

不同的人脸识别算法解析
描述
在人脸识别领域,有一些比较经典的算法,例如特征脸法(Eigenface)、局部二值模式法、Fisherface等,不过在这里选择了一个目前应用比较广泛且流行的方法作为示例,叫做OpenFace。当然,我们不做实际的测试,只是通过它来了解识别的原理。
OpenFace属于基于模型的方法,它是一个开源库,包含了landmark,head pose,Actionunions,eye gaze等功能,以及训练和检测所有源码的开源人脸框架。
在前面的步骤中,已经为大家介绍如何通过HOG的方法将图像中人脸的特征数据提取出来,也就是成功检测到了人脸。
这时又有一个问题,就是这个人脸的姿势好像不是那么“正”,同样一个人,如果她的姿势,面部的朝向不同,人类仍然能认出她来,而计算机可能就认不出了。
解决这个问题,有一个办法,就是检测人脸主要特征的特征点,然后根据这些特征点对人脸做对齐校准。这是Vahid Kazemi和Josephine Sullivan在2014年发明的方法,他们给人脸的重要部分选取68个特征点(Landmarks),这68个点的位置是固定的,所以只需要对系统进行一些训练,就能在任何脸部找到这68个点。
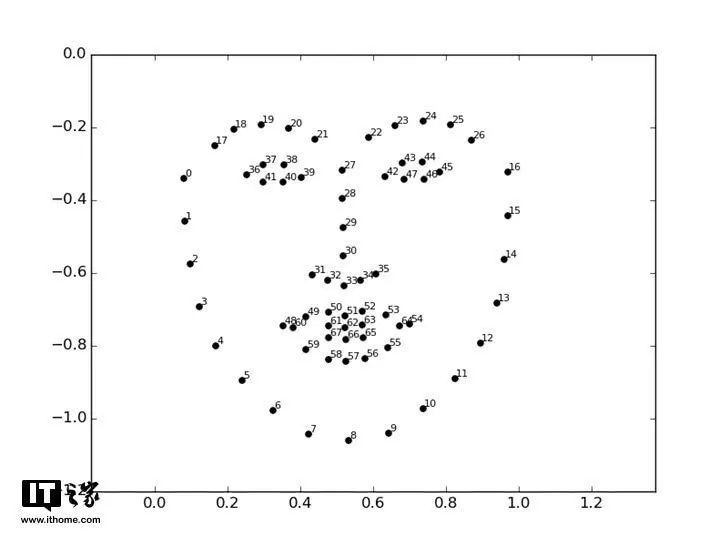
图片来源:OpenFace API
有了这68个点,就可以对人脸进行校正了,主要是通过仿射变换将原来比较歪的脸摆正,尽量消除误差。这里的仿射变换主要还是进行一些旋转、放大缩小或轻微的变形,而不是夸张的扭曲,那样就不能看了。
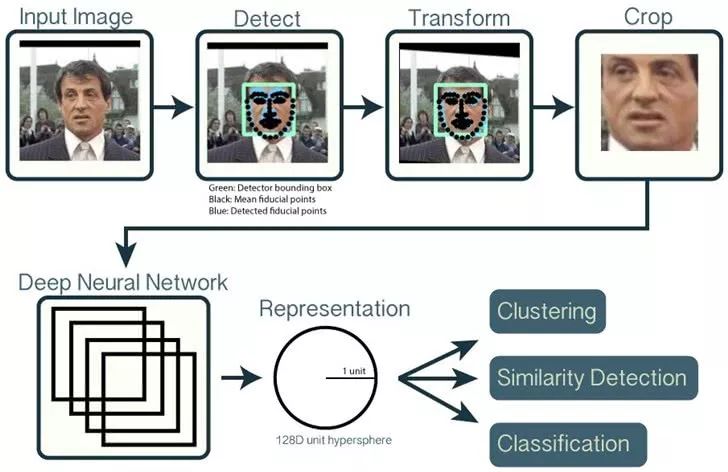
图片来源:OpenFace github说明页面
过程大约是这样,原来的脸被进行了一定程度的校正。
这样我们把原始的人脸图像以及HOG的特征向量输入,能够得到一张姿势正确的只含有人脸的图像。
注意,到这一步我们还不能直接拿这张人脸图像去进行比对,因为工作量太大,我们要做的是继续提取特征。
接着,我们将这个人脸图像再输入一个神经网络系统,让它为这个脸部生成128维的向量,也可以说是这个人脸的128个测量值,它们可以表示眼睛之间的距离,眼睛和眉毛的距离、耳朵的大小等等。这里只是方便大家理解而举例,实际上具体这128维的向量表示了哪些特征,我们不得而知。
当然,这一步说起来简单,其实难点在于如何训练这样的一个卷积神经网络。具体的训练方法不是我们需要了解的,但我们可以了解一下训练的思路。训练时我们可以输入一个人脸图像的向量表示、同一人脸不同姿态的向量表示和另一人脸的向量表示,反复进行类似的操作,并不断调整,调整的目标是让同一类对应的向量表示尽可能接近,其实也就是同一个人的向量表示尽可能距离较近,同理,不同类别的向量表示距离尽可能远。
其实训练的思路也很好理解,因为一个人的人脸不管姿态怎么变,在一段时间内有些东西是固定的,比如眼睛间的距离、耳朵的大小、鼻子的长度等。
在得到这128个测量值后,最后一步就简单了,就是将这128个测量值和我们训练、测试过的所有面部数据做比对,测量值最接近的,就是我们要识别的那个人了。这样就可以完成一次人脸的识别。
-
基于matlab的人脸检测K-L的人脸识别(肤色分割和特征提取)2012-02-22 168357
-
基于labview的人脸识别系统的设计………………2012-03-17 6843
-
基于openCV的人脸检测系统的设计2014-12-23 4898
-
【Z-turn Board试用体验】+ Z-Turn的人脸识别门禁系统项目开发(一)2015-06-26 10772
-
【TL6748 DSP申请】基于DSP的人脸识别技术2015-09-10 2895
-
人脸识别技术原理解析2016-12-23 14994
-
人脸识别算法如何提高劳动率?2018-12-27 3476
-
如何去实现一种基于PCA算法的人脸识别程序呢2021-11-04 1746
-
怎样去实现一种嵌入式linux上的人脸识别程序2021-12-23 1620
-
基于CSVD-NMF的人脸识别算法2009-03-30 866
-
人脸识别核心算法及技术解析2014-10-20 1788
-
人脸识别算法分析2017-10-28 7595
-
人脸识别算法原理2019-03-06 13338
-
算法推荐 |适用App的人脸识别算法选型及应用2020-10-26 3709
-
基于深度学习的人脸识别算法与其网络结构2021-03-12 4595
全部0条评论

快来发表一下你的评论吧 !
