

存算一体化芯片简史介绍 在DRAM上的各种尝试
描述
之前的几篇基本都是在讲,复兴的深度学习技术让内存和计算单元之间的GAP变得更大了,这个问题已经从传统的Memory Wall的讨论打了PIM的时代。说道PIM, Porcessor in Memory, 笔者在2014年的时候参加过一个Intel的高逼格的会议,当时3DXP已经在开发,Intel的同学讲,未来的CPU会坐在一个巨大的内存结构上,当时刚刚普及的NAND Flash技术只是个临时方案。因为NAND Flash和CPU之间的连接总是有一种,茶壶倒饺子的感觉。2014年的时候,深度学习应该是刚刚开始,大家都在纠结如何把数据从CPU传递到GPU,(其实,现在大家还在纠结)。
之后,借着大数据和深度学习的东风,PIM一下子流行起来。其实,PIM并不是一个新概念, 每一个很靠谱的PIM的综述文章都会讲那个开始-The Berkeley IRAM Project。
和他的亲兄弟RISC-V不一样,IRAM的命运不济,没有走到工业化这条路上。对于这个项目,David Patterson 大神在他的《Microprocessors in 2020》都讲过这个。大神就是大神,如果你现在看看这篇文章,会发现这个世界上的预言并不总像《沪市一万点不是梦》一样不靠谱。
文章的内容总结如下:
-
晶体管的集成度是惊人的,他们之前在1980年的预测过于保守,按那时的预测,在1995年,他们已经用上了2000年的电脑。
-
冯氏体系的优点是比较适合通用计算,但是未来更需要SIMD和并行的支持。
-
从1995年来看,2020年的电脑并不会有多大的不同。
-
最后,他安利了IRAM这个项目,认为计算和存储的结合会带来架构上的收益.
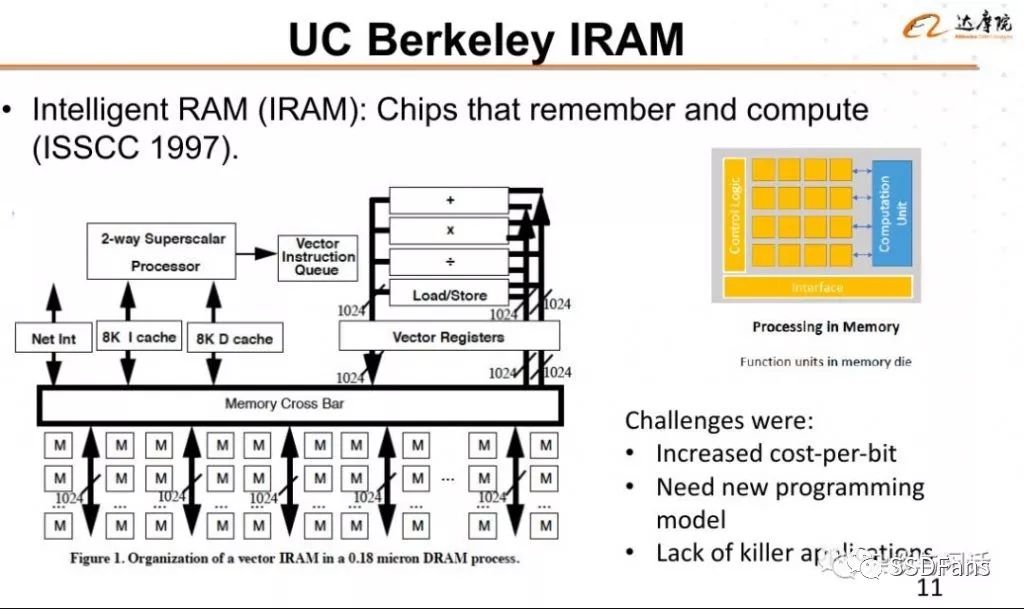
一句话,IRAM并没有像大神的RISC和RAID一样被工业届买单,但是Intel目前对于DeepLearning的看家吃法的家伙AVX-512就是加专用向量处理器的例子。【1】
另一个比较有代表意义的就是寒武纪的大电脑了。上一节的IRAM只是加了一个向量处理器在哪里,当时主要的想法是做并行计算,但是一直到现在,并行计算依然对于广大的程序猿来讲还是比较困难的。在IRAM的指令集的角度上,对比了标量和向量实现并行的对比。

