

主要从人脸检测方面来讲解目标检测算法
电子说
描述
在目标检测领域,可以划分为人脸检测与通用目标检测,往往人脸这方面会有专门的算法(包括人脸检测、人脸识别、人脸其他属性的识别等),并且和通用目标检测(识别)会有一定的差别。这主要来源于人脸的特殊性(譬如有时候目标比较小、人脸之间特征不明显、遮挡问题等),本文将主要从人脸检测方面来讲解目标检测。
目前主要的人脸检测方法分类
当前,人脸检测方法主要包含两个区域:传统人脸检测算法和基于深度学习的人脸检测算法。传统人脸检测算法主要可以分为 4 类:
基于知识的人脸检测方法;
基于模型的人脸检测方法;
基于特征的人脸检测方法;
基于外观的人脸检测方法。
2006 年,Hinton 首次提出深度学习(Deep Learning)的概念,它是通过组合低层的特征形成更高层的抽象特征。随后研究者将深度学习应用在人脸检测领域,主要集中在基于卷积神经网络(CNN)的人脸检测研究,如基于级联卷积神经网络的人脸检测(Cascade CNN)、基于多任务卷积神经网络的人脸检测(MTCNN)、Facebox 等,很大程度上提高了人脸检测的鲁棒性。
当然,像 Faster RCNN、YOLO、SSD 等通用目标检测算法也有用在人脸检测领域,也可以实现比较不错的结果,但是和专门人脸检测算法比还是有差别。
如何检测图片中不同大小的人脸?
传统人脸检测算法中针对不同大小人脸主要有两个策略:
缩放图片的大小(图像金字塔如图 1 所示);
图 1 图像金字塔
缩放滑动窗的大小(如图 2 所示)。
图 2 缩放滑动窗口
基于深度学习的人脸检测算法中,针对不同大小人脸主要也有两个策略,但和传统人脸检测算法有点区别,主要包括:
缩放图片大小:不过也可以通过缩放滑动窗的方式,基于深度学习的滑动窗人脸检测方式效率会很慢存在多次重复卷积,所以要采用全卷积神经网络(FCN),用 FCN 将不能用滑动窗的方法。
通过 anchor box 的方法:如图 3 所示,不要和图 2 混淆,这里是通过特征图预测原图的 anchorbox 区域,具体在 Facebox 中有描述。
图 3 anchor box
如何设定算法检测最小人脸尺寸?
主要是看滑动窗的最小窗口和 anchorbox 的最小窗口。
滑动窗的方法
假设通过 12×12 的滑动窗,不对原图做缩放的话,就可以检测原图中 12×12 的最小人脸。
但是往往通常给定最小人脸 a=40、或者 a=80,以这么大的输入训练 CNN 进行人脸检测不太现实,速度会很慢,并且下一次需求最小人脸 a=30*30 又要去重新训练,通常还会是 12×12 的输入,为满足最小人脸框 a,只需要在检测的时候对原图进行缩放即可:w=w×12/a。
anchorbox 的方法
原理类似,这里主要看 anchorbox 的最小 box,通过可以通过缩放输入图片实现最小人脸的设定。
如何定位人脸的位置
滑动窗的方式:
滑动窗的方式是基于分类器识别为人脸的框的位置确定最终的人脸。
图 4 滑动窗
FCN 的方式:
通过特征图映射到原图的方式确定最终识别为人脸的位置,特征图映射到原图人脸框是要看特征图相比较于原图有多少次缩放(缩放主要查看卷积的步长和池化层)。
假设特征图上(2,3)的点,可粗略计算缩放比例为 8 倍,原图中的点应该是(16,24);如果训练的 FCN 为 12*12 的输入,对于原图框位置应该是(16,24,12,12)。
当然这只是估计位置,具体的在构建网络时要加入回归框的预测,主要是相对于原图框的一个平移与缩放。
通过 anchor box 的方式:
通过特征图映射到图的窗口,通过特征图映射到原图到多个框的方式确定最终识别为人脸的位置。
如何通过一个人脸的多个框确定最终人脸框位置?
图 5 通过 NMS 得到最终的人脸位置
NMS 改进版本有很多,最原始的 NMS 就是判断两个框的交集。如果交集大于设定的阈值,将删除其中一个框。
那么两个框应该怎么选择删除哪一个呢? 因为模型输出有概率值,一般会优选选择概率小的框删除。
基于级联卷积神经网络的人脸检测(Cascade CNN)
Cascade CNN 的框架结构是什么?

