

不用写一行就带就可以参加 Kaggle,这个真香!
电子说
描述
【导读】给大家分享一些 Kaggle 上的资源,如 Kaggle 开放的数据集,也会分享一些好的竞赛方案或有意义的竞赛经验,帮助大家成长。今天,我们要给大家介绍的这个工具特别推荐给以往只能仰望别人的,缺乏竞赛技能和经验的朋友,你不需要写一行代码就可以参与 Kaggle 竞赛,甚至连安装环境都免了。是不是很神奇?下面我们一起 get 一下这个“真香”的工具!
参赛项目
Freesound Audio Tagging 2019
Kaggel 的竞赛项目 Freesound Audio Tagging 2019,同时也是 DCASE 2019 挑战赛的任务之一(Task 2),今天不对这个竞赛做过多介绍,感兴趣的朋友们可以通过我们下面给出的链接访问。
Freesound Audio Tagging 2019 是由 Freesound(MTG — Universitat Pompeu Fabra)和 Google 机器感知组举办的,数据通过 Freesound Annotator 收集,比赛参考论文:
(1)《Audio tagging with noisy labels and minimal supervision》
https://arxiv.org/pdf/1906.02975.pdf
(2)《FREESOUND DATASETS: A PLATFORM FOR THE CREATION OF OPEN AUDIO DATASETS》
https://ismir2017.smcnus.org/wp-content/uploads/2017/10/161_Paper.pdf
随着 AI 技术的不断发展与落地,有越来越多的平台和工具可供大家使用,这些平台针对不同领域、不同层次的开发者和学习者,只要你想学就有办法。但问题是,对于刚入门,没有多少经验,对 TensorFlow、PyTorch 等工具和框架也不熟悉的人,能参加这样的竞赛吗?
不会写代码,也不会 TensorFlow、PyTorch,怎么训练模型?
Peltarion 平台 你值得拥有,训练你的模型只需 5 步!
Peltarion 是怎样的一个平台?它部署在云端,在平台上你只需要简单的“拖拉拽”就可以从0到1完成一个 AI 模型的创建到部署。平台给初始者提供了免费使用50 小时、共有 50 GB 的 GPU 存储容量。

AI科技大本营也注册了一个账号,准备利用一下免费资源把模型跑起来。注册账号很简单,先用一个邮箱在平台上注册账号,然后在邮箱中完成验证,最后设置一个密码——done。接下来就可以开始进入“正餐”环节,为了能让大家使用该平台, 原作者和 Kaggle 竞赛联合起来,让大家可以边学边用。

具体步骤示例
0、获取数据集
模型预训练中要使用的数据集是 FSDKaggle 2019,已经在 Peltarion 平台经过预处理,所以音频文件经过转化,与 index.csv 一起保存为 Numpy 文件格式,所以,大家直接下载 dataset.zip 即可。
下载地址:
https://www.kaggle.com/carlthome/preprocess-freesound-data-to-train-with-peltarion/output

1、Project:一键创建
直接 New 一键即可建立一个新 project,可以保存为“project v1”。

2、数据集:Upload 或者 Import
新建的 project v1 在左侧就可以看到,点击 Datasets → New dataset 就可以上传数据集。然后选择刚刚下载的数据集,等待上传,最后命名保存为“Audio”。

默认 80% 的数据集作为训练集,其余 20% 用于测试集。在顶部的 New feature set 进行捆绑,除 fname 外所有的功能,保存为“Lable”。右上角保存 version 后,就可以进一步建模了。

3、Modeling:一键创建深度学习项目
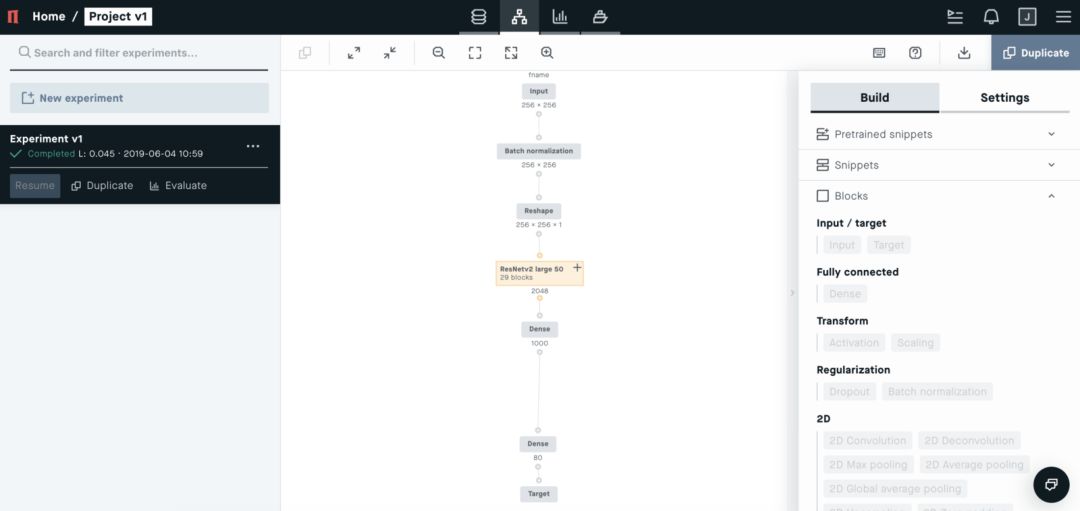
New Experiment 后进入 Modeling 界面,你可以在右侧看到“Build”和“Settings”两个工具选项帮助进行编译模型。在这个示例中,训练的是如下图所示的声谱图,以完成图片分类任务。
在该任务中,我们可以选择 CNN 网络模型,比如 ResNetv2 large 50。(右侧 Build-Snippets 中,有一些不同任务的模型可供选择。)
接下来几个步骤中,我们就在右侧栏中设定模型的关键配置:

(1)在 Blocks 中添加 Input,Feature 选择为 fname;
(2)添加 Batch normalization,勾选 Trainable;
(3)添加 Reshape,设置 Target Shape 为(256,256,1);
(4)在 Snippets 中添加 ResNetv2 large 50;
(5)单击并删除 ResNetv2 large 50 顶部“Input” 模块;
(6)将 BN 块连接到 ResNetv2 large 50 上
(7)更改 Dense 块 中 Activation 为 ReLU,ReLU 经常在模型中被选为激活函数;
(8)在 Target 块 之前再添加一个 Dense 块,节点设置为 80,激活 sigmoid;
(9)将 Target块 的 Feature 改为 Lable,Loss 为 Binary crossentropy;
(10)跳转到 Settings 选项卡,配置模型的步长、epoch、优化器等;Batch 设为 28,适合 GPU 内存、epoch 设为 30,模型足以收敛、Optimizer 选为 Adam,这是一个很常用的标准优化器;
(11)上面的配置都完成后,点击 RUN 就可以让模型跑起来了。

4、Evaluating
模型训练后,我们还需要对模型进行评估,在 Evaluating 界面,可以看到模型训练的实时数据,我们关注的指标是 Precision 和 Recall。模型训练完成后,可以直接下载,如果训练了多个模型,记得下载模型精度最高的。

5、提交模型

首先,进入竞赛页面。点击 New Kernel 连接到 Notebook,将下载的模型 H5 文件作为数据集添加。温馨提示:要使用正确的 H5 文件路径,添加下面这行代码到 Kaggle notebook 中运行,此处注意保存路径,后面会用到。
!find ../input-name '*.h5'
下面这段代码可以直接复制-粘贴到 Kaggle notebook 中;将模型变量路径更改为前面保存的路径,最后点击 Commit,完成。
import numpy as npimport pandas as pdimport librosa as lrimport tensorflow as tffrom tqdm import tqdmmodel = tf.keras.models.load_model('../input/freesound-audio-tagging-2019-model/resnet50.h5', compile=False) ##Changedf = pd.read_csv('../input/freesound-audio-tagging-2019/sample_submission.csv', index_col='fname') ##Changedef preprocess(wavfile): # Load roughly 8 seconds of audio. samples = 512*256 - 1 samplerate = 16000 waveform = lr.load(wavfile, samplerate, duration=samples/samplerate)[0] # Loop too short audio clips. if len(waveform) < samples: waveform = np.pad(waveform, (0, samples - len(waveform)), mode='wrap') # Convert audio to log-mel spectrogram. spectrogram = lr.feature.melspectrogram(waveform, samplerate, n_mels=256) spectrogram = lr.power_to_db(spectrogram) spectrogram = spectrogram.astype(np.float32) return spectrogramfor fname, scores in tqdm(df.iterrows(), total=len(df), desc='Predicting'): spectrogram = preprocess('../input/freesound-audio-tagging-2019/test/' + fname) scores = model.predict_on_batch(spectrogram[None, ...])[0] df.loc[fname] = scoresdf.to_csv('submission.csv')
竞赛地址:
https://www.kaggle.com/c/freesound-audio-tagging-2019
通过上面的示例,大家也发现了,训练模型的每一个步骤都在平台上内置好了,大家只需要托拉拽,勾勾选选的操作就可以训练你的模型了,另外还有一些免费的 GPU 资源、内存使用。对于代码不会写,框架不会写的你们来说简直不要太好用!营长的模型要准备跑起来了,你们的呢?
-
在VSCODE终端make时遇到错误要一行一行看然后定位,可以直接跳转点击或者VSCODE定位错误吗?2024-06-25 395
-
python如何将多行合并成一行2023-11-24 5559
-
esp32s3驱动RGB LCD可以看到每隔一行像素会显示一行全白色的像素横条的原因?2023-03-08 261
-
盘点10个一行强大的、有趣的Python源代码2020-10-08 9223
-
请问怎样能实现在一行显示指定数量的字符后换到下一行?2019-08-06 1989
-
请问生产线是用CCS来烧写芯片,不用写程序,也不用编译的功能,是不是用免费版的CCS就可以了?2018-11-01 3510
-
请问怎么依次发送这个二维数组的第一行第二行,之后跳转回来再发送第一行 第二行?2017-12-25 3478
-
怎样按照我的一个excel模版,一行一行的把数据写入而且上一行的数据不会消失。2017-12-21 5026
-
Labview 怎么用报表生成函数 一行一行自动换行写表格Excel2017-11-21 15518
-
第一行代码——Android2016-03-21 520
-
一个多行的字符串如何一行一行的执行然后一行一行的显示出来啊2015-06-30 8504
-
学带字库12864,看这个就可以了2014-09-28 4509
-
不用写一行程序,操作一次数据库,轻松作各种查询的方法2012-02-09 2104
全部0条评论

快来发表一下你的评论吧 !
