

循环神经网络卷积神经网络注意力文本生成变换器编码器序列表征
电子说
描述
本笔记基于斯坦福大学2019年冬季CS224N最新课程:基于深度学习的自然语言处理,希望可以接触到最前沿的进展。
主要内容
今天的主题是 Transformer。Transformer 不是变形金刚,但是比变形金刚更强大。这里暂时译作变换器。
序列表征循环神经网络卷积神经网络注意力文本生成变换器编码器自注意力解码器自注意力残差的重要性图像生成概率图像生成结合注意力和局部性音乐变换器音乐的原始表征音乐的语言模型音乐生成示例音乐中的自相似性平移不变性相对注意和图消息传递神经网络总结和展望自注意力研究热点迁移学习优化和加大模型其他自注意力研究正在进行未来展望下节预告阅读更多
序列表征
机器学习之前的首要任务是了解数据集是什么结构,数据集是否对称,模型是否具有归纳偏见来拟合数据集的这些属性等等。
通过这一节,我们会看到自注意力确实能够模拟归纳偏见,而归纳偏见对解决问题是有用的。
循环神经网络
大多数据都是不等长数据。处理不等长数据的主力模型是循环神经网络(RNN)。RNN天生适合处理句子和像素序列。LSTM、GRU等变体是主要的RNN模型。
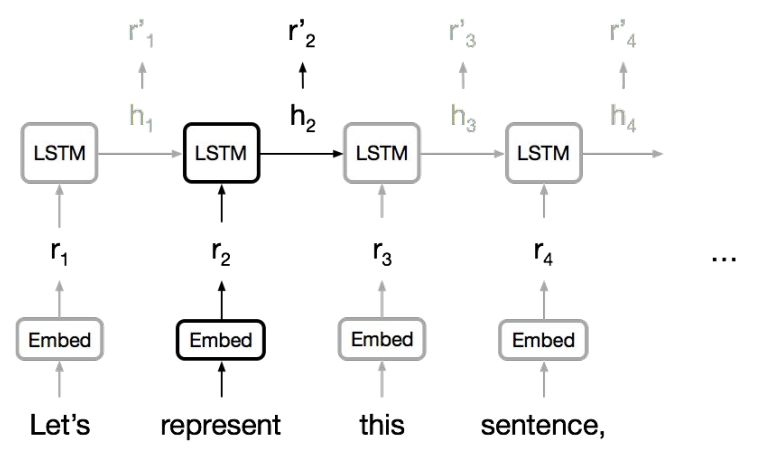
RNN
RNN通常按照顺序接收一个字符串、一个句子甚至一个图像,然后在每一步产生一个连续表征,这个连续表征汇总了这一步之前处理的所有信息。但是:
RNN必须等待上一步完成,才能继续下一步。这不利于并行计算。(当然并行计算越强,也会吸纳更多数据,最后拖慢并行计算)
RNN很难把指代信息等各种长程、短程依赖信息挤压到固定大小的向量中。
RNN无法对语言中的结构层次进行建模。
卷积神经网络
在自注意力(self-attention)之前,卷积序列模型(CNN)在某种程度上克服了以上部分困难。
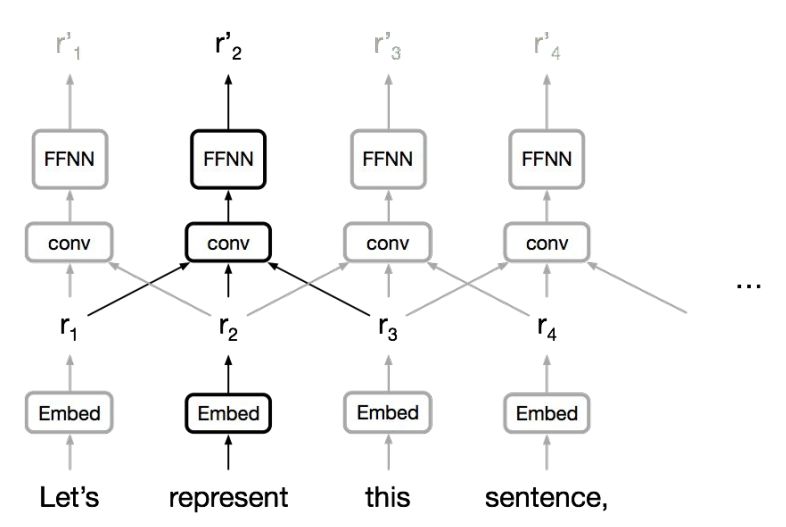
CNN
CNN可以在每个位置同时运用卷积,易于并行化。
CNN可以充分利用局部依赖关系
两个位置之间的“交互距离”是线性或对数的
长程依赖通过增加网络深度实现
注意力
编码器和解码器之间的注意力机制是神经机器翻译取得突破的关键部件。
注意力是基于内容的记忆提取机制。
既然如此,为什么不将注意力用于表征学习?
