

Microsoft最新研究提基于关系网络的视觉建模
电子说
描述
导语:最近两年,自注意力机制、图和关系网络等模型在NLP领域刮起了一阵旋风,基于这些模型的Transformer、BERT、MASS等框架已逐渐成为NLP的主流方法。这些模型在计算机视觉领域是否能同样有用呢?近日,微软亚洲研究院视觉计算组主管研究员胡瀚受邀参加VALSE Webinar,分享了他们最近的一些相关工作。他们的研究以及同期的一些其它工作表明这些模型也能广泛地用于视觉基本元素之间关系的建模,包括物体与物体间、物体与像素间、以及像素与像素间的关系,特别是在建模像素与像素间关系上,既能与卷积操作形成互补,甚至有望能取代卷积操作,实现最基本的图像特征提取。
大脑和机器智能都应是通用学习机器
首先,我们从一个很有意思的实验讲起,这个实验将老鼠大脑里的听觉皮层接到视觉的输入上,经过一段时间训练后,发现听觉皮层也能实现视觉的感知任务。这个实验引起我们思考一个问题,机器智能是否同样能实现结构和学习的通用性呢?
目前的机器学习范式基本是统一的,一般遵循收集数据、进行标注、定义网络结构、以及利用方向传播算法训练网络权值的过程,但是不同任务里用到的基本模型却是多样的。当前计算机视觉主要被卷积网络所主导,而自然语言处理则经历了LSTM、GRU、卷积以及自注意等多种模型阶段。那是否有一种基本模型,能解决视觉、NLP、图结构数据感知、甚至推理等不同智能任务呢?
目前最通用的模型:关系和图网络
目前来看,关系网络是最接近这一目标的一种模型。在解释这个模型之前,我们首先对一些名词作一些澄清,包括图神经网络以及自注意力机制。
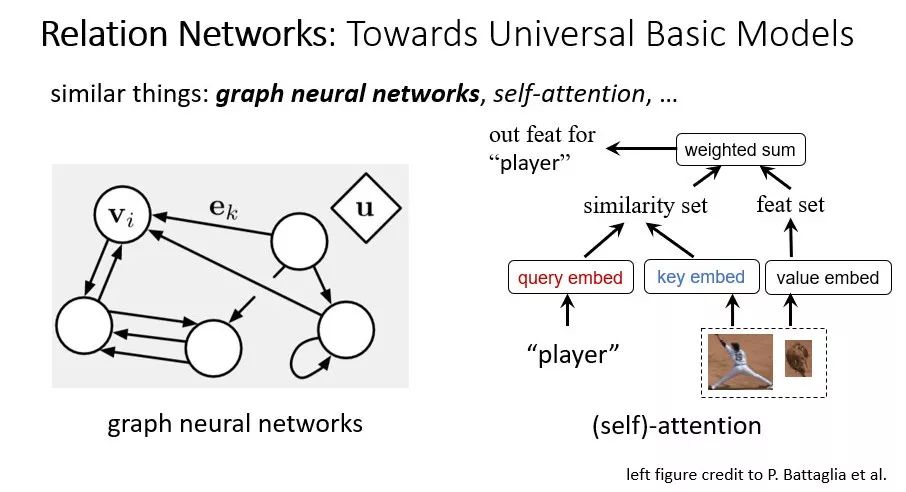
图1:关系网络架构
图神经网络概念上更通用一些,包括了对节点、对边、对全局属性的特征表示,而自注意模型则是图神经网络的一种特殊实现,里面只对节点进行了特征表示,而边(也就是关系)则通过key嵌入和query嵌入后的内积计算得到,是一种图为全连接时(所有节点之间都有连接)非常经济的模型,但表达能力又足够强,因为任何事物和概念之间都可以通过不同的投影后(key和query)的特征来使得两者可比。
注意力机制里key和query的集合往往不一致,例如分别是单词集合和图像块集合,或者分别是不同语言的句子,而自注意力机制则是key和query的对象为同一集合的情况。最近在NLP领域的革命,主要在于发现了“自”注意力机制在编码同一句子单词与单词之间关系上的价值。而关系网络和图神经网络还有自注意力机制从实现上是同样的,字面上更关注对于节点与节点间联系的建模。
将关系网络应用于基本视觉建模
