

“现代版罗塞塔石碑”,MIT&谷歌大脑用AI破解失传的古代文字
电子说
描述
漫漫尘埃下,掩藏了许多曾经辉煌灿烂古代文明,但我们现在却无法清晰地知道,这些地方究竟发生了什么。
搞懂这些历史的最佳方式,就是找到他们的文字记载。However,记载文字的石碑可以被考古学家们挖出来,但这些古文字究竟啥意思,现代的人们看不懂,需要语言学家们耗尽青春来推测。
现在,MIT CSAIL和谷歌大脑的研究者出手了,他们用机器学习破译了乌加里特文和线性文字B。
△ 乌加里特王宫
乌加里特文,Ugaritic,是一种楔形文字,属于闪米特语族。从字面上来看,就知道它是一个叫做乌加里特(Ugarit)的文明使用的语言,这个文明位于当今地中海沿岸的叙利亚,在公元前6000年前后就初现踪迹,在公元前1190年前后灭亡。
△ 乌加里特文
线性文字B,Linear B,由一种人类还没有破译出来的线性文字A演化而来,主要存活于公元前1500年到公元前1200年的克里特岛和希腊南部,是希腊语的一种古代书写形式。
△ 线性文字B
研究者们利用同一语族内不同语言之间的联系,用机器学习的方法来破译这两种失传的语言,这是破译古代语言的新方法,也将对罗曼语族的语言学研究有巨大的影响和提升。
这个方法让许多人惊叹:
简直是现代版的罗塞塔石碑!
PS,罗塞塔石碑是一块用3种语言写了同一个内容的石碑,帮助语言学家们读懂古文字。
希望能先把动物和植物的语言破译了,可以发现打开新世界的大门。
人类语言总相通
这项研究的核心方法,是借助人类语言的相似性。
比如,知乎用户@拉队短 在介绍欧洲语言相似性的时候,举了这么个栗子:
句子“那是六月末潮湿阴沉的一个夏日。”
英语:It was a humid, grey summer day at the end of June.
丹麦语:Det var en fugtig, grå sommerdag i slutningen af juni.
瑞典语:Det var en fuktig, grå sommardag i slutet av juni.
挪威语:Det var en fuktig, grå sommerdag i slutten av juni.
冰岛语:Það var rakur, grár sumardagur í lok júní.
看,长得差不多嘛,毕竟同属印欧语系日耳曼语族,单词的分布位置、句子的结构都很相似,如果你能看懂一种语言,就能大致猜测和它“血缘”关系近的另一种语言。
模型训练
为了破解这两种文字,研究者们提出了一个基于字符的seq2seq模型。
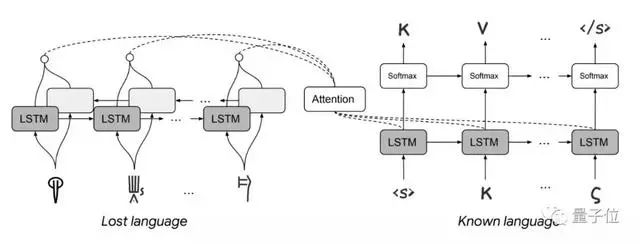
模型主要包含通用字符嵌入、剩余连接、单调排列正则化几个部分。
其中,线性文字B的字母和希腊文需要进行对应。
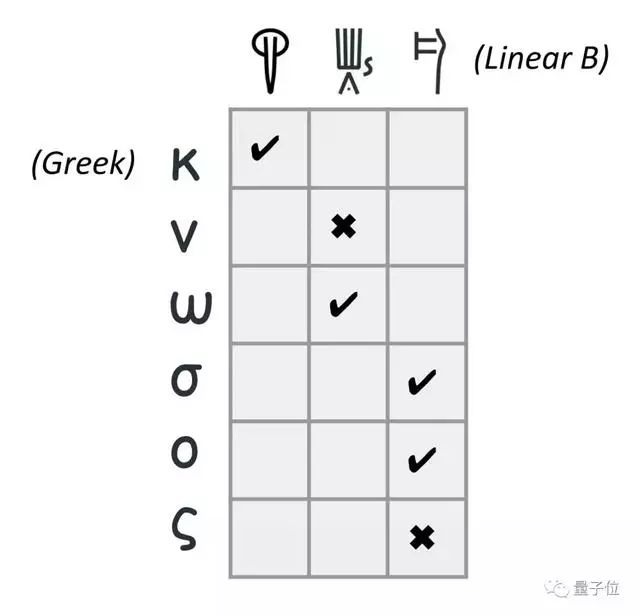
之后,借助神经解密算法,在具有不同语言特征的多种语言中提供强大的性能。