下图是注意力的大体框架:
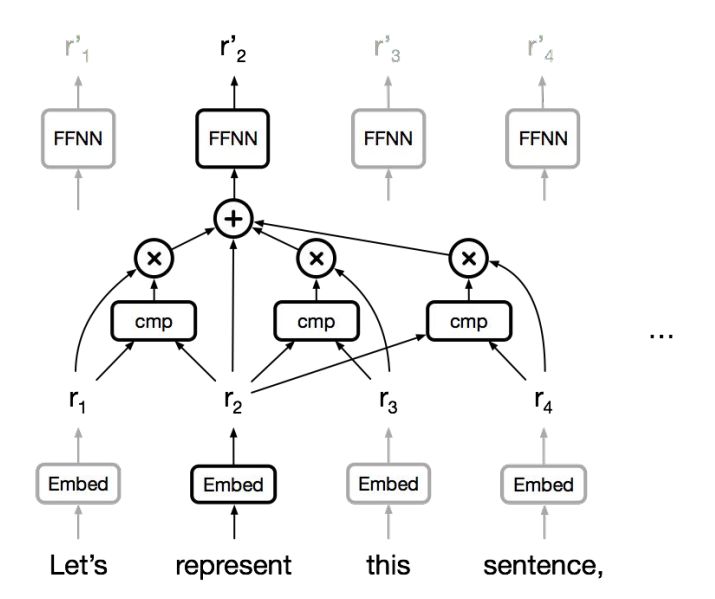
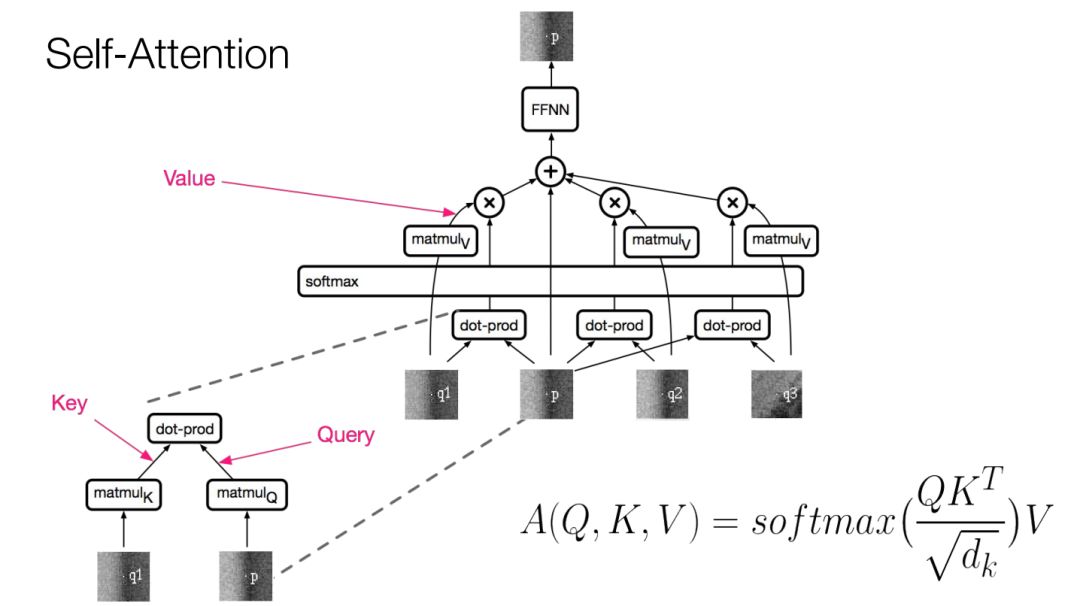
自注意力
如果想重新表征某个单词,可先将这个单词与周围所有单词作比较,然后得到周围所有单词的加权组合,即所有信息的汇总。这就是注意力机制的原理。当然还可以添加前馈层,计算新的特征。
文本生成
自注意力在文本生成中起到了很大作用。
注意力允许一个单词直接与任何位置的单词交互,任何两个位置之间的路径距离是固定的。
注意力通过softmax实现门控/乘法交互
注意力易于并行化
我们知道卷积序列到序列的文本生成已经非常成功,那么注意力表征学习能否成为主力呢?
