

能不能用GAN破解标注数据不足的问题呢
电子说
描述
在计算机视觉领域,深度学习方法已全方位在各个方向获得突破,这从近几年CVPR 的论文即可看出。
但这往往需要大量的标注数据,比如最著明的ImageNet数据集,人工标注了100多万幅图像,尽管只是每幅图像打个标签,但也耗费了大量的人力物力。
说到标注这件事,打个标签其实还好,如果是针对图像分割任务,要对图像进行像素级标注,那标注的成本就太高了。跟专业的标注公司打过交道的朋友都知道,打标签、标关键点和标像素区域,所要付出的成本可大不同。
在医学影像领域,图像数据往往难以获取,而这又是一个对标注精度要求极高的领域。
最近几年,以GAN为代表的生成模型经常见诸报端,那能否用GAN破解标注数据不足的问题呢?
最近发现一篇论文Generating large labeled data sets for laparoscopic image processing tasks using unpaired image-to-image translation,来自德国国家肿瘤疾病中心等单位的几位作者,提出通过GAN对计算机合成的人体腹腔镜图像进行转换的方法,能够大批量得到与真实图像相似的合成图像,并在器官分割实验中,大大改进了真实图像的分割精度。非常值得一读。
下面是作者信息:

下图即为作者用计算机图形学方法合成的腹腔镜图像(A,下图第一列),和转换后的具有真实感的合成图像(Bsyn,下图第二列和第三列)。
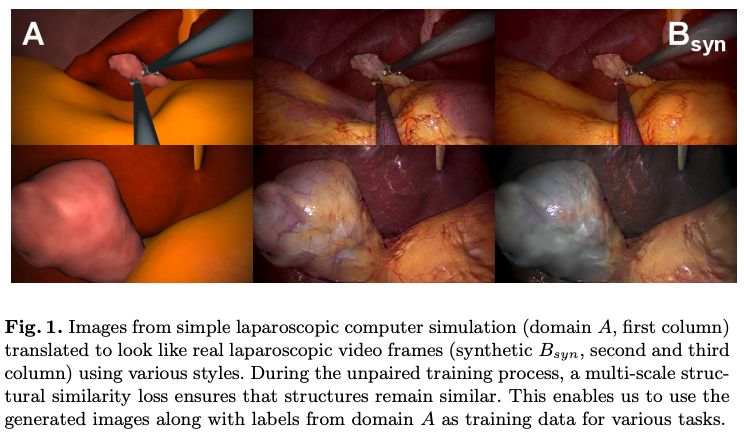
CV君不是专业的医务人员,不过也可以看出转换后的图像的确比之前更具真实感。
方法介绍
作者使用Nvidia发布的MUNIT库进行图像转换,并进行了改进。
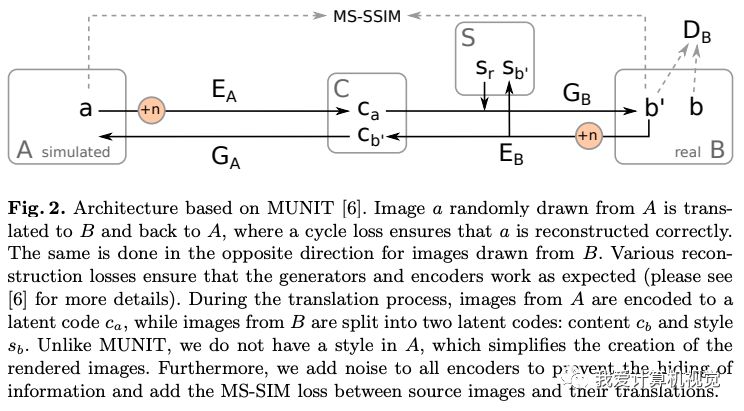
这是一个非成对数据的图像转换问题,作者使用一种循环loss,将A 域(模拟图)和B域(少部分真实图)进行循环的编码、生成、鉴别。
因为A 域内图像是计算机模拟出来的,所以天然的带有像素级标签。
作者的改进之处在于添加了MS-SSIM loss (Multi-Scale Structural Similarity,多尺度结构相似性损失函数),保证转换后图像结构相同。
