

XGBoost原理概述 XGBoost和GBDT的区别
电子说
描述
作者 | 梁云1991
一、XGBoost和GBDT
xgboost是一种集成学习算法,属于3类常用的集成方法(bagging,boosting,stacking)中的boosting算法类别。它是一个加法模型,基模型一般选择树模型,但也可以选择其它类型的模型如逻辑回归等。
xgboost属于梯度提升树(GBDT)模型这个范畴,GBDT的基本想法是让新的基模型(GBDT以CART分类回归树为基模型)去拟合前面模型的偏差,从而不断将加法模型的偏差降低。相比于经典的GBDT,xgboost做了一些改进,从而在效果和性能上有明显的提升(划重点面试常考)。第一,GBDT将目标函数泰勒展开到一阶,而xgboost将目标函数泰勒展开到了二阶。保留了更多有关目标函数的信息,对提升效果有帮助。第二,GBDT是给新的基模型寻找新的拟合标签(前面加法模型的负梯度),而xgboost是给新的基模型寻找新的目标函数(目标函数关于新的基模型的二阶泰勒展开)。第三,xgboost加入了和叶子权重的L2正则化项,因而有利于模型获得更低的方差。第四,xgboost增加了自动处理缺失值特征的策略。通过把带缺失值样本分别划分到左子树或者右子树,比较两种方案下目标函数的优劣,从而自动对有缺失值的样本进行划分,无需对缺失特征进行填充预处理。
此外,xgboost还支持候选分位点切割,特征并行等,可以提升性能。
二、XGBoost原理概述
下面从假设空间,目标函数,优化算法3个角度对xgboost的原理进行概括性的介绍。
1,假设空间
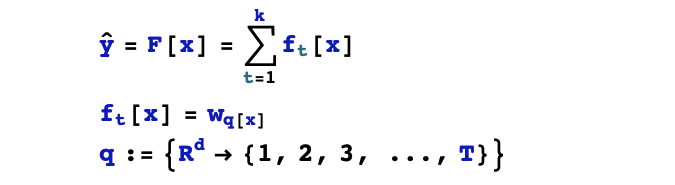
2,目标函数

3,优化算法
基本思想:贪心法,逐棵树进行学习,每棵树拟合之前模型的偏差。
三、第t棵树学什么?
要完成构建xgboost模型,我们需要确定以下一些事情。
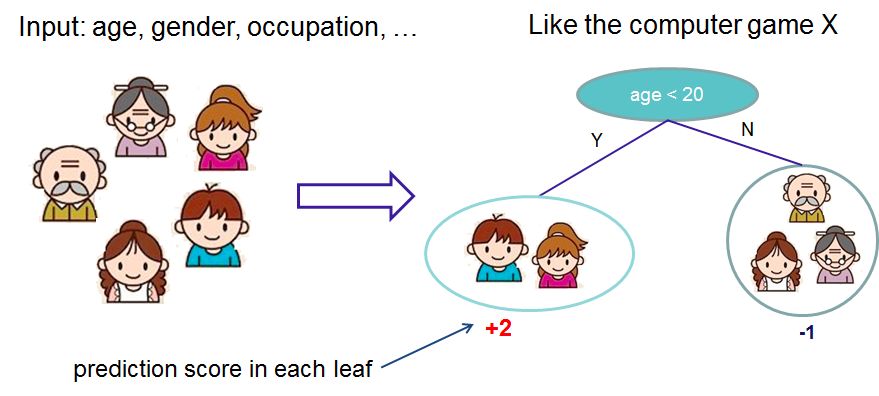
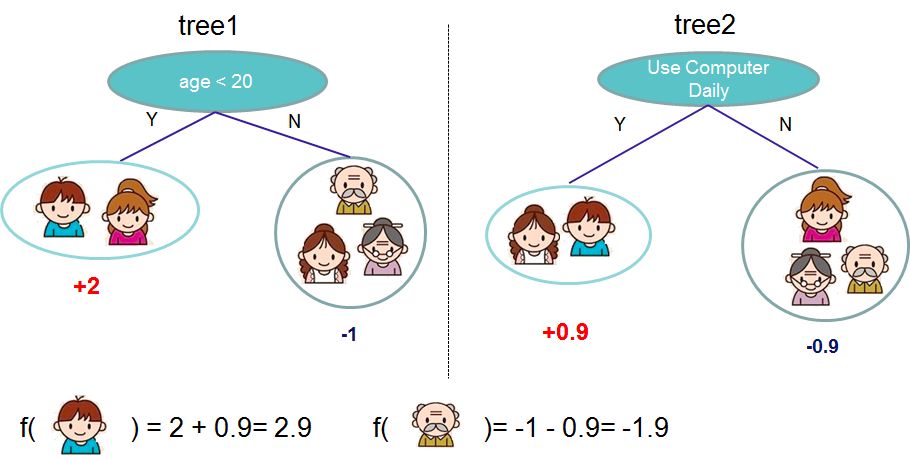
1,如何boost? 如果已经得到了前面t-1棵树构成的加法模型,如何确定第t棵树的学习目标?