注意力在大型机器翻译系统或大型文本生成系统中管用吗?
变换器
变换器(Transformer)是自注意力的集大成者。
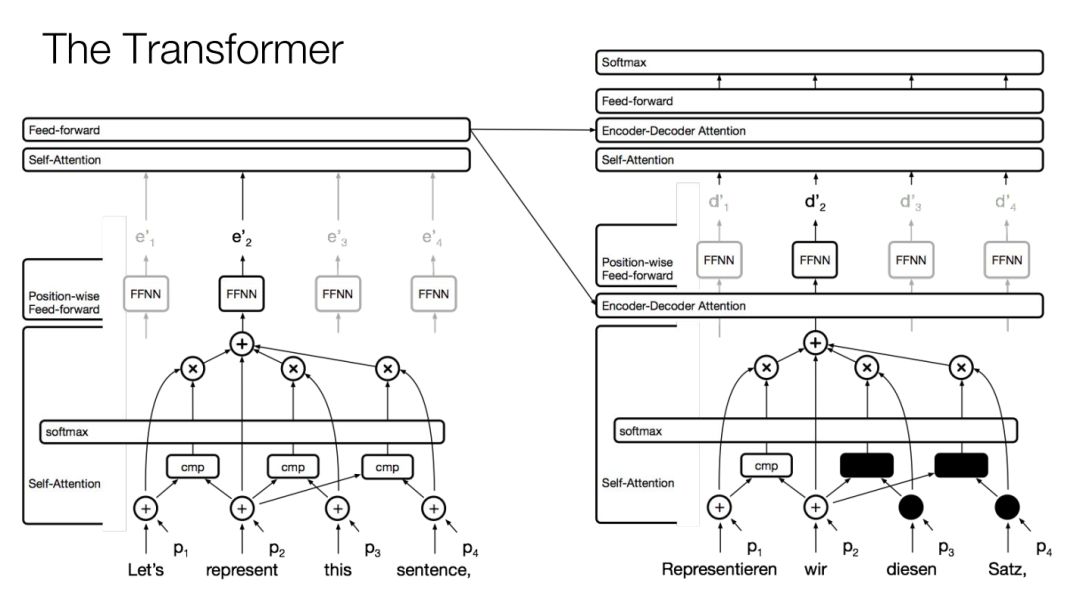
变换器
假如现在是英德翻译。使用的是标准的编码器-解码器架构。
编码器侧:
首先是自注意力层,用于同步计算每个位置的表征。然后是前馈层。中间各层有残差连接。这些结构会重复若干次。
注意:改变单词顺序不会影响注意力的实际输出。为了保持顺序,需要增加位置表征。
解码器侧:
首先是用自注意力模仿的语言模型。但是要掩盖掉之后看见的位置。比如,第一个位置不能看见后续的位置。
然后是编码器-解码器注意力层(实际关注的是编码器最后的注意力层和前馈层),重复若干层。最后是标准的交叉熵损失。
编码器自注意力
那么如何计算注意力呢?