级联结构中有 6 个 CNN,3 个 CNN 用于人脸非人脸二分类,另外 3 个 CNN 用于人脸区域的边框校正。
给定一幅图像,12-net 密集扫描整幅图片,拒绝 90% 以上的窗口。剩余的窗口输入到 12-calibration-net 中调整大小和位置,以接近真实目标。接着输入到 NMS 中,消除高度重叠窗口。下面网络与上面类似。
Cascade CNN 人脸校验模块原理是什么?
该网络用于窗口校正,使用三个偏移变量:
Xn:水平平移量,Yn:垂直平移量,Sn:宽高比缩放。
候选框口(x,y,w,h)中,(x,y)表示左上点坐标,(w,h)表示宽和高。
我们要将窗口的控制坐标调整为:
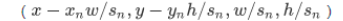
这项工作中,我们有种模式。偏移向量三个参数包括以下值:

同时对偏移向量三个参数进行校正。
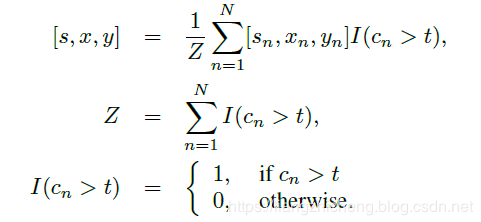
训练样本应该如何准备?
人脸样本;
非人脸样本。
级联的好处
最初阶段的网络可以比较简单,判别阈值可以设得宽松一点,这样就可以在保持较高召回率的同时排除掉大量的非人脸窗口;
最后阶段网络为了保证足够的性能,因此一般设计的比较复杂,但由于只需要处理前面剩下的窗口,因此可以保证足够的效率;
级联的思想可以帮助我们去组合利用性能较差的分类器,同时又可以获得一定的效率保证。
基于多任务卷积神经网络的人脸检测(MTCNN)
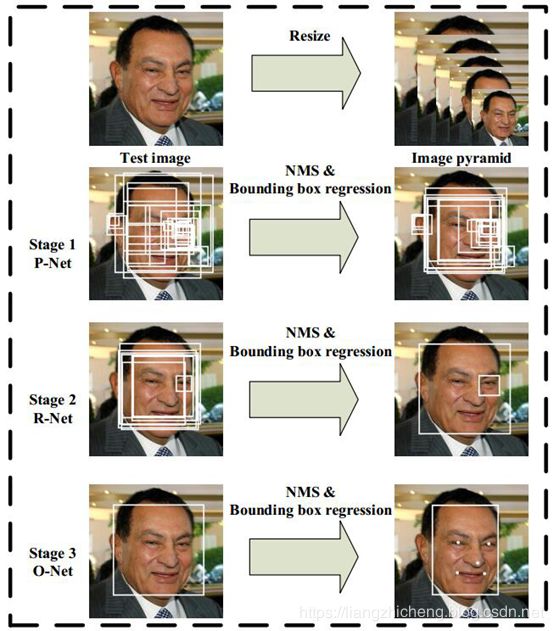
MTCNN 模型有三个子网络,分别是 P-Net,R-Net,O-Net。

