

计算机视觉的三生三世
描述
7 月 12 日-7 月 14 日,2019 第四届全球人工智能与机器人峰会(CCF-GAIR 2019)于深圳正式召开。峰会由中国计算机学会(CCF)主办,雷锋网、香港中文大学(深圳)承办,深圳市人工智能与机器人研究院协办,得到了深圳市政府的大力指导,是国内人工智能和机器人学术界、工业界及投资界三大领域的顶级交流博览盛会,旨在打造国内人工智能领域极具实力的跨界交流合作平台。
7 月 12 日,腾讯 AI Lab & Robotics X 主任,ACM Fellow, IEEE Fellow, CVPR 2017 大会主席张正友博士为 CCF-GAIR 2019 主会场「AI 前沿专场」做了题为「计算机视觉的三生三世」的大会报告。以下为报告全文——
大家好!非常感谢雷锋网的邀请,让我有这个机会给大家做个分享。今年是中国人工智能四十周年,在这四十年间发生了很多事情,雷锋网让我跟大家讲一讲计算机视觉的前世、今生和可能的未来。其实这个报告应该由我的好朋友香港科技大学权龙教授来讲,他比我早一年出国,而且他现在还在港科大潜心研究计算机视觉。我这些年间,还有好多年在做语音处理和识别、多媒体处理和机器人,所以我在计算机视觉上的研究史还不算很长。不过权龙教授有事没法参加,我只能滥竽充数,给大家讲讲计算机视觉的一些故事。
雷锋网找我是听说我开始研究计算机视觉比较早。我 1985 年浙大本科毕业,1986 年去法国,参与研发了可能是世界上第一台用立体视觉导航的移动机器人。
图像处理
1986 年其实发生了很多事情,1986 年是我第一次参加国际会议,是在巴黎召开的 ICPR(世界模式识别大会)。在这次大会上,我碰到了复旦大学的吴立德教授,他带领了一支中国的代表团,并在会上做了一场大会报告,介绍了中国在模式识别上的研究现状,他们准备申请 1988 年的 ICPR 在中国召开。
这里需要提到一个关键性的人物,那就是普渡大学的傅京孙教授,他是模式识别领域的鼻祖。他是 1973 年第一届 ICPR 的主席,1976 年创建了 IAPR,1978 年创刊了 IEEE TPAMI,并担任第一届主编。本来他是支持 1988 年 ICPR 在中国召开的,但不幸的是 1985 年他去世了,所以 1988 年的申请没有成功。如果 1988 年 ICPR 能在中国召开,也许中国在模式识别和计算机视觉上的发展会更提前。当然历史没有如果。ICPR 在中国的召开等到了三十年以后,2018 年在谭铁牛院士的带领下,ICPR 第一次在中国召开。