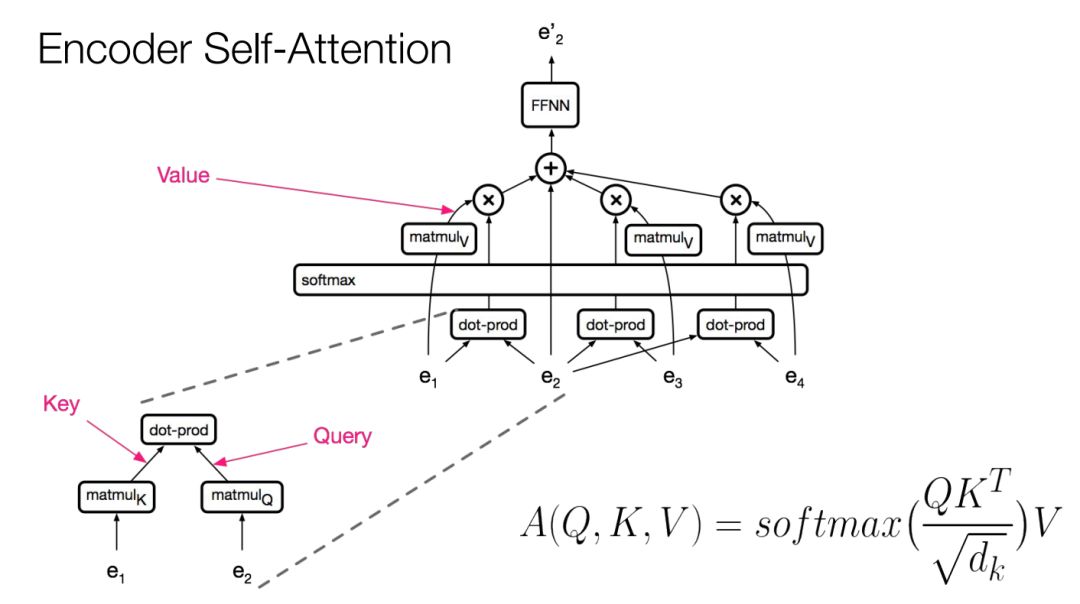
编码器自注意力
假设现在要计算位置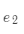 的表征。
的表征。
首先对查询(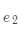 )作线性变换。
)作线性变换。
然后对输入的所有位置(键)作线性变换。
做点乘和softmax,最后计算所有这些位置的向量的凸组合。在凸组合之前,要对值作线性变换。
接着再作一次线性变换,整合这些信息,送入前馈层。
所有这些运算可用两个矩阵相乘表示,平方根系数是缩放因子,防止点乘爆炸。
解码器自注意力
解码器侧大致相同。
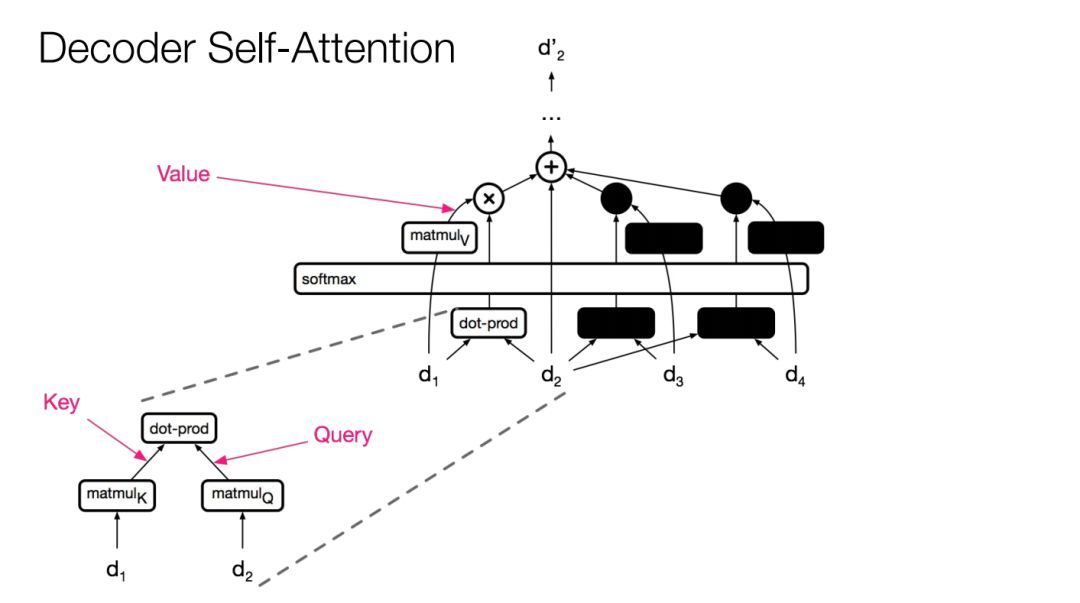
解码器自注意力
不同点是将掩盖位置的logit设为非常大的负数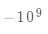 ,让这些位置的概率变成0。
,让这些位置的概率变成0。
注意力成本低廉!尤其当维度远远大于长度时。