你懂的语言,和你不懂的语言
在算法模型的基础之下,需要的语料库除了待破解的乌加里特文和线性文字B,还需要一些现在的人类能看懂的语言。
研究团队选择了罗曼语族的数据库,包含意大利语、西班牙语和葡萄牙语三种语言的同源语音转录,需要对它们进行同源检测。
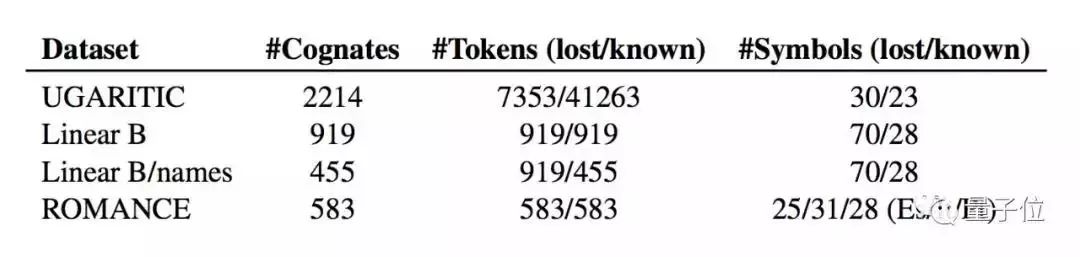
因此,数据集就用到上面这些,Symbols指的是语言中的字符,Token则是语言学中类似于单词的存在。
准确率
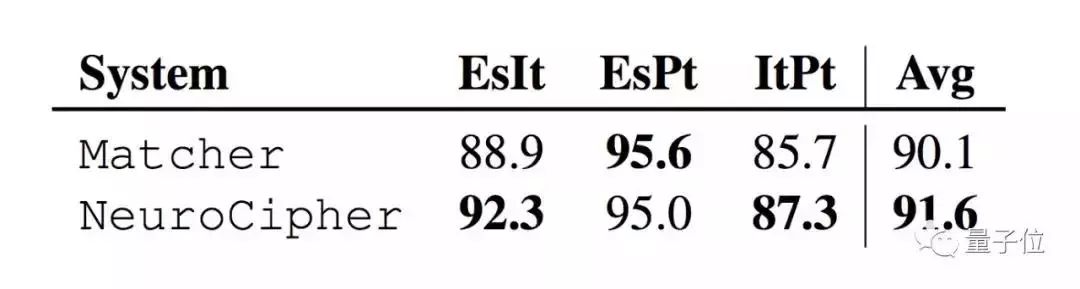
运行成果还不错,乌加里特文在无噪声条件下优于现有方法3.1%,在有噪声条件下优于现在的贝叶斯方法5.5%。

而线性文字B,在无噪声条件下准确率高达84.7%,在更具挑战性的LinearB名称数据集中达到67.3%的准确度。

在罗曼语族同源识别任务中,西班牙语准确度提升3.4%,葡萄牙语提升1.6%。
线性文字B的祖先,线性文字A还没有被人类破译,它被誉为考古界圣杯。
未来,在这项研究起作用的情况下,或许可以像借助罗曼语族三种语言的数据库一样,直接用机器借助其他已知的人类语言,实现暴力破解。
想破脑壳的语言学家们,可以把工作重心放到别的事情上了。
-
【「AI芯片:科技探索与AGI愿景」阅读体验】+可期之变:从AI硬件到AI湿件2025-09-06 2898
-
古代铜镜背后的技术原理——透光镜2023-08-22 7722
-
浅析HarmonyOS基于AI的通用文字识别技术2021-08-20 4519
-
识别文字的AI也能发现新冠病毒变异2021-03-02 1439
-
MIT团队欲用AI破解药物递送难题2021-01-12 2689
-
MIT工程师开发通过离子实现对大脑学习过程节能模拟的AI系统2020-07-07 2282
-
3D激光扫描仪三维激光扫描技术在石碑数字化技术手持三维扫描仪价2020-04-13 759
-
细思恐极!AI可以控制动物大脑活动2019-05-23 4028
-
用人工神经网络控制真实大脑,MIT的科学家做到了2019-05-11 4008
-
史上首次MIT研究用AI控制动物大脑活动2019-05-06 2223
-
谷歌再将AI部门独立,AI将在创新与独立环境中发展2018-06-09 3531
-
补贴AI投资 谷歌希望Pixel实现巨额盈利2016-11-09 636
-
[现代检测技术].周杏鹏.文字版2014-03-03 452
全部0条评论

快来发表一下你的评论吧 !