看到这个,做芯片的同学是不是想到了SPARC,"While slower then recent Intel offerings, architecturally UltraSparc remains a very interesting microprocessor with unique (and very compiler friendly) organization of registers. And as we mentioned before it is a big Endean microprocessor, which is actually the only right way to build microprocessors :-)."[2]
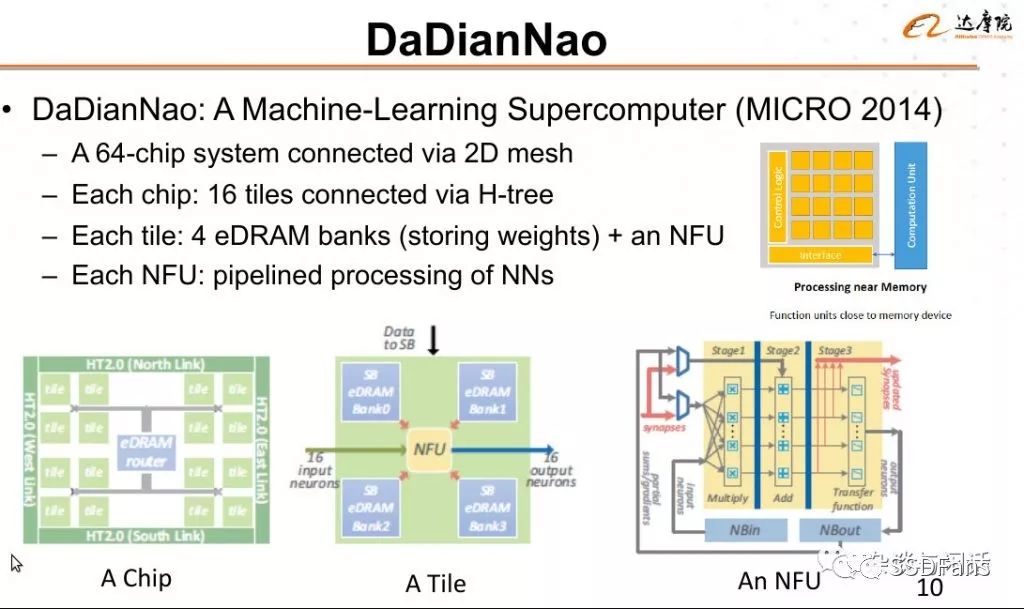
因此,DaDianNao的创新就在从计算机体系结构的角度,把一个NFU和内存结合。如何说IRAM是一个通用方案的话,Dadiannao就是一个专用的方案了。要知道,在2014年,大部分用户还在忙着调整GPGPU的参数,而DaDiannao类似于一个AI加速器的开山祖师,创建了RAM+NFU的流派。
SSDFans的同学们都知道,早在1985年,Toshiba就发明了NAND Flash,最近几年NAND Flash的大事就是盖楼,从平面到了立体,本来大家在15nm(1Y)之后,还要接着想办法挖沟。用了3D技术之后,一下子回到了40nm的幸福时光,每家都在大干快上,最高记录目前是512层。[3]
其实,DRAM也在搞同样的事情,和NAND Flash不同,NAND Flash是摩天大楼,而DRAM则是6层的板楼。

对的,HMC和HBM所用的Memory还是普通的DRAM芯片,只是用新的芯片封装工艺和计算芯片集成。HBM的使用和DRAM的使用并没有大的区别。这个和最新的AMD的ZEN2 Rome的CPU类似,7nm的计算die和14nm的IOdie合封。目前在hyerpscale,特别是OCP里面,一个chiplet的概念特别流行chiplet[4]. 这里不得不说一下我的老东家Avago就特立独行。人家整了一个比V100还大的独立片子[5],21,000,000,000的晶体管,7nm一句话,俺能卖出去,管什么良率问题。