length=1000 dim=1000 kernel_width=3
注意力虽好,但仍有一个问题。在语言中,我们通常想知道主语、谓语和宾语。
假设现在运用了一个卷积滤波器。实际上,根据相对位置,会有不同的线性变换。
比如绿色线性变换能从I的词嵌入拾取主语信息;红色线性变换能从kicked拾取谓语信息;蓝色线性变换能从ball拾取宾语信息。如下图所示:
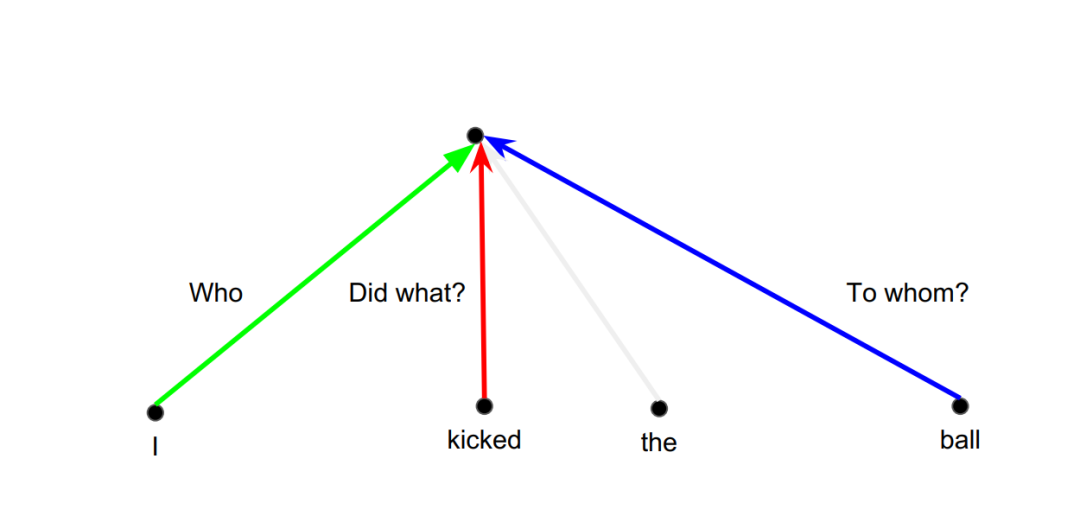
卷积
但是单个注意力层不一样,无法做到这一点。
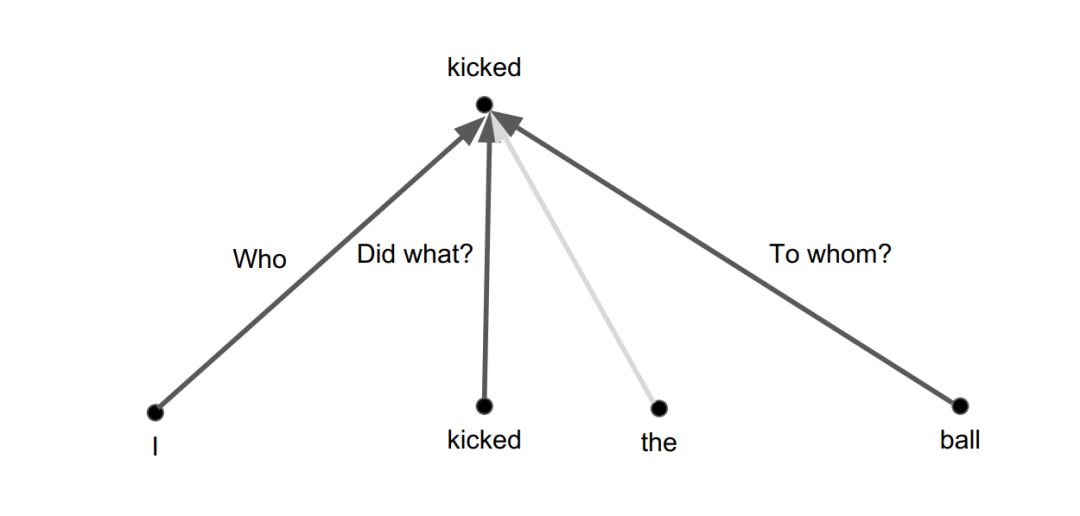
自注意力:平均
注意力是凸组合,线性变换处处相同。注意力提供的是混合比例,无法从不同位置拾取不同信息。
假如现在有一个主语注意力层:
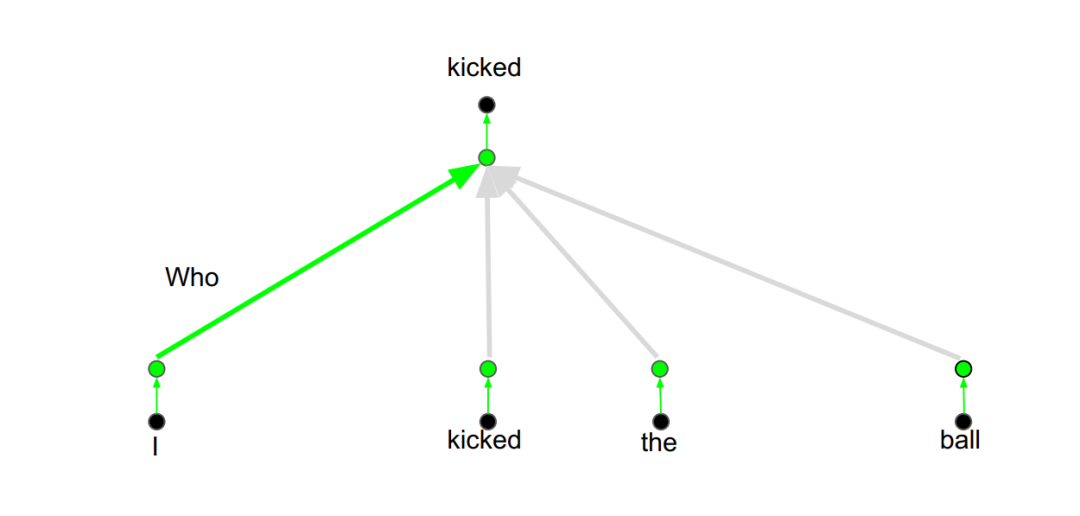
注意力头:关注主语信息
注意力层相当于特征检测器。注意力承载着一个线性变换,会投射到关注句法的空间,比如关注主语或宾语的空间。
我们可以增加其他注意力层,也叫注意力头,用于关注谓语信息:
