

谷歌深度神经网络 基于数据共享的快速训练方法
电子说
描述
导读:神经网络技术的普及离不开硬件技术的发展,GPU 和 TPU 等硬件型训练加速器带来的高算力极大的缩短了训练模型需要的时间,使得研究者们能在短时间内验证并调整想法,从而快速得到理想的模型。然而,在整个训练流程中,只有反向传播优化阶段在硬件加速器上完成,而其他的例如数据载入和数据预处理等过程则不受益于硬件加速器,因此逐渐成为了整个训练过程的瓶颈。本文应用数据共享和并行流水线的思想,在一个数据读入和预处理周期内多次重复使用上一次读入的数据进行训练,有效降低模型达到相同效果所需的总 epoch 次数,在算法层面实现对训练过程的加速。
网络训练的另一个瓶颈
网络训练速度的提升对神经网络的发展至关重要。过去的研究着重于如何在 GPU 和更专业的硬件设备上进行矩阵和张量的相关运算,从而代替 CPU 进行网络训练。GPU 和TPU 等相关专业计算硬件的通用性不像 CPU 那么广泛,但是由于特殊的设计和计算单元构造,能够在一些专门的任务中具有大幅超越 CPU 的表现。
由于 GPU 相关硬件善于进行矩阵和张量运算,因此通常用于训练中的反向传播计算过程,也就是参数优化过程。然而,一个完整的网络训练流程不应该只包含反向传播参数优化过程,还应该有数据的读入和预处理的过程,后者依赖于多种硬件指标,包括 CPU、硬盘、内存大小、内存带宽、网络带宽,而且在不同的任务中细节也不尽相同,很难专门为这个概念宽泛的过程设计专用的硬件加速器,因此其逐渐成为了神经网络训练过程中相对于方向传播过程的另一个瓶颈。
因此,如果要进一步提升训练速度,就需要考虑优化非硬件加速的相关任务,而不仅仅是优化反向传播过程,这一优化可以从两个方面来进行:
(1) 提升数据载入和预处理的速度,类似于提升运算速度
(2) 减少数据载入和预处理的工作量
其中第一个思路更多的需要在硬件层面进行改进,而第二个思路则可以通过并行计算和数据共享,重复利用的方法来实现。
并行化问题
在了解具体的训练优化方法之前,我们需要知道神经网络训练过程中的典型步骤,并做一些合理假设。下图是一个典型的神经网络训练流程:

图1 一种典型的神经网络训练流程
包含了 5 个步骤:read and decode 表示读入数据并解码,例如将图片数据重新 resize成相应的矩阵形式;Shuffle 表示数据打乱,即随机重新排列各个样本;augmentation 表示对数据进行变换和增强;batch 对数据按照 batch size 进行打包;Apply SGD update表示将数据输入到目标网络中,并利用基于 SGD 的优化算法进行参数学习。
不同的任务中或许会增加或减少某些环节,但大致上的流程就是由这5步构成的。此外,网络采用的学习优化算法也会有不同,但都是基于 SGD 算法的,因此一律用“SGD update”来表示。这个流程每次运行对应一个 epoch,因此其输入也就是整个训练数据集。
可并行化是这个过程的重要特点,也是对其进行优化的关键所在。不同的 epoch 流程之间的某些环节是可以同时进行的,例如在上一个 epoch 训练时,就可以同步的读入并处理下一个epoch 的数据。进一步地,作者将该流程划分为两个部分,上游(upstream)过程和下游(downstream)过程。其中上游过程包含数据载入和部分的数据预处理操作,而下游过程包含剩余的数据预处理操作和 SGD update 操作。这个划分并不是固定的,不同的划分决定了上游和下游过程的计算量和时间开销。这样划分后,可以简单地将并行操作理解为两个流水线并行处理,如下图:

图1 基础并行操作,idle表示空闲时间
上面的流水线处理上游过程,下面的处理下游过程。为了更好地表示对应关系,我在原图的基础上添加了一个红色箭头,表示左边的上游过程是为右边的下游过程提供数据的,他们共同构成一个 epoch 的完整训练流程,并且必须在完成这个 epoch 的上游过程后才可以开始其下游过程,而与左侧的上游过程竖直对应的下游过程则隶属于上一个 epoch了。
从图中可以看到,上游过程需要的时间是比下游过程更长的,因此在下游过程的流水线中有一部分时间(红色部分)是空闲的等待时间,这也是本文中的主要优化对象。此处做了第一个重要假设:上游过程的时间消耗大于下游过程,这使得训练所需时间完全取决于上游过程。如果是小于关系,那么优化的重点就会放到下游过程中,而下游过程中主要优化内容还是反向传播过程。因此这个假设是将优化内容集中在下游过程流水线的充分条件。
那么如何利用这部分空闲时间呢?答案是继续用来处理下游过程,如下图:

图2 单上游过程对应多下游过程
同一个上游过程可以为多个下游过程提供数据(图中是 2 个),通过在上游过程和下游过程的分界处添加一个额外的数据复制和分发操作,就可以实现相同的上游数据在多个下游过程中的重复利用,从而减少乃至消除下游过程流水线中的空闲时间。这样,在相同的训练时间里,虽然和图1中的一对一并行操作相比执行了相同次数的上游过程,但是下游过程的次数却提升了一定的倍数,模型获得了更多的训练次数,因此最终性能一定会有所提升。
那么进一步,如果要达到相同的模型性能,后者所需执行的上游过程势必比前者要少,因此从另个角度来讲,训练时间就得到了缩短,即达到相同性能所需的训练时间更少。
但是,由于同一个上游过程所生成的数据是完全相同的,而在不同的反向传播过程中使用完全相同的数据(repeated data),和使用完全不同的新数据(fresh data)相比,带来的性能提升在一定程度上是会打折扣的。这个问题有两个解决方法:
(1)由于下游过程并不是只包含最后的 SGD update 操作,还会包含之前的一些操作(只要不包含 read and encode 就可以),而诸如 shuffle 和 dropout 等具有随机性的操作会在一定程度上带来数据的差异性,因此合理的在下游过程中包含一些具有随机性的操作,就可以保证最后用于 SGD update 的数据具有多样性,这具体取决于上下游过程在整个流程中的分界点。
(2)在进行分发操作的同时对数据进行打乱,也能提高数据的多样性,但由于数据打乱的操作本身要消耗计算资源,因此这不是一个可以随意使用的方法。
我们将这种对上游过程的数据重复利用的算法称为数据交流 data echoing,而重复利用的次数为重复因子 echoing factor。
数据重复利用效率分析
假设在完成一个上游过程的时间内,可以至多并行地完成 R 个下游过程,而数据的实际重复使用次数为e,通常 e 和 R 满足 e
在此基础上,可以得到以下关于训练效率的结论:
(1)只要e不大于R,那么训练时间就完全取决于上游过程所需的时间,而总训练时间就取决于上游过程的次数,也就是第一条流水线的总时长。
(2)由于重复数据的效果没有新数据的效果好,因此要达到相同的模型性能,数据交流训练方法就需要更多的 SGD update操作,也就是需要更多下游过程。理论上,只要下游过程的扩张倍数小于e倍,那么数据交流训练方法所需的总训练时长就小于传统训练方法。
(3)由于e的上限是R,那么R越大,e就可以取得越大,在下游过程只包含SGD update过程时,R最大。进一步地,若此时重复数据和新数据对训练的贡献完全相同,那么训练加速效果将达到最大,即训练时间缩短为原来的1/R。
然而在前面已经提到了,对重复利用的数据而言,其效果是不可能和新数据媲美的,这是限制该训练方法效率的主要因素。作者进一步探究了在训练流程中的不同位置进行上下游过程分割和数据交流所带来的影响。
(1)批处理操作(batching)前后的数据交流
如果将批处理操作划分为下游过程,那么由于批处理操作本身具有一定的随机性,不同的下游过程就会对数据进行不同的打包操作,最后送到 SGD update 阶段的数据也就具备了一定的batch间的多样性。当然,如果将批处理操作划分为上游过程,那么R值会更大,可以执行更多次的SGD update 训练操作,当然这些训练过程的数据相似度就更高了,每次训练带来的性能提升也可能变得更少。
(2)数据增强(data augmentation)前后的数据交流
