

赛灵思视角下的未来
描述
未来的世界什么样?
三维重构音乐会
很多人喜欢“维也纳新年音乐会”。我们可以看到这两年的音乐会现场有很多人拿着移动设备在拍摄。如果,这些信息都传输到云端会怎样呢?例如,我们可以在云端利用这些不同角度拍摄的视频重构出一个三维(3D) 的虚拟现场,那么你可以用你的鼠标在任意角度飞行,一直飞到演奏的小提琴手那去,去看它的演奏视频。比现场观众还清晰。
戴着Google眼镜观看比赛
巨大的体育场里面坐满了观众,很多人戴着Google眼镜,每个人的眼睛都在看着球场,当然,如场景1一样,你可以三维重构球场。但我们可以更进一步,观众希望通过Google眼镜看到正在跑动的运动员的更多信息,诸如他的力量值、体力值、经验、姓名,以及他刚刚射门,射门的总次数,这些都可以实时地在这个人的体像上进行叠加。
这些就是今后业界准备做的事情的一部分。我们的教学和科研就是为这一天的到来而准备的,而且一定要很快地到那个点去。那么这个点是什么呢?
关键的1ms:一个智能交通的场景
现代电子信息技术可以提供什么服务? 例如1秒钟(s)可敲击一次键盘;100ms可以听音乐;10ms可以看视频;如果是1ms呢?
1ms 就是你的神经和力量的控制时间,比如你用手碰到电风扇,手会马上缩回来,这个反应速度是1ms。所以我们接下来要做的,就是能够在1ms时间内做的事情。
举个简单的例子,如果我们通过网络的云计算在1ms之内做出决策,应用在我们的汽车上,汽车可以在没有红绿灯的情况下,用无线方式互相通讯,如果车快撞上,用1ms的时间刹车或马上加速,这就是无人驾驶汽车。如果有行人,由于行人有手机(or 其他可穿戴设备),手机会发出信号,汽车开过来时就会自动减速,让行人走过去。这是一个无损的理想应用,也就是所谓的未来的智能交通。
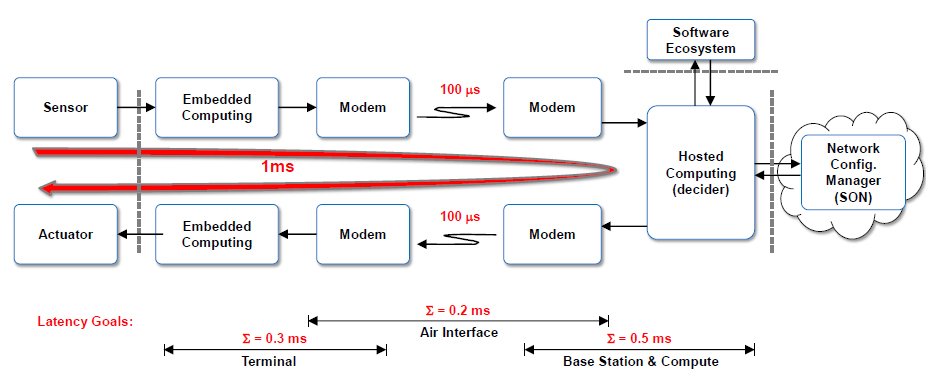
这样的场景里面有一个很关键的问题,那就是1ms的问题。这个智能交通系统要在1ms的时间内完成数据的采集、处理、判断和控制。
我们用云来处理和进行控制,那么汽车在上海,就不能用放在北京的云来提供智能服务。因为光一秒钟也就跑三十万公里,1ms光能跑300公里,还要考虑打个来回,即150公里,也就相当于上海到无锡的距离。所以在设计无线接入网的时候,云计算必须是一个分布式的云,应该到处都有,物理上应该是像基站一样普遍存在。