1986 年还有一个很重要的事件,就是我的法国学长马颂德回国,他创立了 NLPR(国家模式识别重点实验室)。NLPR 创立之后,吸引了大批国外的学者回国,同时邀请了很多国外的访问学者,中国计算机视觉领域开始与国际接轨。当然马颂德是中国科技界重要人物,后来担任科技部副部长。1997 年他还创立了中法联合实验室,这个实验室一半的研究人员都是法国人,这在中国也是一个壮举。
提到计算机视觉,离不开一个标志性人物,MIT 的教授 David Marr。1979 年,刚好 40 年前,他提出了视觉计算的理论框架。Marr 的理论框架有三个层次,从计算什么,到如何表达和计算,到硬件的实施。
具体到三维重建,Marr 认为从图像要经过几个步骤,第一个步骤叫 primal sketch,也就是图像处理,比如边缘提取。所以到八十年代中叶,计算机视觉的主要工作是图像处理。最有名的工作可能是 1986 年 MIT 一个硕士生发表的 Canny 边缘检测算子,基本上解决了边缘提取的问题。如下图所示,左边是原始图像,右边是检测出的边缘。

那时候还有一个比较有名的工作是华人科学家沈俊做的,他那时在法国波尔多大学。他比较了不同的算子。他的算子在有些图像方面要比 Canny 检测器要好。所以到了八十年代中叶,当我留学法国的时候,图像处理已经做的差不多了。
立体视觉及三维重建
幸运的是,几何视觉刚开始兴起。有两位代表人物,一位是法国的 Olivier Faugeras,他是我的博士导师,另一位是美国的 Thomas Huang,我们叫他 Tom。他们是好朋友,还一起写过文章。我 1987 年就认识 Tom,他对我有非常大的帮助。他培养了 100 多位博士,包括不少活跃在中国学术界和工业界的计算机视觉专家,他对中国计算机视觉的贡献是非常巨大的。
我很荣幸师从 Olivier Faugeras,参与开发了世界上第一台用立体视觉导航的移动机器人。1988 年我的第一个研究成果发表在第二届 ICCV 上,右边是在美国 Florida 开会的一张照片。那时候计算机视觉还没有红火,那届 ICCV 大概只有 200 个参会者,华人就更少了,大概只有我、权龙,还有 Tom 的学生翁巨扬。我在博士期间围绕三维动态场景分析做了不少工作,1992 年把这些整合成一本书发表。