因此,很自然,通过牛逼的工艺,把memory和计算单元合体,大家都在做,包括笔者供职的Xilinx也在搞AICore和HBM。现在的AI芯片,如果没有HBM的配置,估计都不好意思出门了。
不知道为什么,段教授选了一个这个例子。
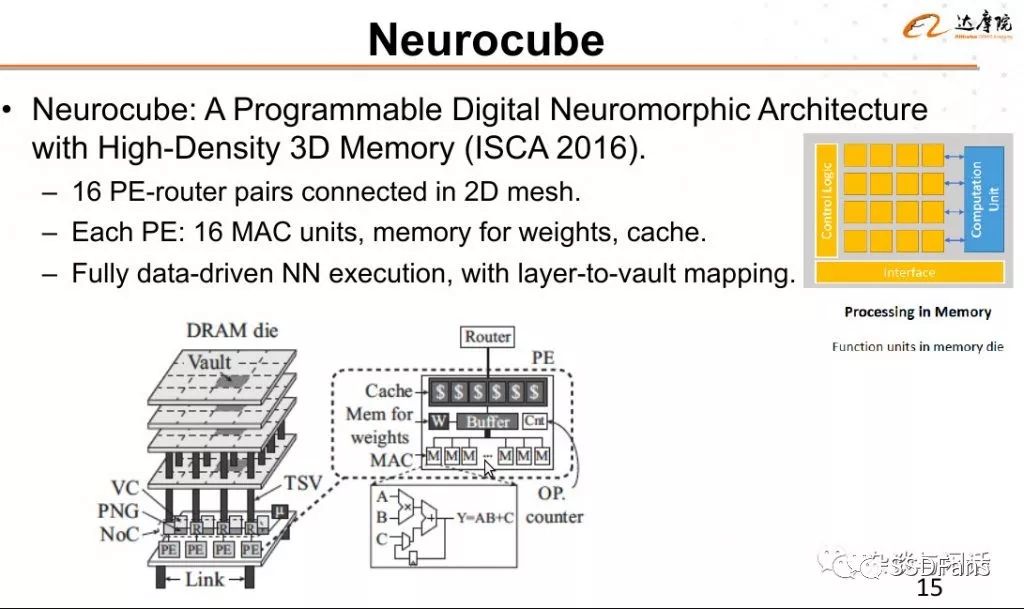
如果有懂行的同学可以评论一下。好了,这个段落主要是将讲了在DRAM上的各种尝试,2D和3D都有,但是基本上memory和xPU之间的界限还是明显的,虽然在一张床上,还是没有水乳交融。比较关心业界动态的,这一节基本上是靠谱的技术,都可以实现的。下一节应该都是脑洞了。
-
安克与知存科技联合打造Thus存算一体AI音频芯片2026-05-27 192
-
存算一体化与边缘计算:重新定义智能计算的未来2024-11-12 1701
-
什么是通感算一体化?通感算一体化的应用场景2024-01-18 16880
-
什么是存算一体芯片?存算一体芯片的优势和应用领域2023-10-23 8368
-
存算一体芯片新突破!清华大学研制出首颗存算一体芯片2023-10-11 2274
-
亿铸科技发布基于ReRAM的全数字化存算一体AI大算力芯片技术2022-09-01 4059
-
比存算一体更进一步,“感存算一体化”前景如何?2022-06-08 7795
-
存算一体大算力AI芯片将逐渐走向落地应用2022-05-31 6746
-
机电一体化综合实训考核2021-07-02 2118
-
基于RISC-V开放架构的存算一体化芯片解决方案2021-06-23 3618
-
如何实现一体化芯片-封装协同设计系统的设计?2021-04-21 1937
-
或让功耗降低1000倍,存算一体芯片正在突破2020-12-22 7750
-
如何实现机电一体化设计?2019-08-07 3854
-
什么是机电一体化2017-08-29 4510
全部0条评论

快来发表一下你的评论吧 !