上述仅仅是光在路程上的时间。其实计算的任务也很繁重(图1),因为你要做嵌入式计算,要进行图像、视频等的处理,还要调制解调、加密、软件、可靠性,所以每个阶段只有零点几毫秒的预算了。因此业界的另一挑战是大量的数据要实时地在零点几毫秒内做完。
CPS(信息物理系统)
我本人不太喜欢物联网(IoT)这个词,因为它暗示只要把传感器像互联网一样连起来,收集数据,这事就结了。实际上你得到了一大堆数据是没用的,真正有用的是拿到数据之后,还要反馈回来做控制。所以我更喜欢CPS(Cyber Physical System)这个词,即信息物理系统,意思是要把物理系统能够与信息系统结合到一起,形成一个闭环,能够让信息系统影响物理系统。实际上我国说的信息化改造工业化也是这个意思。
摩尔定律难以解决性能和功耗问题
为什么后十年我们做得到呢?来看看微电子业的摩尔定律。摩尔定律不停地发展,现在已经到20纳米,未来的路线图已到3.5纳米。摩尔定律要解决什么样的问题呢?就是漏电问题。像水管一样,一个开关如果关得不牢,就要漏水,如果一个晶体管设计得不好,它就会漏电。现在“水龙头”越做越薄,一定会有“漏水”现象,整个工业界正在做的就是如何把开关关紧。

现在用体硅和绝缘体上硅(SOI)(图2),还有FinFet(鳍式)、SOI FinFet,最后是全包围,来把电流夹断。插个广告,目前Xilinx在20纳米节点,很快会推出14/16纳米芯片。摩尔定律在今后至少十年还是适用的,所以在器件方面,我们不用太着急。
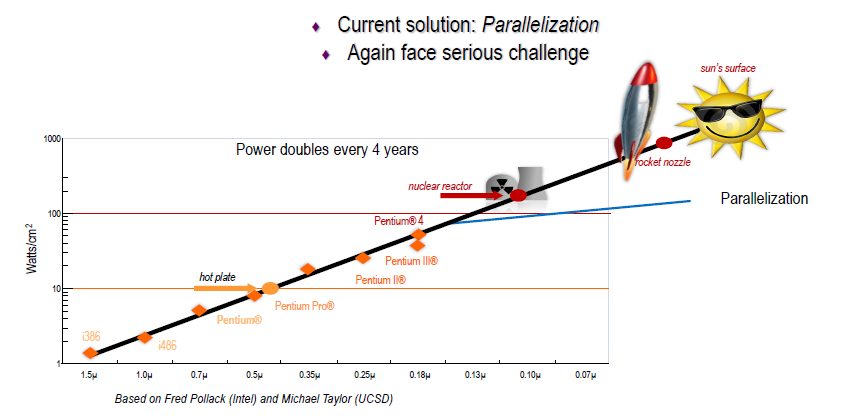
但是摩尔定律每年指望它性能翻番遇到了严峻的挑战。不是说摩尔定律有了,跟着它每年就自动获得计算能力,这件事过去是这样的,但是最近行不通了。整个业界面临着两个挑战,一个叫性能,一个叫功耗。
现在一个芯片里面可以集成越来越多的晶体管,可是晶体管如果都工作起来,消耗的电流特别大,大到最后你如果按照这个曲线走的话(如图3),单位面积上的功耗会超过核电站的功耗,甚至是火箭、太阳表面的功耗,因此芯片会烧坏,所以真正工作的时候,芯片上有一些晶体管要处于断电状态,这就是所谓的暗硅(Dark Silicon)。既然如此,那就用多核。这是不得已而为之的办法。但是如果我还想得到非常高的运算能力——1ms要做很多很多事情的——但是,我又不能把所有的晶体管全打开,是不是就矛盾了,没办法解决了?那我们试试看?