考虑到关系网络在图结构数据和NLP序列数据建模上取得了巨大成功,很自然的一个问题是这一建模方法是否也适用于视觉里的建模。计算机视觉里面主要涉及两个层次的基本元素:一个是物体;一个是像素。于是我们研究了物体和物体、物体和像素以及像素和像素的关系建模问题。
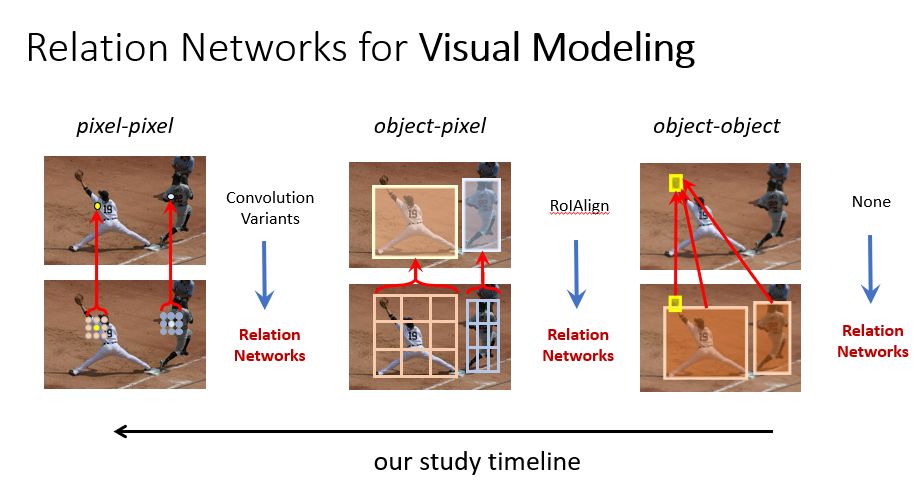
图2:将关系网络应用于基本视觉建模
物体与物体关系建模,第一个完全端到端的物体检测器
物体是很多视觉感知任务的核心,在深度学习时代,单个物体的感知有了很好的进展,但如何去建模物体与物体间的关系却一直没有很好的工具。我们在去年CVPR上提出了一个能即插即用的物体关系模块(Object Relation Module),简称ORM。物体关系模块的建模基本上是一种自注意力机制的应用,和基本的自注意力机制的主要不同在于添加了相对几何项,我们发现这一项对于视觉问题来说很重要,物体之间的相对位置关系能帮助对于物体本身的感知。这一模块可以很方便地嵌入到现有的物体检测框架(图3所示是目前应用最广泛的Faster R-CNN算法),去改进头部(head)网络,以及替换手工的去重模块,也就是目前通常采用的非极大化抑制方法(NMS)。其中替换前者使得物体不是独立识别的,而是一起识别的,而替换后者则帮助实现了第一个完全的端到端物体检测系统。我们还将物体关系模块推广到时空维度,去解决多目标跟踪问题。
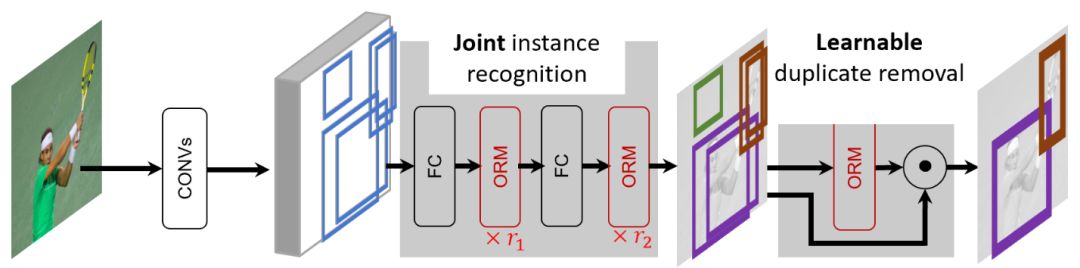
图3:第一个完全端到端的物体检测器
物体与像素关系建模
物体与像素关系建模的一个最直接的应用是从图像特征里提取物体区域特征,此前最常用的算法是RoIPooling或者RoIAlign,我们用关系网络实现了自适应地从图像特征里提取区域特征的方法,并证明这一方法比RoIAlign在物体检测的标准数据集COCO上要好1 mAP左右。
像素与像素关系建模,替代卷积的局部关系网络及全局上下文网络
像素与像素关系的建模可以用来实现最基本的图像局部特征提取,也可以用来提取图像的全局信息,从而作为基本图像特征提取网络(例如卷积神经网络)的补充。
1)替代卷积神经网络的局部关系网络
现在的基本图像特征提取方法几乎都采用卷积算子,但卷积本质上是一个模板匹配(template matching)算子,效率是偏低的,例如图4中的三个鸟头,很简单的变化,却需要三个通道来去建模它。我们提出了一个局部关系层(local relation layer)来实现更高效的图像特征提取,它本质上还是基于关系网络。