至第二代分布式计算?
基于上文所分析的CAPI+FPGA所展现出来的能力,如果我们进一步从单服务器延展至整个分布式计算的架构,就可以从一个更为广阔的全局视角来分析第二代异构计算所带来的关键影响。不久前,IBM提出的“第二代分布式计算”理念也正是基于这一全局的层次来建立的(据说在9月16日会召开发布会进行专门的阐述 )。
IBM中国研究院的高级研究员陈飞表示,IBM提出的第二代分布式计算有四个重要的特征,第一个特征:加速器的软硬件接口有统一的接口规范,以便于更好的协同管理与普适(第一代分布式计算的接口标准较为统一,毕竟只有CPU本身,相对更标准化),这方面CAPI就是一个标准化接口的尝试。第二个特征:加速器可以动态地在线发现以及加载。比如不需要系统的重启,但现在的加速器如果要改变功能,一般都要要求重启,或者是重启一些软件服务,但CAPI+FPGA则没有这个顾虑。第三个特征:分布式的系统要具备全局异构资源的调度能力,也就是说它能决定应用是运行在一个具有加速器的计算节点上,还是跑在一个普通的纯CPU的计算节点上。第四个特征:应该软件本身,具备兼容CPU运行模式和异构硬件运行模式的能力。

NVIDIA推出NVLINK互联总线,除了可作为GPU之间的互联外,还可用于CPU与GPU的互联,并也将具备缓存一致性的内存访问能力。IBM的POWER9处理器(预计2017年下半年发布)将具备这一接口,这就意味着在POWER9平台上NVIDIA的GPU也会获得与CAPI同样的对等访问能力,这样的GPGPU加速能力也将是POWER9独有的(在英特尔x86平台上,与CPU的互联连接仍然是传统的PCIe模式,NVLINK仅用于NVIDIA GPU之间的互联),对IBM所提出的第二代分布式计算理念无疑是一个有力支撑
从以上定义中,我们可以看出,正是CAPI+FPGA所具备的一些关键特性(缓存一致性、在线更新性、AFU替换能力等)为IBM所提出的第二代分布式计算打下了理论基础。当然,对于这个定义,我仍然有一些异议,毕竟从总体上讲,这个分布式处理的基础架构与应用分布处理的模式,和第一代相比并没有本质的不同,更多是分布式节点上处理模式的创新,并且由于加速体系标准的更加多样化,也让其普适性受到怀疑,除非有非常强大的全局管理平台来屏蔽掉底层的硬件差异性,否则全局上的“加速孤岛”现象不可避免(虽然对于具体的用户来说,这可能不是问题)。
但是不管怎样,第二代异构计算的模式,的确打开了我们的想像空间,它是否真的带来理想中的第二代分布式计算体系,还有赖于IBM、英特尔以及加速器、方案集成等前沿厂商的共同努力!不过,可以肯定的是,不管这种新兴的处理模式将如何称谓,它对于新时代下的信息处理平台(大数据分析、物联网、人工智能、机器学习等)所带来的明显帮助,以及为最终用户所创造的巨大价值,都将是毋庸置疑的!
-
【一文看懂】什么是异构计算?2024-12-04 3850
-
异构计算在人工智能什么作用?2019-08-07 3605
-
什么是异构并行计算2021-07-19 2166
-
异构计算的前世今生2021-12-26 3241
-
异构计算芯片的机遇与挑战2017-09-27 1425
-
异构计算的两大派别 为什么需要异构计算?2018-04-28 23453
-
异构计算,你准备好了么?2018-09-25 685
-
揭秘赛灵思计算平台ACAP技术细节2021-01-04 4089
-
异构平台设计方法 探索赛灵思Versal ACAP设计方法论2022-08-02 1319
全部0条评论

快来发表一下你的评论吧 !