大脑的启示
一个好消息是晶体管现在已经不值钱了,也就是说既然一块芯片里一定会有晶体管不开,我们就一定要大大地放纵我们的设计空间,我们宁肯用一大堆冗余的计算单元提前摆在那,用其中一部分工作,其它的都不用。这件事是对的。因为在生活中就有一种“计算机” 实际上就是这么干的,就是人的大脑。人脑的皮层90%是没用的,真正工作的只有其中一小部分。
我们再回过来看目前的情况,CPU很有意思,它一天到晚都没在干正事,都在弄流水线,最后干了一件事啥事?就是做了一个加法。也就是说百分之七八十的硅片都在为了满足这一个高速运行的累加器,给它喂饱,喂饱这个累加器有好多分支预测,什么乱七八糟的读Cache(高速缓存),就是为了搞高速运算的一个单CPU。这件事情很不合逻辑,我用了这么多硅片,折腾了这么半天,最后就算了个加法!原来,当初冯.诺依曼设计计算机的时候,晶体管和ALU(算数逻辑单元)很贵,因此利用便宜的memory是很划算的。冯.诺依曼计算机就这么一路走过来,大家也跟着吭哧哼哧地推一步走一步,也不想创新,CPU不停地增加它的时钟频率,结果到今天再怎么做也难以翻番了。
所以有人提出,最好把这套东西全推掉,我全都弄上运算单元,这些运算单元可根据计算的任务随意组合,马上就能做运算,动态组合、动态植入,那么整个面积都是运算单元在做事。这件事情实际上就是我们人类大脑干的活儿。人类的大脑实际上是一个并行的计算机。前段时间,IBM刚发表一个消息,说是做了一个人工神经元的超级计算机,最核心的特点就是其神经元可以动态存储,也就是说不同的信息他训练两天之后,它就连接成一个可操作的部分,而且功耗特别低。
我们在做什么?
没有处理器,还要做计算
因此,我们要做什么事呢?Computing without Processors(没有处理器,还要做计算),这就是我们今后十年或许能够应对挑战的法宝。也就是说我们能够通过硬件的可重组、可重构,能够在硬件层面重组出来正好适合计算的能力。我们不需要再为流水线、cache发愁了。
Xilinx有个Vivado-HLS工具,可从C实现FPGA。你可先做一些低层次的东西,就是所谓的HLS,Vivado-HLS能把算法直接变成硬件实现,也就说你的计算单元已经没有CPU了,但又是高效的。如果你嫌烦的话,可以用碎片来做,然后就被大量地收集了,然后它做线上的工具。
假设Xilinx的Zynq处理器就是大脑,有一大堆单元,你什么都想干,但是嫌设计太麻烦了,ultrascale构架把你要用的东西准备好,CPU有了,加密引擎一大堆,你要一百个,还是一万个加密引擎都行,还有浮点运算单元,你想要什么图形引擎(GPU),我给你放上三万个GPU进去,你再用可编程的逻辑把它们连到一起,满足你的需求。这个方案功耗既低,速度又快,还全是硬的东西,为什么?因为晶体管太便宜了,而且我做了一大堆,功能全放那儿,你想用哪一个都行,这就是Xilinx在做的。
当然在这上面,编程就是一项挑战了。异构计算一定是今后我们要掌握的,这样才能够为后面的事做准备。异构计算,Xilinx首推的是用OpenCL来做,因为它一次编程,你可以在PC机上跑,也可以再把它编程,也可以在CUP上跑,在任何地方跑,而且数量不限。其核心思想就是异构计算,它不是一个fancy(幻想)、要跟踪潮流的东西,而是我们如果不应用它,大家认为很难持续。Xilinx的Zynq目前是双核的,可能下一代还有更多核,有一万个加密单元,都是硬核的,让你在里面动态组合。
对大数据来讲,应该让分布式的存储用起来和RAM一样是随机地存储,也就是数据库我们一定要做得跟RAM一样。怎么做?如果还按照筛选,我要在1ms内把一大堆数据放到一起筛选,一个方法就是在它的所谓的控制器里再加上过滤逻辑,这样,我读写数据的时候,就可以把我的智能放进去,在网络上用传统的数据就可以实现你的功能。
小结
异构、多核、一大堆晶体管,在1ms内要完成大量计算,这是今后业界要面对的事。
这听起来很困难,似乎要很多的知识,什么硬件、软件知识,大家很发怵,认为跟踪该技术太艰难了。其实不难,我自己十多年没写Code,我专门试一下,我利用在火车、飞机上的时间看一看Zynq和Vivado的书和文档,后来做了实验,也差不多会做了。现在我们的课程,在中山大学珠海分校,用五天的时间教大学本科三年级的学生,让他们能够在短时间内掌握Zynq。实际上,Zynq和Vivado没什么了不起,只是工具而已。
---> END <---
全部0条评论

快来发表一下你的评论吧 !
