

基于XuperChain提出的一种智能合约并行执行区块链结构解析
区块链
描述
近年来,区块链技术不仅仅在加密货币交易,而且在存证和商品溯源等领域发挥着重要而广泛的作用。然而,许多现有的区块链系统在执行智能合约方面表现不佳,无法满足业务需求,因为智能合约是串行执行的。XuperChain是一个新的区块链系统,它能够支持智能合约在交易粒度并行地执行和验证。
引言
2009年中本聪(Satoshi Nakamoto)发明了比特币,这是区块链技术首次大规模成功应用。2014年,Vitalik Buterin发明了以太坊。与比特币相比,以太坊支持智能合约,允许开发者使用基于区块链的Solidity语言开发应用程序。2015,Linux基金会推出了超级账本,它允许开发人员使用流行的语言如GO开发智能合约。这些系统在实际使用时性能表现的一般。本质上,是由于智能合约是串行执行和串行验证的,也就是说,对于单个节点,只能使用一个CPU核。XuperChain提出了一种新的区块链数据模型:XuperModel。基于这样的底层数据模型,XuperChain可以使用多核计算能力来同时执行和验证智能合约。
智能合约的性能问题
在以太坊中,矿工首先从交易池中提取一组有序事务,然后在一系列事务中执行智能合约调用,最后将它们打包成块。接收该区块的验证节点还需要根据区块内的交易顺序逐一执行智能合约,这与之前对矿工进行打包的顺序相同,验证节点和矿工执行的结果应该相同。
显然,智能合约的串行执行模式限制了区块链系统的性能提升,因为串行执行模式不能充分利用多核的计算能力。
Hyperledger Fabric提出了一种方法,其中智能合约首先在多个背书节点上执行,以获得读写集和背书节点的签名。然后,排序节点对事务进行排序,并将它们打包到链上。这种方法的优点是,有些事务执行可以完全并行,但也有一些局限性:未确认事务的输出不立即可见,新事务的读依赖性只能是BlockChain中的已确认事务。这使得合约从调用到数据变更生效有较大的延时。
XuperChain让智能合约执行并行化
1 架构概述
XuperChain 事务执行架构主要由三个部分组成,分别为VM层、Bridge层和Model层。 VM层主要用于解释用户执行合同的字节码,目前主要支持的有wasm、native。Bridge 层用于隔离用户态和内核态,为用户提供系统调用的接口,如get、put、迭代器等。Model层用于数据的提交、回滚和查询,其内置的smart cache机制能支持事务的并发执行。

整个过程是这样的。阶段1:首先,客户端触发智能合约的预执行,智能合约的字节码由虚拟机解析执行,执行过程中的get、put等系统调用被Bridge层截获,Bridge层将记录执行过程中的读写集,最后返回给客户端。阶段2:客户端使用读写集组装事务,并附加其签名,然后将其提交到Model层。Model层将验证读取集的有效性和正确性,最后将其写入数据库中。
2 XuperModel
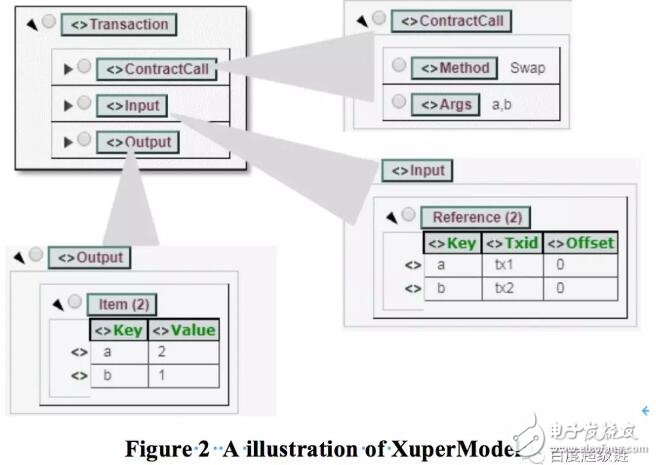
为了描述读写集,XuperChain定义了一个名为XuperModel的新的事务模型。该模型是比特币UTXO模型的一个演变。在比特币的UTXO模型中,每个交易都需要在输入字段中引用早期交易的输出,以证明资金来源。同样,在XuperModel中,每个事务读取的数据需要引用早先的事务写入的数据。在XuperModel中,事务的输入表示在执行智能合约期间读取的数据源,即数据来自哪些事务的输出。事务的输出表示事务写入状态数据库的数据,而这些数据会被后续的合约调用所引用。
为了进一步说明XuperModel,考虑两个事务:tx1和tx2,其中tx1给变量a赋值1,tx2给变量b赋值2。然后还有第三个事务tx3,它调用一个合约来交换两个变量的值,最后它的输出是a=2和b=1,交换两个变量。因此,在tx3的输入中,它将引用tx1和tx2,因为前面的值是由tx1和tx2所修改的,如下图所示:
3 XuperModel 的智能缓存
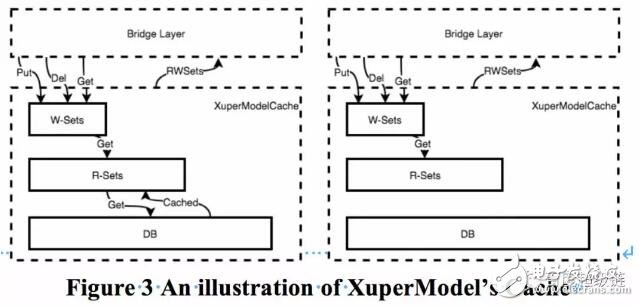
为了在运行时获取合约的读写集,在预执行每个合约时为其分配一个智能缓存。该缓存对状态数据库是只读的,它可以为合约的预执行生成读写集和结果。同时,也可用于合约的验证。该缓存由四部分组成:一个写集合实例、一个读集合实例、一个Model实例的引用和一个穿透的标志,标记查询是否可以穿透到Model实例中。
在合约预执行时,穿透标志设置为True,Bridge为合同获取该Cache,通过缓存可以读取到DB中的数据,查询到的数据将缓存在Cache的读集中。此外,合约可以写入数据,写入数据将在Cache的写集中生效。在预执行之后,读写集可以被提取到并且一起并返回给客户端。
验证合约时,是否穿透的标志为false,验证节点根据提交的事务的读写集一个新的Cache实例,如果事务中所引用的版本已经过期,则事务直接失败。若版本都有效,节点将再次执行合约,但此时合约只能从读取集读取数据。同样,写入数据也只会在写入集中生效。
为了进一步说明该Cache,考虑一次合约调用。XuperChain通过发起事务来调用合同。在预执行合约时,Cache是一个三级的存储对象。假设合约调用get操作,则Cache将首先从写集读取最新数据,如果未找到,则从读集中读取,如果未找到,则从DB读取。在验证合约时,Cache是两级存储对象。假设验证get操作,Cache将首先从写集读取最新数据,如果找不到,则从读集合中读取。
4 事务冲突处理
前面提到Cache可以提取智能合约预执行生成的读写集,这是事务提交时重要的组成部分。在XuperChain中,读写集由读集和写集组成。其中,读集由元组组成:变量名,数据版本,反映了合同运行时读取的变量状态,写集为元组:变量名,数据值,表示合同执行后对状态数据库的更改。
数据版本是一个元组:{ref_txid,ref_offset},表示修改变量的最后一个事务的ID和事务的输出偏移量。Hyperledger结构[3]中的数据版本也是一个元组,但其版本由{blockheight、txnumber}组成,因此无法支持未确认事务输出的即时可用性。显然,XuperChain的设计可以支持更低的延迟。
当节点接收到一个事务时,会首先构造一个临时Cache,并用事务携带的读写集填充该缓存,执行合约,验证智能合约执行的结果是否正确。通过此检查后,将验证读写集中变量的版本是否与本地状态数据库中记录的版本一致,如果不一致,则拒绝事务。值得注意的是,XuperChain要求写入集中存在的所有变量名必须在读取集中给出相应的数据版本,如果变量之前没有值,则版本字段应保留为空。此外,如果本地未确认事务池中的事务与块中的已确认事务之间存在读写集冲突,则将回滚未确认事务。回滚操作是将写集中的变量还原到读集中声明的上一个版本。
5 智能合约的并行预执行
通过上述所提到Model、智能缓存和数据版本。XuperChain可以做到并行地执行智能合约。Bridge会为每一个合约调用生成一个Context,Context里有一个Cache实例对象,并且生命周期仅限于一次预执行调用。预执行中的读写操作将在此Cache中生效,因此预执行过程相互独立。由于合约的预执行是一个互不影响的过程,所以合约的预执行可以并行进行。
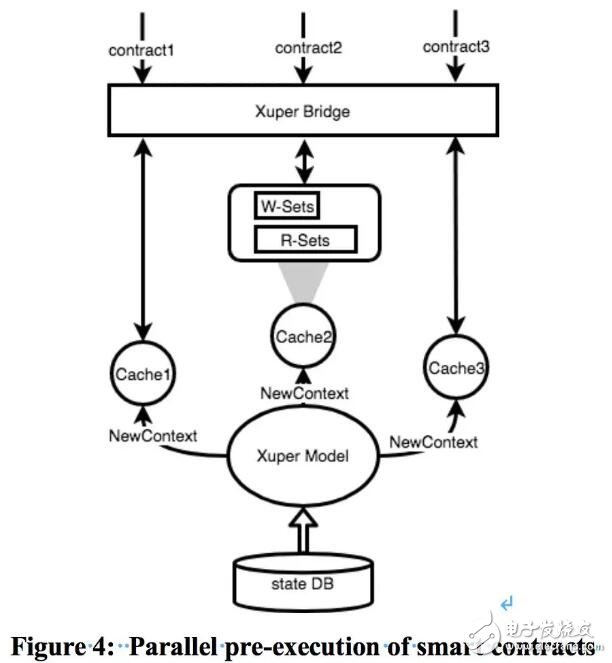
上图说明了合约是如何并行预执行的。假设Contract1、Contract2和Contract3同时启动。通过XuperBridge,初始化了三个Cache实例。Cache记录合约执行期间的读写集,并将其返回给用户。