2,如何生成树?已知第t棵树的学习目标的前提下,如何学习这棵树?具体又包括是否进行分裂?选择哪个特征进行分裂?选择什么分裂点位?分裂的叶子节点如何取值?
我们首先考虑如何boost的问题,顺便解决分裂的叶子节点如何取值的问题。
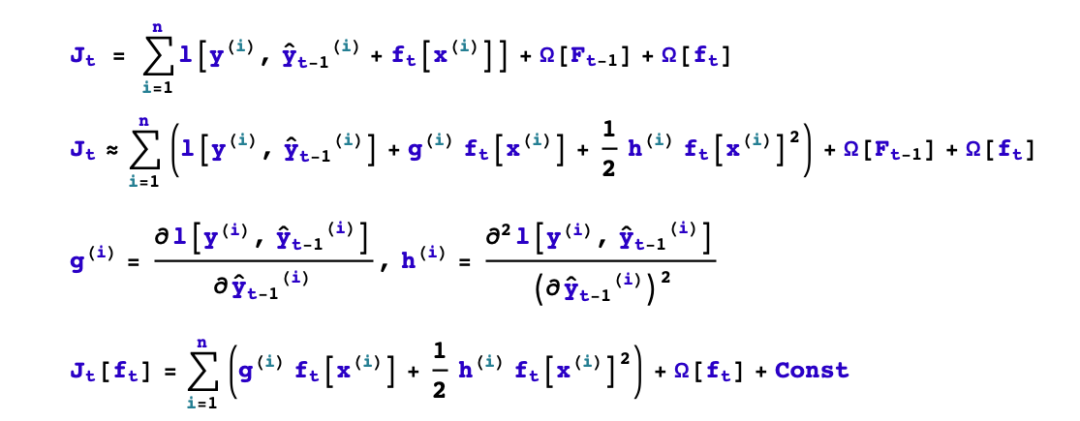


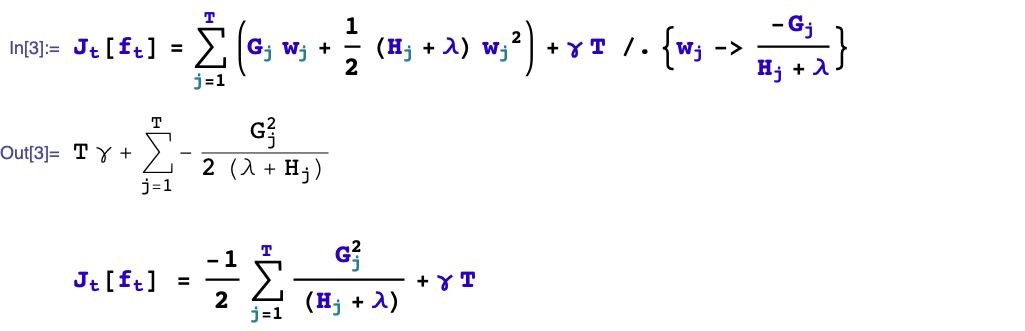
四、如何生成第t棵树?
xgboost采用二叉树,开始的时候,全部样本都在一个叶子节点上。然后叶子节点不断通过二分裂,逐渐生成一棵树。
xgboost使用levelwise的生成策略,即每次对同一层级的全部叶子节点尝试进行分裂。对叶子节点分裂生成树的过程有几个基本的问题:是否要进行分裂?选择哪个特征进行分裂?在特征的什么点位进行分裂?以及分裂后新的叶子上取什么值?叶子节点的取值问题前面已经解决了。我们重点讨论几个剩下的问题。
1,是否要进行分裂?