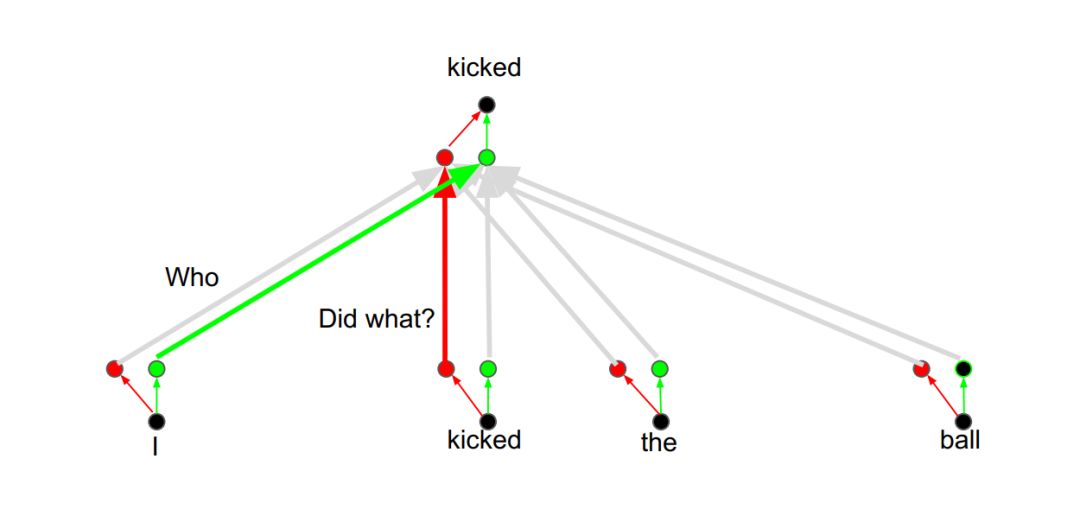
注意力头:关注谓语信息
还可以再增加注意力头,用于关注宾语信息:
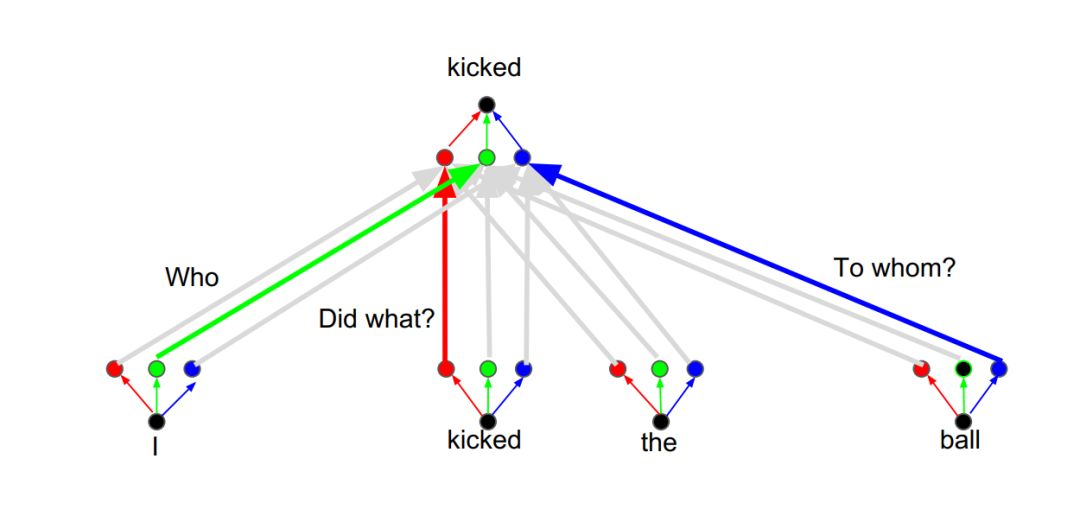
注意力头:关注宾语信息
所有这些都可以并行完成。
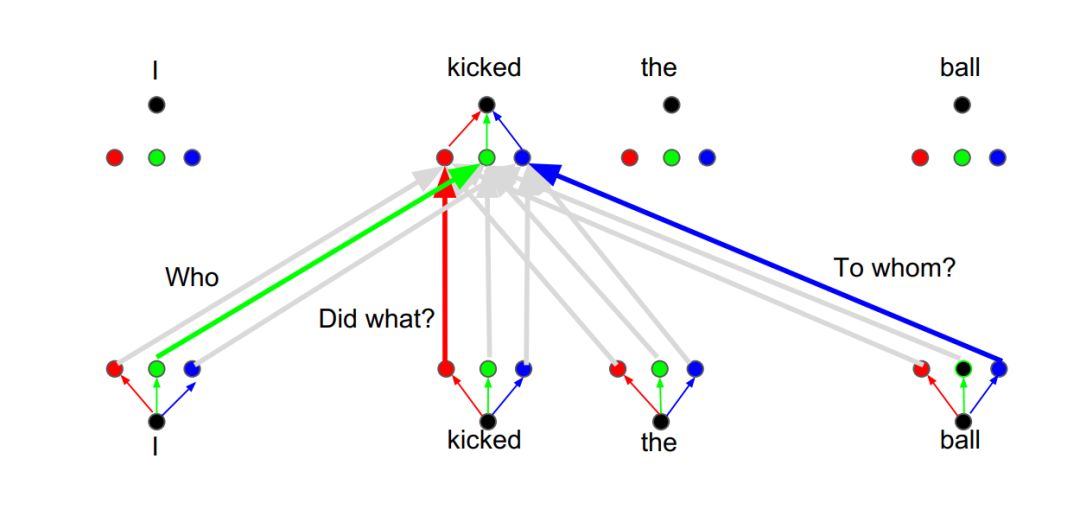
平行注意力头
为了提高效率,我们会降低注意力头的维度。
如果注意力头是位置的函数,注意力几乎可以模拟卷积。虽然增加了softmax,但计算量并未增加。因为中间有降维处理。
在机器翻译中,变换器效果远超之前的方法。
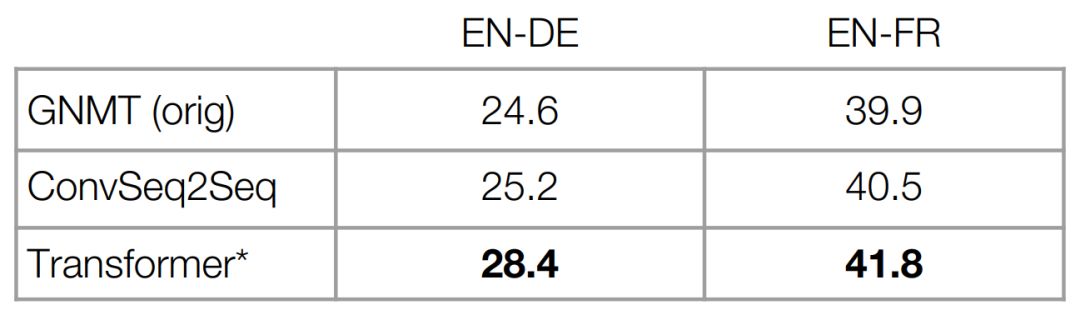
变换器效果
但是这里的意思并不是说注意力架构比LSTM具有更好的表现力。
理论证明,LSTM可以模拟任何函数。也许注意力架构只是便于随机梯度下降(SGD)。
有一点需要指出:注意力确实可以直接对任何两个词语之间的关系进行建模。
残差的重要性