6 智能合约的并行验证
当合约已经预执行完毕后。XuperChain返回给用户一个读写集。用户将在本地组装整个事务,并立即将其提交给XuperChain网络。然后XuperChain中的其他验证节点将验证合约。验证过程如下所述:
合约的验证主要包括3个步骤:
Step 1: XuperBridge初始化一个新的Context,并根据提交的事务的读取集在Context中填充Cache。如果找不到读集中指定版本的数据,则表示数据优先被其他合约更改,则Cache初始化失败,合约调用失败。
Step 2: 节点验证合约以验证写集是否与事务中提交过来的写入集是否相同。
Step 3: 如果读写集验证相同,交易验证通过,验证通过后会更新状态数据,否则返回执行失败。
由于每个合约的验证都在缓存中运行,冲突的事务将在步骤1中失败。因此,不同合约的验证是相互独立的,合约的正确性验证可以在第2步中并行进行。在第3步中,我们还会再次检查读集合的版本是否仍然有效。
7 局限性
以上就是XuperChain 中XuperModel支持合约并行执行的内容。并且所述的并发粒度是事务粒度,事务执行完后会状态是unconfirm状态,但是已经写入到DB中,后续合约调用可以直接引用该版本。但是XuperModel还有些缺点,首先,在合约执行期间对数据库的每个访问都将生成一个读集记录。因此,如果用户在合约调用期间访问过多的数据,那么读集将太大,甚至无法传输到其他节点。此外,该模型的存储资源占用较大,有待进一步优化。
总结
XuperChain提出了一种新的智能合约并行执行区块链结构,其特点是将智能合约的执行分为两个不同的阶段:预执行阶段和提交阶段,并通过XuperModel数据模型解决并行环境中的交易冲突问题。XuperModel模型是从utxo[1]模型发展而来的。目前,学术界对如何提高智能合约的性能有很多的研究。其中一些是从底层的存储引擎[4]开始的,其中一些使用STM技术[5]并行执行合约。XuperChain基于读写集的方法是确定性的,并且易于实现。在业界,Hyperledger Fabric[3]也提出了一种基于读写集的模型。Fabric模型的主要缺点是数据版本绑定到块高度,因此无法立即使用未确认事务的输出。综上所述,我们认为XuperChain提出的体系结构对于业界探索智能合约的并行化具有重要意义。今后,超级链团队将继续解决这个模型的一些局限性,提高性能。
-
区块链行业发展,金融领域应用方向?2018-08-06 3540
-
DENC底层架构的智能合约层与应用API2018-09-03 2686
-
区块链热度不止,参考架构9个部分解密2018-09-06 3050
-
介绍一种适合大规模数字信号处理的并行处理结构2021-04-30 1327
-
为什么要提出一种并行通信方法?并行通信方法有什么特点?2021-05-27 1888
-
一种新型多DSP并行处理结构2009-11-26 530
-
一种并行帧同步设计方案的提出、设计与应用2010-07-05 923
-
区块链的一个新虚拟机“IELE”可执行智能合约2018-10-24 1544
-
百度超级链自主研发出了区块链底层技术开源XuperChain2019-05-29 2474
-
基于一种专门用于在区块链上执行智能合约的IELE虚拟机介绍2019-07-17 1155
-
区块链智能合约有哪些常见的漏洞2019-11-04 4164
-
智能合约是怎么一回事2019-12-09 7782
-
区块链智能合约的原理_区块链智能合约技术的发展前景2020-07-21 6840
-
基于SPESC到目标程序语言的智能合约系统框架2021-03-24 1734
-
区块链结构层次应用和原理综述2021-04-14 1193
全部0条评论

快来发表一下你的评论吧 !