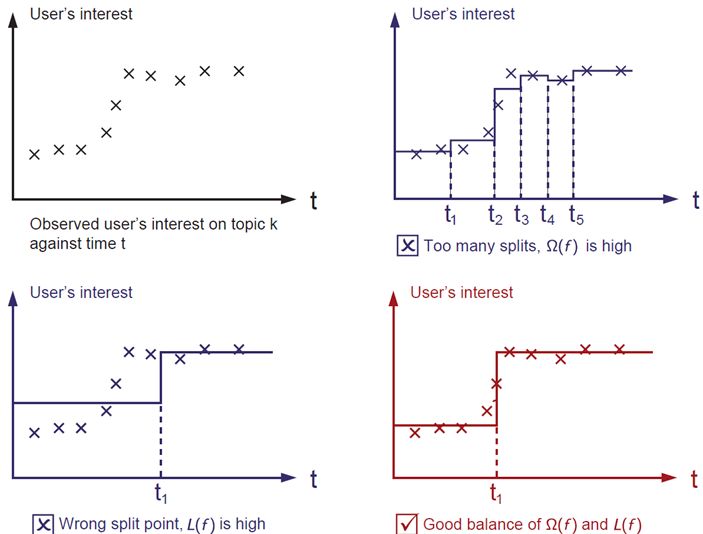
根据树的剪枝策略的不同,这个问题有两种不同的处理。如果是预剪枝策略,那么只有当存在某种分裂方式使得分裂后目标函数发生下降,才会进行分裂。但如果是后剪枝策略,则会无条件进行分裂,等树生成完成后,再从上而下检查树的各个分枝是否对目标函数下降产生正向贡献从而进行剪枝。xgboost采用预剪枝策略,只有分裂后的增益大于0才会进行分裂。
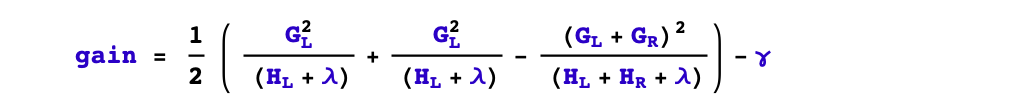
2,选择什么特征进行分裂?
xgboost采用特征并行的方法进行计算选择要分裂的特征,即用多个线程,尝试把各个特征都作为分裂的特征,找到各个特征的最优分割点,计算根据它们分裂后产生的增益,选择增益最大的那个特征作为分裂的特征。
3,选择什么分裂点位?
xgboost选择某个特征的分裂点位的方法有两种,一种是全局扫描法,另一种是候选分位点法。
全局扫描法将所有样本该特征的取值按从小到大排列,将所有可能的分裂位置都试一遍,找到其中增益最大的那个分裂点,其计算复杂度和叶子节点上的样本特征不同的取值个数成正比。
而候选分位点法是一种近似算法,仅选择常数个(如256个)候选分裂位置,然后从候选分裂位置中找出最优的那个。
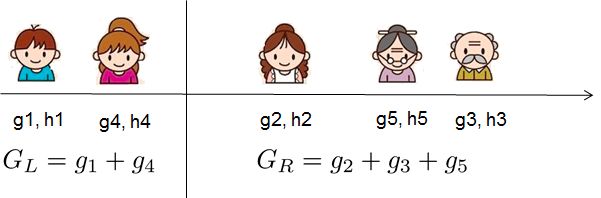
-
xgboost超参数调优技巧 xgboost在图像分类中的应用2025-01-31 2856
-
xgboost在图像分类中的应用2025-01-19 2022
-
XGBoost 2.0介绍2023-11-03 1336
-
XGBoost中无需手动编码的分类特征2023-07-05 1575
-
XGBoost超参数调优指南2023-06-15 1859
-
在几个AWS实例上运行的XGBoost和LightGBM的性能比较2022-10-24 2529
-
基于xgboost的风力发电机叶片结冰分类预测 精选资料下载2021-07-12 1242
-
基于Xgboost算法的高锰钢表面粗糙度预测2021-06-19 781
-
PyInstaller打包xgboost算法包等可能出现问题是什么2020-07-16 2950
-
面试中出现有关Xgboost总结2019-03-20 4828
-
通过学习PPT地址和xgboost导读和实战地址来对xgboost原理和应用分析2018-01-02 7261
全部0条评论

快来发表一下你的评论吧 !