现在我想举一个简单的例子,不定性的建模和计算,希望通过下面这一页 PPT 你们就能明白什么是三维计算机视觉。
这里需要用到概率与统计,这非常重要,但现在做视觉的人往往忽略了。下面两条线代表了两个图像平面。左边图像上一个白点对应右边图像上一个白点。每个图像点对应空间一条直线,两条直线相交就得到一个三维点,这就是三维重建。同样,左边图像的黑点对应右边图像的黑点,两线相交得到一个三维点。但是图像的点是检测出来的,是有噪声的。我们用椭圆来代表不定性,那么图像的一个点就不对应一条线了,而是一个椎体。两个椎体相交,就代表了三维重建的点的不定性。这里可以看到,近的点要比远的点精确。当我们用这些三维重建点的时候就需要考虑这些不定性。比如当机器人从一个地方移动到另一个地方,需要估计它的运动时就必须考虑数据的不定性。
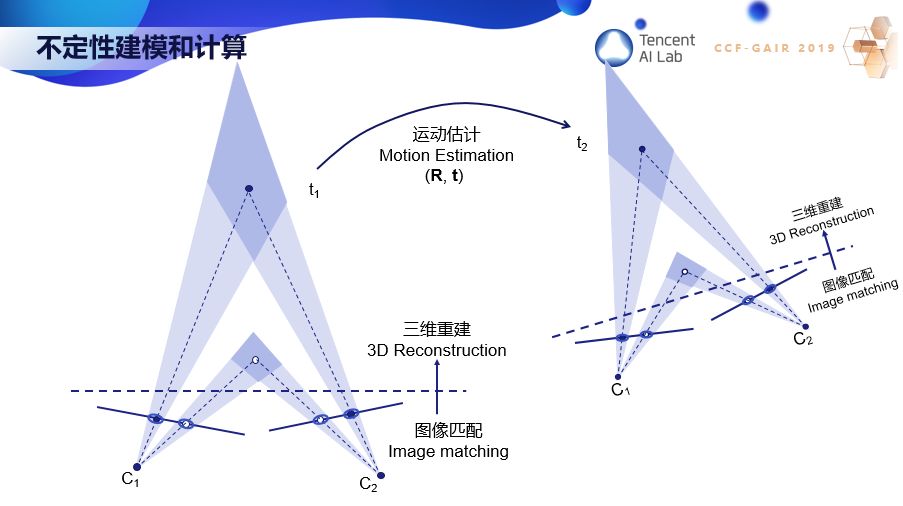
90 年代初我提出了 ICP 算法,通过迭代点的匹配来对齐不同的曲线或曲面。这个算法也用在很多地方。我们现在经常听到的SLAM,它其实就是我们以前做的从运动中估计结构,三维重建,不定性估计,ICP。事实上,SLAM 在 90 年代初理论上已经解决了。
1995 年我提出了鲁棒的图像匹配和极线几何估计方法,同时把程序放到网上,大家都以此作为参照。这可能是世界上第一个,至少是之一,把计算机视觉的程序放到网上让别人用真实图像来测试的。所以这个算法那时候就成为计算机视觉的通用方法。
1998 年我提出了一个新的摄像机标定法,后来大家都称它为「张氏方法」,现在它已经在全世界的三维视觉、机器人、自动驾驶上普遍应用,也获得了IEEE Helmholtz 时间考验奖。

1998 年我和马颂德对日益成熟的几何视觉做了总结,作为研究生教材由科学出版社出版。
1998 年还发生了很多事情,一个是 MSRA(微软亚洲研究院)的成立,一个是腾讯公司的成立。这两家看似无关的机构其实对中国计算机视觉的发展,对中国人工智能的发展,起了不可估量的作用。MSRA 给中国带来了国际先进的研究方法和思路,培养了一大批中国的优秀学者,同时也请了一些国外的研究学者来到中国。腾讯促进了中国互联网的发展,因为有互联网,中国研究人员能够几乎实时地接触到国际最顶尖的研究成果。所以这两个结合,对中国人工智能领域的发展起到了很大的作用。