在应用到基本的像素与像素关系建模问题时,我们发现如下几个细节很重要:一是关系的建模要限制在局部内,只有限制在局部才能构造信息瓶颈,才能把图像里的模式学出来;二是需要引入可学习的几何先验项,这一项的引入也是注意到目前最流行的卷积算子所采用的模板匹配过程就是严重依赖相对位置关系的建模方法;三是采用标量的key和query,在标准的关系网络中,key和query通常是用向量表示的,采用标量的key和query能节省很多参数和计算,也因此能在有限计算量情况下建模多种关系。
与卷积相比,局部关系层概念上最大的不同是它是在根据两个像素自己的特征来计算像素间的可组合性,而不是用一个全局的模板来作匹配。图4右上还显示了学到的部分key和query图(标量),从左到右分别是由浅到深的层,发现浅层学到了边缘和内部的概念,深层学到了不同物体的概念。图4右下显示了学到的几何先验,从上到下分别是由浅到深的层,发现在浅层里几何先验比较集中和稀疏,暗示几何先验起很大作用,而深层里几何先验比较模糊,暗示key和query起更主要的作用。

图4:局部关系层
局部关系层可以用来替换卷积网络里面所有的空间卷积层,包括所有的3x3的卷积,以及一开始的7x7卷积,于是得到了一个完全没有空间卷积层的网络,我们称为局部关系网络(LR-Net),图5左侧是用局部关系层替代ResNet-50网络中所有卷积层的例子,在相同计算量情况下,LR-Net相比于ResNet拥有更少的参数。图5右侧是26层LR-Net与26层带标准卷积或depthwise卷积的ResNet在ImageNet分类上top-1准确率的比较。可以看出,在不包含任何几何先验的情况下,LR-Net已与ResNet相匹敌,而在添加几何先验项后,与标准卷积的ResNet-50相比能取得高2.7%的性能。此外,局部关系网络在邻域为7x7时表现最好,而对应的标准ResNet网络则在3x3和5x5时表现更好,这表明局部关系网络相比普通基于卷积算子的ResNet网络能建模更大范围的像素关系。
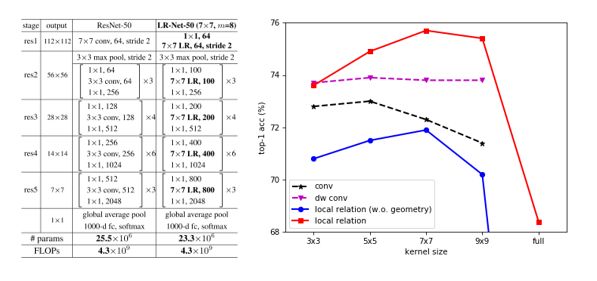
图5:局部关系层替代ResNet-50网络中所有卷积层(左);26层的LR-Net与ResNet相同运算量下在ImageNet分类上top-1准确率的对比(右)
2) 非局部网络遇上SE-Net,更高效的全局上下文网络
非局部关系网络在多个视觉感知任务上取得了非常好的效果,学界通常认为这得益于非局部网络对于远距离像素与像素间关系的建模。但我们在可视化学到的像素与像素间相似度时发现一个很不一样的现象,对于不同的query像素点(图中红色点),不管query像素点在前景、或是草地、或是天空中,它们和key像素的相似度形成的attention map几乎一模一样。