如果在 data augmentation 之前进行数据交流,那么每个下游过程最终用于训练的数据就更不相同,也更接近于新数据的效果,这个道理同批处理操作前后的数据交流是相同的,只不过数据交流操作的插入点更靠前,R值更小,带来的数据差异性也更强。
(3)在数据交流的同时进行数据打乱
数据打乱本质上也是在提升分发到不同下游过程的数据的多样性,但这是一个有开销的过程,根据应用环境的不同,能进行数据打乱的范围也不同。
进一步地,作者通过实验在5个不同的方面评估了数据交流训练方法带来的性能提升,并得到了以下结论:
(1)数据交流能降低训练模型达到相同效果所需的样本数量。由于对数据进行了重复使用,因此相应的所需新数据数量就会减少。
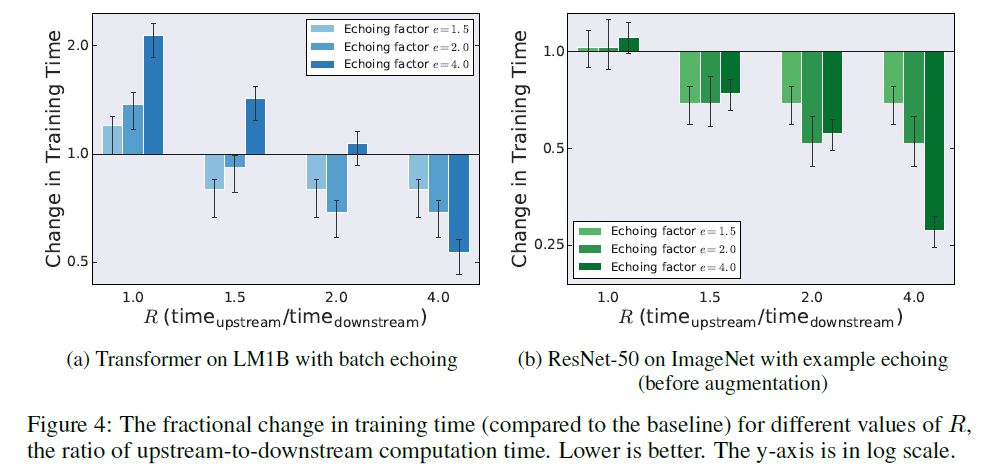
(2)数据交流能降低训练时间。事实上即便是 e>R,在某些网络上仍然会带来训练效果的提升,如下图:
图4 不同的e和R值在两个不同网络中带来的训练时间提升
在 LM1B 数据集中,当 e>R 是总训练时间都是扩大的,而在 ImageNet 数据集中,只要R 大于1.5, e 越大,训练时间就越小,作者并没有对这个结论给出解释,笔者认为这是以为因为在ImageNet 数据集中,重复数据带来的性能衰减 小于 重复训练带来的性能提升,因此,e 越大,达到相同性能所需的训练时间越少,只是 LMDB 对重复数据的敏感度更高。
(3)batch_size越大,能支持的e数量也就越大。进一步的,batch_size越大,所需要的训练数据也就越少。
(4)数据打乱操作可以提高最终训练效果,这是一个显而易见的结论。
(5)在数据交流的训练方法下,模型仍然能训练到和传统训练方法一样的精度,也就是不损失精度。作者在 4 个任务上进行了对比试验:
总结
本文的核心思想就是数据的重复利用,通过数据的重复利用在并行执行训练流程的过程中执行更多次的参数优化操作,一方面提高了流水线效率,另一方面提高了训练次数,从而降低了达到相同精度所需的训练时间。(作者 | Google Brain 译者 | 凯隐 责编 | 夕颜)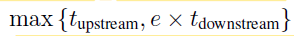
-
LSTM神经网络的训练数据准备方法2024-11-13 3600
-
ai大模型训练方法有哪些?2024-07-16 5480
-
怎么对神经网络重新训练2024-07-11 1614
-
卷积神经网络训练的是什么2024-07-03 2015
-
cnn卷积神经网络模型 卷积神经网络预测模型 生成卷积神经网络模型2023-08-21 2481
-
优化神经网络训练方法有哪些?2022-09-06 1762
-
卷积神经网络模型发展及应用2022-08-02 13391
-
时识科技提出新脉冲神经网络训练方法 助推类脑智能产业落地2022-06-20 2365
-
NVIDIA GPU加快深度神经网络训练和推断2022-02-18 3042
-
CV之YOLO:深度学习之计算机视觉神经网络tiny-yolo-5clessses训练自己的数据集全程记录2018-12-24 2834
-
基于虚拟化的多GPU深度神经网络训练框架2018-03-29 1247
-
基于粒子群优化的条件概率神经网络的训练方法2018-01-08 1457
-
叫板谷歌,亚马逊微软推出深度学习库 训练神经网络更加简单2018-01-05 5115
-
BP神经网络MapReduce训练2017-11-23 1398
全部0条评论

快来发表一下你的评论吧 !