中国计算机视觉界一个重要的标志性事件是 2005 年 ICCV 在北京召开,马颂德和 Harry Shum 担任大会主席,这标志着中国计算机视觉的研究水平已经得到国际的认同。我也很荣幸地从 Tom Huang 前辈手中接过 IEEE Fellow 的证书。
深度学习的崛起
可能几何视觉的理论已经比较成熟了,90 年代末,计算机视觉的研究开始进入物体和场景的检测和识别,主要方法是传统特征加上机器学习。
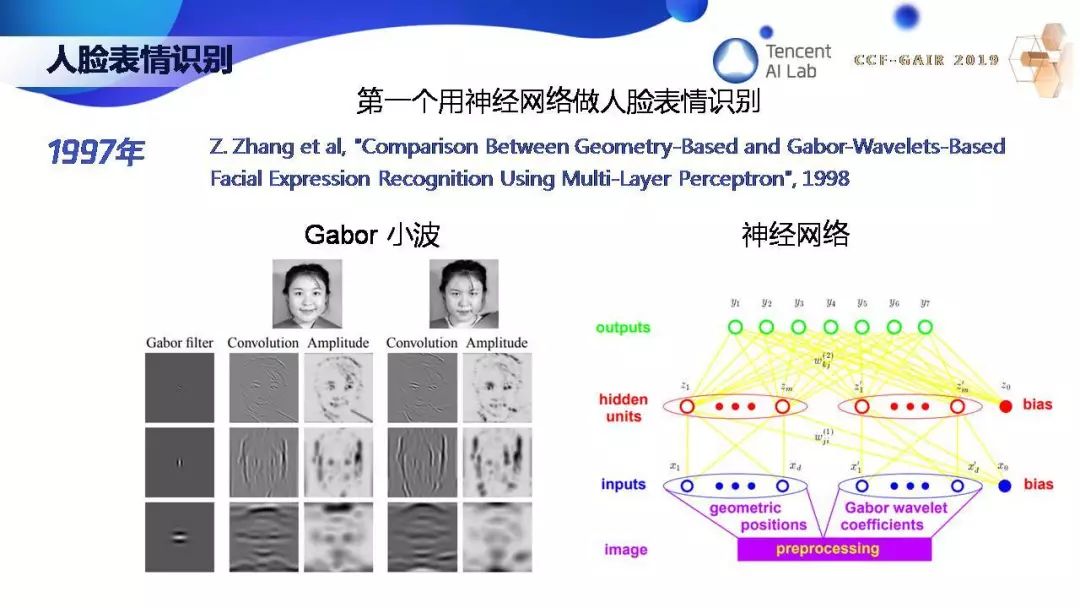
那时候我做几何视觉做了很长时间,1997 年,我也开始尝试,开发了世界上第一个用神经网络来识别人脸表情的系统,用的特征是 Gabor 小波。虽然 20 多年前就开始人脸表情识别,但那时数据太少,一直到 2016 年我们才在微软把人脸表情识别技术商业化,在微软的认知服务上,大家都可以调用。
在传统特征加机器学习的年代,需要提一下一个里程碑的工作,那就是 2001 年的 Viola-Jones Detector。通过 Harr 特征加级联分类器,人脸的检测能够做得非常快,在 20 年前的机器上就能做到实时。这对计算机视觉产生了很大的影响。此后的循环是一波一波的新数据集推出,加一波一波的算法刷榜。
2009 年一个叫 ImageNet 的数据集出现了,这是斯坦福大学李飞飞团队推出的,这个数据集非常重要,它的意义不在于这个数据集很大,而在于几年后催生了深度学习时代。
2012 年,Geoffrey Hinton 的两个学生开发了 AlexNet,用了 8 层神经网络,6 千万参数,误差比传统方法降了十几个百分点,从 26% 降到 15%,从此开启了计算机视觉的深度学习时代。这个 AlexNet 结构其实和 1989 年 Yann LeCun 用于手写数字识别的神经网络没有很大区别,只是更深更大。
由于 Geoffrey Hinton, Yoshua Bengio, Yann LeCun 对深度学习的贡献,他们共同获得了 2018 年的图灵奖。这个奖他们当之无愧。要知道 Geoffrey Hinton 1986 年就提出了 backpropagation,坐了 25 年的冷板凳。

