

区块链之密码学随机数
区块链
描述
一、随机数分类
1、真随机数
其定义为随机样本不可重现。实际上只要给定边界条件,真随机数实际上并不存在,可是如果产生一个真随机数样本的边界条件十分复杂且难以捕捉,可以认为用这个方法演算出来了真随机数。例如骰子、转轮、噪音等。
2、伪随机数,通过一定算法和种子得出,例如计算机软件中实现的就是伪随机数。
强伪随机数:难以预测的随机数,常用于密码学
弱伪随机数:易于预测的随机数
二、随机数特性
随机数有3个特性,具体如下:
随机性:不存在统计学偏差,是完全杂乱的数列,即分布均匀性和独立性
不可预测性:不能从过去的数列推测出下一个出现的数
不可重现性:除非将数列本身保存下来,否则不能重现相同的数列
随机数的特性和随机数的分类有一定的关系,比如,弱伪随机数只需要满足随机性即可,而强位随机数需要满足随机性和不可预测性,真随机数则需要同时满足3个特性。
三、随机数生成器
由于真随机数是不存在的,在程序中使用的都是伪随机数。那么生成伪随机数的生成器又称为密码学伪随机数生成器(英文:Cryptographically secure pseudorandom number generator,通称CSPRNG),是一种能够通过运算得出密码学安全伪随机数的伪随机数生成器。相较于统计学伪随机数生成器和更弱的伪随机数生成器,CSPRNG所生成的密码学安全伪随机数具有额外的伪随机属性。
介绍两种不同场景下常用的伪随机数生成器:
1. 线性同余法
因为通过线性同余方法构建的伪随机数生成器的内部状态可以轻易地由其输出演算得知,所以此种伪随机数生成器属于统计学伪随机数生成器。设计密码学的应用必须至少使用密码学安全伪随机数生成器,故需要避免由线性同余方法获得的随机数在密码学中的应用。

参数取值需要满足三个标准:函数在重复前应该产生0-M之间的所有数;产生的序列应该显得随机;生成函数可以用计算机方便地实现,满足条件的参数选择如下:
M一般取素数,且要求很大,对于32位机一般取值为$2^{31} - 1$
A的可取值不多,当$A= 7^5 =16807$时满足以上标准。
这个算法的缺点是,在参数确定后,伪随机序列只与N0相关,容易被破解。有一种改进的办法就是每隔n个数就以时钟值对M取模作为新的种子来产生新的序列。还有一种方法是直接将随机数加上时钟值再对M取模。
比较常用的一般是线性同余法,比如我们熟知的C语言的rand库和Java的java.util.Random类,都采用了线性同余法生成随机数。
一般来说,各大编程语言提供的伪随机数通用实现出于效率方面的考量,都达不到密码学强度的要求。
请勿在密码学强度系统中使用编程语言提供的通用伪随机数生成器实现。
2. ANSI X9.17
该伪随机数发生器是密码学意义上最强的伪随机数发生器之一,应用在金融安全和PGP上。它使用了3DES来加密,算法流程如下图
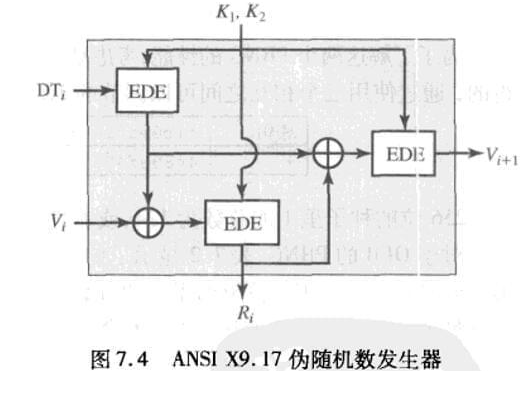
DTi:算法第i轮开始时的日期/时间值,64位,每一轮都被更新。
Vi:算法第i轮开始时的种子值,64位,每一轮都被更新。
Ri: 算法第i轮所产生的伪随机数。
K1,K2:各阶段算法所用的DES密钥,各56位。
可用以下表达式描述该算法:
Ri = EDE(K1,K2,Vi⊕EDE(K1,K2,DTi))
Vi+1 = EDE(K1,K2,Ri⊕EDE(K1,K2,DTi))
该方法的密码强度来自几个方面,包括112位密钥和3个EDE共计9次DES加密。
四、随机数在区块链中的使用
随机数有很多的应用场景,例如抽奖活动、验证码、Token、密码应用场景(生成秘钥、生成盐)等。
而随机数的生成是一个由来已久的问题。一个广泛的原则是:随机性的生成最好不被任何个体所控制。因此譬如从比特币的未来某区块的数据来获取随机性的方式是不能使人信服的,因为这些随机性最终实际上是由某个个体决定的,无法证明这个相关人没有作恶。
区块链中常用的是一种分布式的随机数生成算法,使用了DPOS结构中的受托人来提供随机性。受托人事先成私密的种子数据,然后生成区块时公布该种子数据的哈希值,在下一次生成区块时再公布该种子数据 。最终外部过程所使用的随机数由连续的多个(至少应大于等于 101)种子数据来确定。这样只要有一位受托人是诚实的并将他们的信息保密,那么其他人就无法预测结果。那么我们可以很放心地假设受托人中至少其中有一个是诚实的。这样产生的随机数可信程度是非常高的。
-
真随机数发生器在安全控制器解决方案中的应用2020-03-02 2584
-
简单学学之课堂二:区块链的透明性指的是什么?2018-01-05 4969
-
什么是随机数2021-07-22 1889
-
区块链的底层技术是密码学2018-11-22 2521
-
密码学在区块链中有着怎样的作用2018-12-27 5449
-
区块链系统中采用密码学技术是否存在安全威胁2019-01-10 1748
-
区块链随机数的安全性阐述2019-03-01 1252
-
如何使用随机数生成器来生成私钥2019-03-18 5979
-
区块链密码学的基础内容介绍2019-05-08 1831
-
区块链中产生随机数的性质及特点介绍2019-06-06 3680
-
区块链技术的基石密码学探讨2019-07-12 1667
-
随机数在密码学中占有重要的地位2020-06-16 4600
-
区块链在密码学中的应用及技术综述2021-06-25 1411
-
FPGA的伪随机数发生器学习介绍2023-09-12 3499
-
真随机数和伪随机数的区别2025-08-27 3221
全部0条评论

快来发表一下你的评论吧 !