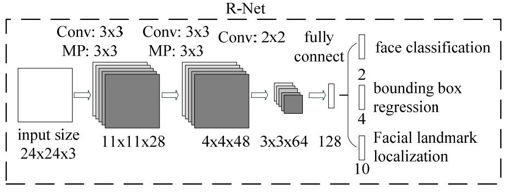
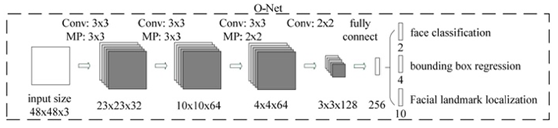
为了检测不同大小的人脸,开始需要构建图像金字塔,先经过 PNet 模型,输出人脸类别和边界框(边界框的预测为了对特征图映射到原图的框平移和缩放得到更准确的框),将识别为人脸的框映射到原图框位置可以获取 patch,之后每一个 patch 通过 resize 的方式输入到 RNet,识别为人脸的框并且预测更准确的人脸框,最后 RNet 识别为人脸的的每一个 patch 通过 resize 的方式输入到 ONet,跟 RNet 类似,关键点是为了在训练集有限情况下使模型更鲁棒。
还要注意一点:构建图像金字塔的的缩放比例要保留,为了将边界框映射到最开始原图上。
Facebox
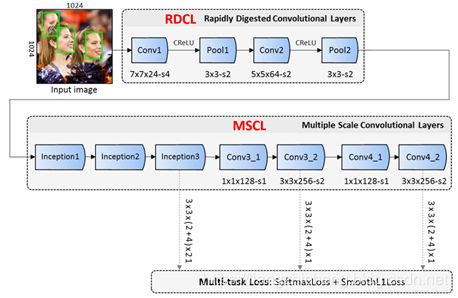
(1)Rapidly Digested Convolutional Layers(RDCL)
在网络前期,使用 RDCL 快速的缩小 feature map 的大小。 主要设计原则如下:
Conv1, Pool1, Conv2 和 Pool2 的 stride 分别是 4, 2, 2 和 2。这样整个 RDCL 的 stride 就是 32,可以很快把 feature map 的尺寸变小。
卷积(或 pooling)核太大速度就慢,太小覆盖信息又不足。权衡之后,将 Conv1, Pool1, Conv2 和 Pool2 的核大小分别设为 7x7,3x3,5x5,3x3。
使用 CReLU 来保证输出维度不变的情况下,减少卷积核数量。
(2)Multiple Scale Convolutional Layers(MSCL)
在网络后期,使用 MSCL 更好地检测不同尺度的人脸。 主要设计原则有:
类似于 SSD,在网络的不同层进行检测;
采用 Inception 模块。由于 Inception 包含多个不同的卷积分支,因此可以进一步使得感受野多样化。
(3)Anchor densification strategy
为了 anchor 密度均衡,可以对密度不足的 anchor 以中心进行偏移加倍,如下图所示:

-
人脸检测算法及新的快速算法2013-09-26 3965
-
ARM嵌入式环境中FDDB第一的人脸检测算法的运行2019-07-29 1893
-
PowerPC小目标检测算法怎么实现?2019-08-09 2728
-
分享一款高速人脸检测算法2021-12-15 1756
-
RK3399Pro是怎样去移植Tencent的mtcnn人脸检测算法的2022-02-15 1163
-
基于YOLOX目标检测算法的改进2023-03-06 1601
-
基于像素分类的运动目标检测算法2009-04-10 637
-
基于码本模型的运动目标检测算法2011-05-19 896
-
改进的ViBe运动目标检测算法_刘春2017-03-19 1443
-
深度学习在人脸检测中的应用2019-07-08 3815
-
基于深度学习的目标检测算法2021-04-30 11786
-
浅谈红外弱小目标检测算法2022-08-04 8551
-
无Anchor的目标检测算法边框回归策略2023-07-17 2411
-
基于强化学习的目标检测算法案例2023-07-19 1200
-
基于Transformer的目标检测算法2023-08-16 1203
全部0条评论

快来发表一下你的评论吧 !
