

基于URAM原语创建容量更大的RAM
可编程逻辑
描述
引言:
UltraRAM 原语(也称为 URAM)可在 Xilinx UltraScale +™ 架构中使用,而且可用来高效地实现大容量深存储器。
由于大小和性能方面的要求,通常这类存储器不适合使用其他存储器资源来实现。
URAM 原语具有实现高速内存访问所需的可配置流水线属性和专用级联连接。 流水线阶段和级联连接是使用原语上的属性来配置的。
本篇博文描述的是通过将 URAM 矩阵配置为使用流水线寄存器来实现最佳时序性能的方法。
注意:本文由 Pradip K Kar、Satyaprakash Pareek 和 Chaithanya Dudha 共同撰写。
流水线需求:
通过在矩阵结构中连接多个 URAM,从可用的 URAM 原语实现大容量深存储器。
矩阵由 URAM 的行和列组成。一列中的 URAM 使用内置级联电路级联,且多列 URAM 通过外部级联电路互连,这被称为水平级联电路。
作为示例,图 1 示出了针对 64K 深 x 72 位宽存储器的 4x4 URAM 矩阵的矩阵分解。
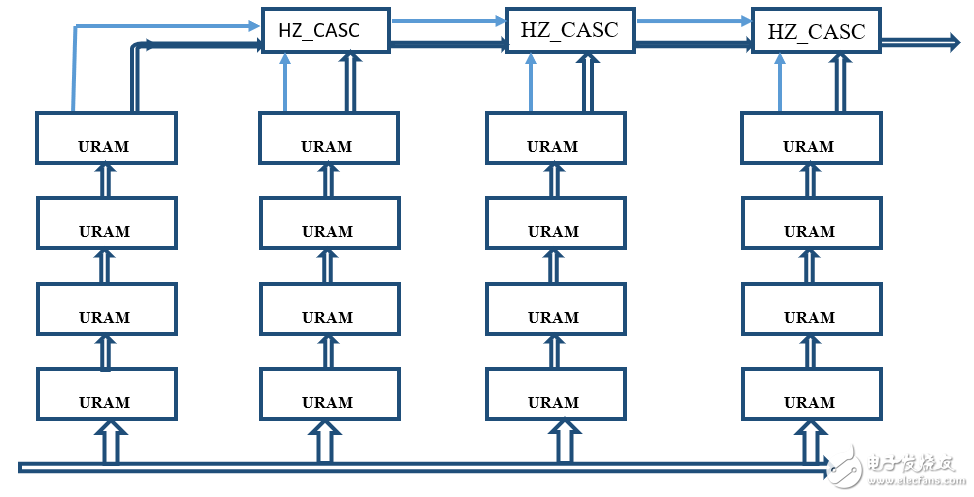
图 1:4 行 4 列的 URAM 矩阵(可实现 64K 深 72 位宽的存储器)
在没有流水线设计的情况下,深度联结构会导致内存访问出现大的时钟输出延迟。 例如,在默认情况下,上述 URAM 矩阵可以达到约 350 MHz。要以更快的速度访问内存,应插入流水线。如果在网表中指定了一定数量的输出时延,Vivado Synthesis 即会自动实现此功能。
指定 RTL 设计中的流水线:
有两种方法可以用来指定 RTL 设计中的流水线的用途,可以通过使用 XPM 流程,也可以通过行为 RTL 来推断内存。
如果 RTL 设计通过 XPM 流程来创建 URAM 内存,则用户可以将对流水线的要求指定为 XPM 实例的参数。参数“READ_LATENCY_A/B”用于捕获内存的时延要求。
可用的流水线阶段数是 LATENCY 值减去 2。 例如,如果 Latency 设置为 10,则允许 8 个寄存器阶段用于流水线操作。另外两个寄存器可用来创建 URAM 本身。

图 2:使用 XPM 设置流水线设计
如果用户使用 Vivado 用户指南中提供的模板来编写 RTL,并通过此方法来创建 URAM,那么,他们可以在 URAM 的输出时创建尽可能多的寄存器阶段。唯一的要求是,与数据一起,流水线寄存器的启用也需要流水线化。
图 3 显示数据和流水线的启用。
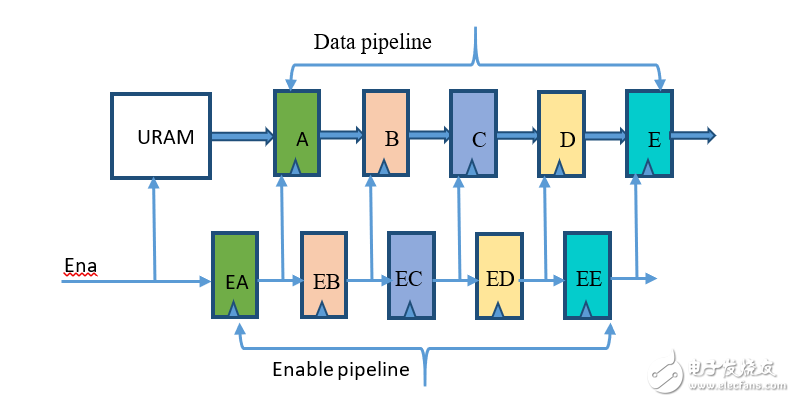
图 3:URAM 块输出时的数据及流水线启用规范
图 4 示出了 RTL 级 RAM 流水线设计示例。