图6:不同query像素点对应的attention map
很自然地,如果我们显示地让所有query像素点共享同一个attention map,是否会降低performance呢?我们实验发现在一些重要的感知任务,例如图像分类、物体检测、动作识别中,这一答案是否定的。也就是说,即使让所有query像素点共享同一个attention map,也不会降低识别的精度,而相应的计算则大幅降低,即使添加到ResNet网络中所有的residual block后也不怎么增加网络整体的计算量。
进一步可以发现这样一种简化的非局部网络(SNL)和2017年ImageNet比赛的冠军算法SE-Net结构很相似,都是首先建模全局上下文信息,把HxW的图像特征集合起来,生成一个全局的向量,第二步都是对这一全局的向量作特征变换,最后是变换后的全局特征和图像每个位置原来的特征融合起来,于是可以抽象出来一个通用的建模全局上下文信息的框架。进一步的,在每一步里面选择最好的实现,于是可以得到全局上下文模块(Global Context Block),这一网络可以在COCO物体检测,ImageNet图像分类,和动作识别任务中均取得比非局部网络和SE-Net更优的准确率,而计算量则保持基本不变或者低于非局部网络和SE-Net。
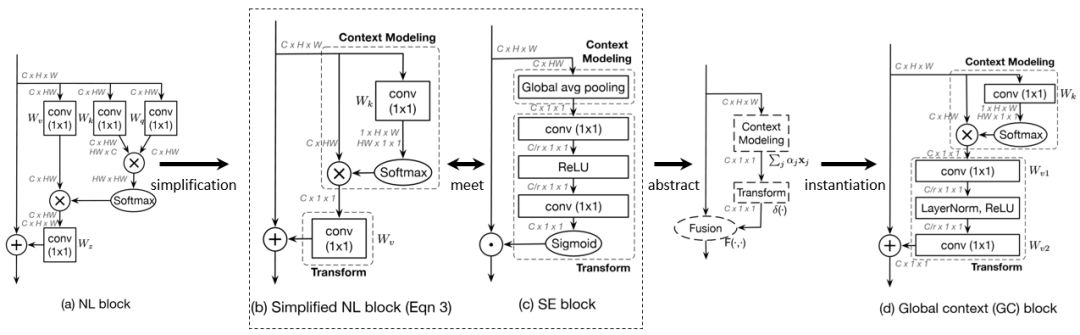
图7:通用的建模全局上下文信息的框架
-
分布式电源分配网络建模及去耦设计研究2024-09-19 493
-
射频功放的建模资料2023-09-22 611
-
在使用ICCAP进行建模提参时 可以修改调用公式的某个参数吗?2021-06-25 2206
-
多关系网络的社团结构发现算法综述2021-06-11 1115
-
基于用户关系网络的用户重要性评估方法2021-04-26 743
-
探索IEC标准的关系网资料下载2021-04-23 1436
-
复杂网络建模中的优先连接机制相关研究2021-03-18 1180
-
用Python制作编程语言的关系网络图2018-11-02 6162
-
图数据中蕴藏着秘密 神经网络中的结构化学习2018-05-28 5942
-
基于PLSR局部形状关系建模的颅面复原方法2017-12-22 685
-
人类互作网络拓扑模块分析2017-12-13 978
-
射频放大器建模及研究2017-11-23 1536
-
基于人工神经网络的转轮除湿系统建模方法研究_丛华2016-12-29 824
-
片上网络的SystemC建模研究2013-07-30 1450
全部0条评论

快来发表一下你的评论吧 !