在深度学习时代还有一个里程碑的工作,2015 年,微软亚洲研究院的何恺明和孙剑提出 ResNet,用了 152 层神经网络,在 ImageNet 测试集上的误差比人还低,降到了 4% 以下。
我在深度学习领域也有一点贡献。2014 年我和 UCSD 的屠卓文合作,提出了 DSN(Deeply- Supervised Nets)深度监督网络,虽然影响没有 ResNet 大,但也有近一千次引用。我们的想法是直接让输出监督中间层,使得最底层尽可能最大逼近要学习的函数,同时也缓解梯度「爆炸」或「消失」。
刚刚过去的 CVPR2019 可以被称为是华人的盛典,在组织者里面有很多华人面孔,包括大会主席朱松纯、程序委员会主席华刚和屠卓文。在五千多篇投稿中,40% 来自大陆,最佳论文奖和最佳学生论文奖的第一作者也都是华人。所以中国的计算机视觉能力还是很强的,这一点值得骄傲。
计算机视觉的研究要回归初心
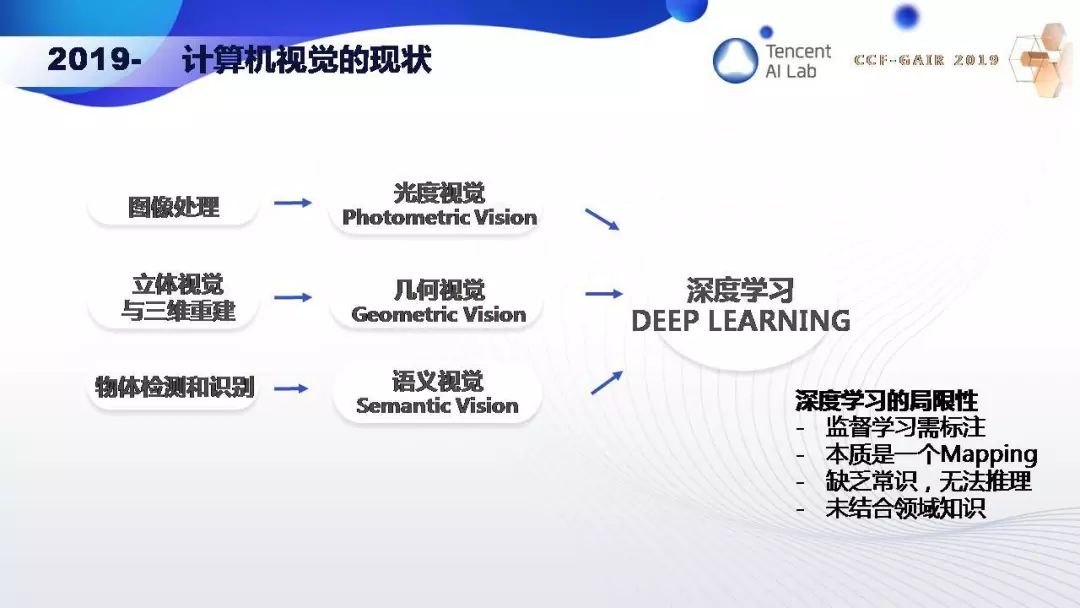
现在让我们回顾一下计算机视觉研究的演变,从最初的图像处理、立体视觉与三维重建、物体检测和识别,到光度视觉、几何视觉和语义视觉,到现在的深度学习打遍天下。这是让我担忧的。深度学习有很多局限性。
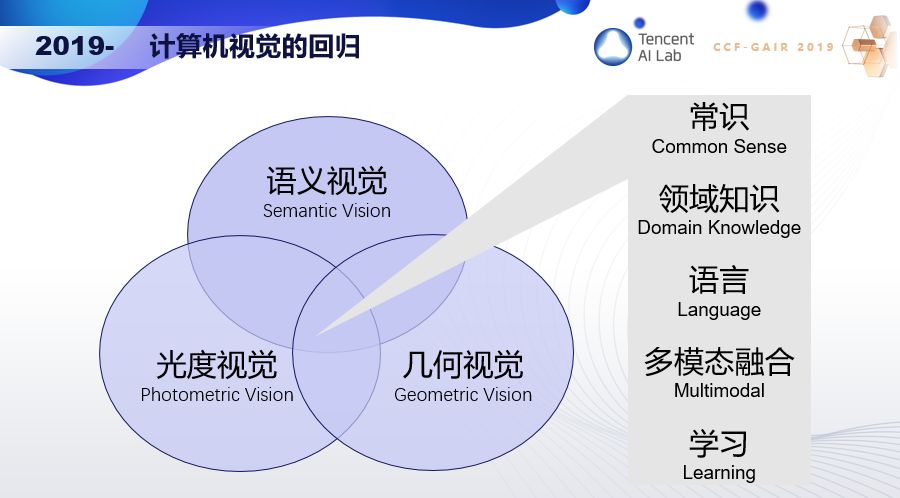
我认为接下来应该要回归初心,让光度视觉、几何视觉和语义视觉紧密结合起来,同时注入常识和领域知识,和语言进行多模态融合,通过学习不断演变。
我们腾讯 AI Lab 在这方面也开始做了一点点工作。比如我们的看图说话项目能够用语言描述一张照片的内容,2018 年 1 月,我们上线 QQ 空间 app 让视障用户「看到」图片。

我们还整合了计算机视觉、语音识别和自然语言处理技术,开发了一个虚拟人产品,探索多模态人机交互,赋能其他场景,助力社交。我们还开发了二次元的虚拟人来做游戏解说,它能实时理解游戏场景并将它描述出来。
那么现在的人工智能真的智能吗?想象一下,如果一个人想要盖住你的眼睛,你会怎么做?我是会躲开的。但是从我刚才播放的视频中可以看到,现在的监控系统显然没有这样的举止。现在的人工智能只是机器学习:从大量的标注数据去学习一个映射。
什么是真正的智能?我想目前还没有定论,而且我们对我们自己的智能还没有足够的了解。不过我很认同瑞士认知科学家 Jean Piaget 说的,智能是当你不知道如何做的时候你用的东西。我认为这个定义是非常有道理的。当你无法用你学到的东西或天赋去面对时,你动用的东西就是智能。如何去实现有智能的系统呢?可能有很多条路,但我认为一条很重要的路是需要把载体考虑进去,做有载体的智能,也就是机器人。