图 4:用来指定数据和流水线启用的 verilog 模板
分析日志文件:
Vivado Synthesis 根据上下文环境和场景发布与 URAM 流水线相关的不同消息。下表说明要在 vivado.log 文件中查找的一些消息和要采取的相应操作。
请注意,推荐的流水线阶段基于可实现最高性能 (800 MHz+) 的完全流水线化的矩阵。此建议不受实际时序约束的限制。
| 情况 | 消息 | 操作 |
| 无流水线设计的 URAM | WARNING: [Synth 8-6057] Memory: "uram00/ram1/mem_reg" defined in module: "top_sp_no_pipe" implemented as Ultra-Ram has no pipeline registers. It is recommended to use pipeline registers to achieve high performance | 增加时延或插入一些流水线阶段。 |
| URAM 严重受流水线限制 | CRITICAL WARNING: [Synth 8-6013] UltraRAM uram00/ram1/mem_reg is under-pipelined and may not meet performance target : Pipeline stages found = 1; Recommended pipeline stages =8 | 增加时延或插入一些流水线阶段。 |
| 带有合理流水线设计的 URAM | INFO: [Synth 8-5813] UltraRAM uram00/ram1/mem_reg: Pipeline stages found = 4; Recommended pipeline stages =8 | 检查是否满足时间要求。如果不满足性能,则增加时延。 |
| 流水线多于需要的 URAM | INFO: [Synth 8-5813] UltraRAM uram00/ram1/mem_reg: Pipeline stages found = 10; Recommended pipeline stages =8 | 减少时延,否则 FF 利用率将显着增加。 |
| 流水线设计结果 | INFO: [Synth 8-5814] Pipeline result for URAM (uram00/ram1/mem_reg): Matrix size= (4 cols x 4 rows) | Pipeline stages => ( available = 10, absorbed = 8 ) |
时间性能估计:
下表说明流水线寄存器的数量与可实现的最大估计频率之间的关系。
请注意,实际的时间数仍将取决于最终地点和路线结果。
下列数字基于 speedgrade-2 Virtex® UltraScale+™ 部件以及我们使用 4x4 矩阵实现的 64K x 72 URAM 示例工程。
| 流水线阶段 | URAM 中吸收的流水线 | 所用流水线资源 | 关键路径上的数据路径延迟 (ns) | 估计的最大频率 |
| 0 | 0 | 不适用 | 2.7 | 370 MHz |
| 1 | 1/1 | OREG | 2.15 | 465 MHz |
| 2 | 2/2 | OREG,FDRE | 1.632 | 612 MHz |
| 4 | 4/4 | OREG,REGCAS,FDRE,IREG_PRE | 1.376 | 726 MHz |
| 6 | 6/6 | OREG,REGCAS,FDRE,IREG_PRE | 1.376 | 726 MHz |
| 8 | 8/8 | OREG,REGCAS,FDRE,IREG_PRE | 1.1 | 909 MHz |
| 10+ | 8/10+ | OREG,REGCAS,FDRE,IREG_PRE | 1.1 | 909 MHz |
数据路径延迟具有以下一个或多个组件。
Tco = 1.38 ns, Clk To CascadeOut on URAM
Tco = 0.82 ns, Clk To CascadeOut on URAM with OREG=true
Tco = 0.726 ns, Clk to Dataout on URAM with OREG=true, CASCADE_ORDER = LAST
URAM -> URAM 级联延迟 = 0.2 ns
URAM -> LUT 信号网络延迟 = 0.3 ns
LUT 传输延迟 = 0.125 ns
LUT -> LUT 信号网络延迟 = 0.2 ns
LUT5 -> FF 延迟 = 0.05
结论:
URAM 原语是创建容量非常大的 RAM 结构的有效方法。 它们被设置为易于级联以便在您的设计中创建容量更大的 RAM。
但是,太多这类结构级联在一起可能会通过 RAM 产生很大的延迟。从长远来看,花时间让您的 RAM 完全流水线化会带来很多好处。
URAM 原语是创建容量非常大的 RAM 结构的有效方法。 它们被设置为易于级联以便在您的设计中创建容量更大的 RAM。
但是,太多这类结构级联在一起可能会通过 RAM 产生很大的延迟。从长远来看,花时间让您的 RAM 完全流水线化会带来很多好处。
-
ISERDESE2原语端口及参数介绍2025-03-17 3047
-
如何让级联URAM获得最佳时序性能2023-09-26 5507
-
如何通过Vivado Synthesis中的URAM矩阵自动流水线化来实现最佳时序性能2023-05-08 3539
-
URAM和BRAM有哪些区别2022-07-25 7973
-
Xilinx原语使用方法有哪些2022-02-08 2589
-
Flash和RAM的容量2021-08-11 2312
-
Xilinx原语使用方法2021-03-24 1361
-
URAM和BRAM有什么区别2021-01-27 2392
-
URAM和BRAM的区别是什么2020-12-23 4813
-
内存ram容量计算2020-05-10 6543
-
Xilinx是否具有用于推断RAM的算法类型和原语类型?2020-03-31 2494
-
BRAM和URAM重要的片上存储资源,两者有显著的区别2019-03-06 29893
-
xilinx原语使用方法2017-10-19 1380
-
xilinx 原语使用方法2017-10-17 1391
全部0条评论

快来发表一下你的评论吧 !