另外,作者对编码器加入随机噪声,防止生成的纹理都完全相同。
下图为作者提供的训练数据的例子:
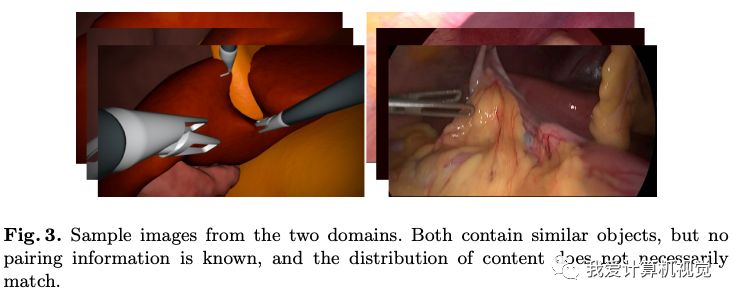
请注意,他们含有相似的目标,但很显然内容并不是匹配的,这样的训练数据是比较好找到的。
实验结果
作者用上述方法生成了10万幅图像,并在图像分割任务中验证了,这种合成数据对医学图像分割模型训练的价值。
下图对各种情况进行了分割结果比较:
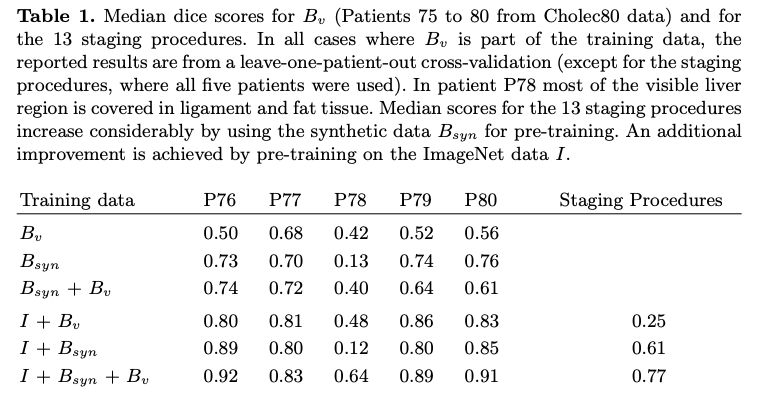
Bv是原有真实数据,Bsyn是合成数据,I代表模型在Imagenet进行了预训练。
可见,使用这种合成数据大幅改进了分割精度。而在Imagenet数据集上预训练的结果更好。这种方法对你有什么启发?欢迎留言。
-
C语言中结构体能不能相加2023-12-19 2376
-
LM3886功放,大家帮忙看下,能不能用!2012-10-03 3708
-
labview能不能用程序控制波形图的工具选板呢2013-09-14 9536
-
谁破解了saber这个软件,能不能说下怎么破解的?2017-04-12 3422
-
请问C6678的SRIO的参考时钟到底能不能用125MHz呢?2018-06-25 4001
-
请问能不能用干簧管开关直接控制电动机的转与停?2021-04-12 1680
-
能不能用Micropython驱动OLED屏幕看视频呢?2022-01-07 1046
-
能不能上传一些大型软件工具,比如altium proteus .这些都是破解版2023-10-07 784
-
电池能不能修复?2009-11-23 1474
-
谐波治理到底能不能节电2021-04-23 4754
-
大型辊压机轴磨损能不能现场维修?2022-06-23 779
-
指针能不能作为循环变量?2023-02-16 1901
-
物联网流量卡到底能不能用?2023-08-28 8290
-
几个LED并联,能不能用恒压电源?2023-11-30 2388
-
一体成型电感外壳破损还能不能用2024-10-31 668
全部0条评论

快来发表一下你的评论吧 !