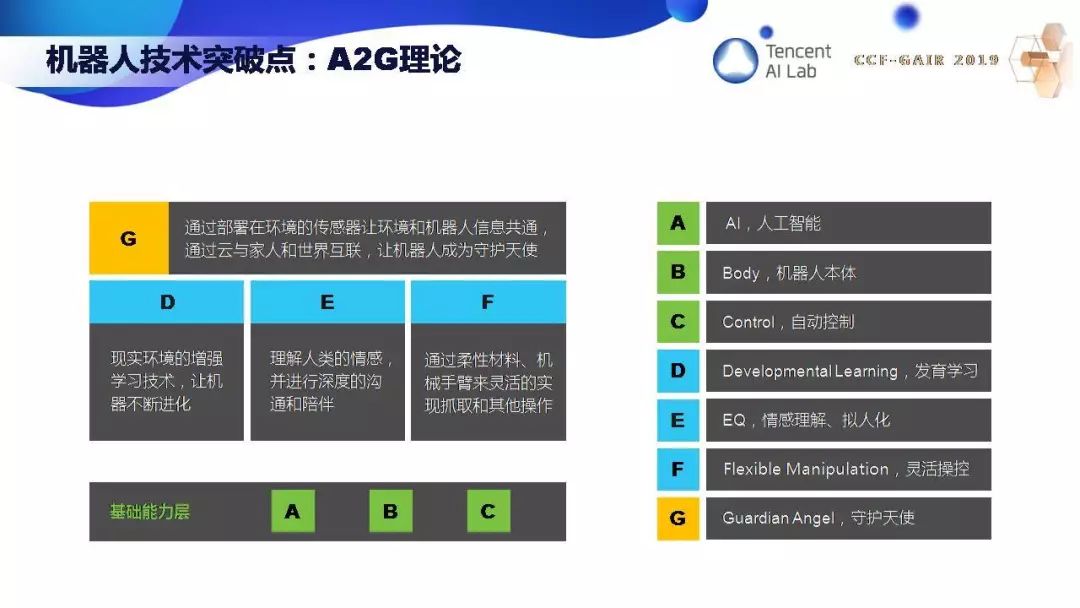
在机器人领域,我提出了 A2G 理论。A 是 AI,机器人必须能看能听能说能思考,B 是 Body 本体,C 是 Control 控制,ABC 组成了机器人的基础能力。D 是 Developmental Learning,发育学习,E 是 EQ,情感理解、拟人化,F 是 Flexible Manipulation,灵活操控。最后要达到 G,G 是 Guardian Angel,守护天使。
腾讯做了三款机器人:绝艺围棋机器人、桌上冰球机器人,还有机器狗。可以为大家展示机器狗的视频,机器狗具备感知系统,能够绕开障碍物,看到悬空的障碍物能匍匐前进,看到前面一个人能蹲下来看着人。
我的报告就到这里,腾讯的 AI 使命是 Make AI Everywhere,我们一定会善用人工智能,让人工智能造福人类,因为科技向善。谢谢大家。
-
机器视觉、工业视觉和计算机视觉这三者的关系2024-01-24 2677
-
什么是计算机视觉?计算机视觉的三种方法2023-11-16 6958
-
计算机视觉的基础概念和现实应用2022-11-08 2792
-
计算机视觉入门指南2020-11-27 3963
-
计算机视觉的发展历史_计算机视觉的应用方向2020-07-30 9289
-
行业 | 计算机视觉的三生三世2019-08-09 3325
-
张正友博士:做了题为「计算机视觉的三生三世」的大会报告2019-07-15 3804
-
计算机视觉的应用2019-04-04 9756
-
计算机视觉与机器视觉区别2018-12-08 14273
-
《三生三世》看不够?京东购魅族手机送小说2017-03-03 1002
-
【公布获奖名单】三生三世十里桃花,请来此处历劫,飞升上神2017-02-24 30541
-
松果处理器的三生三世,小米处理器能否看到十里桃花?2017-02-09 1162
-
计算机视觉讲义2010-03-19 1017
-
基于OpenCV的计算机视觉技术实现2009-11-23 2020
全部0条评论

快来发表一下你的评论吧 !