在 变换器 架构中,层与层之间都有残差连接,并且只在模型输入中加入位置信息,不会在每一层都注入位置信息。
如左图所示,残差可以带来非常强的对角聚焦。

残差的重要性
当把残差连接切断时,得到的注意力分布如中间图所示。显然,没有残差就无法拾取到对角线。
残差可以将位置信息携带至更高层,使后续层也有位置概念。
但如果切断残差,在每一层都添加位置信息,虽然不能准确恢复,但至少能在一定程度找回对角聚焦。如右图所示。
所以残差效果更好,残差能更好地传递位置信息。
综上,注意力可以模拟长短程关系,有利于文本生成。
图像生成
在图像和音乐中,我们经常看到某些相似结构或归纳偏见会不断重复。
图像中的自相似
这些主题会在不同尺度上重度。
在下面梵高的油画中,这些球状结构就是自相似性。
梵高:繁星之夜
它们会不断重复,但又具有不同尺度。
音乐也是一样,主题有时会立即重复,有时会在后面重复。
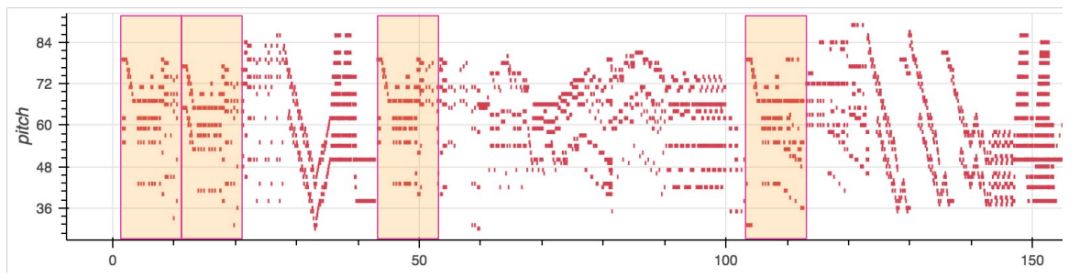
音乐中的自相似
概率图像生成
那么,注意力机制能否有助于生成图像和音乐?
方法是沿用标准的图像模型或概率图像模型,并转换成序列模型,相当于图像中的语言模型。
RNN(PixelCNN)和CNN(PixelRNN)都达到一流水平。融合门控机制的CNN与RNN不相上下。CNN由于并行化速度要快得多。
但是,对于图像而言,长程依赖(如对称性)也很重要,尤其随着图像尺寸不断变大,其重要性也与日俱增。
用CNN模拟长程依赖需要:
增加层数,这会增加训练难度
增大内核,这会增加参数和计算代价
但是注意力能减少层数,降低计算代价,同时获得遥远像素之间的依赖关系。
1999 年 Efros 和 Leung 在训练集中找到自相似的像斑,然后用于补充信息。

纹理合成
这相当于在做图像生成。
实际上,历史上真有一种图像降噪的方法,叫非局部均值。如果要给下图像斑p降噪,那么需要计算该像斑与图像中其他像斑的相似度,然后据此拉取信息。如下图所示:
非局部均值法
这里的底层逻辑是:图像具有非常高的自相似性。
现在,我们可以直接套用编码器自注意力机制,只需将词向量换成像斑。如下图所示:
图像自注意力
这是一种可微的非局部均值法。
图像变换器(Image Transformer)与之前的变换器结构如出一辙。
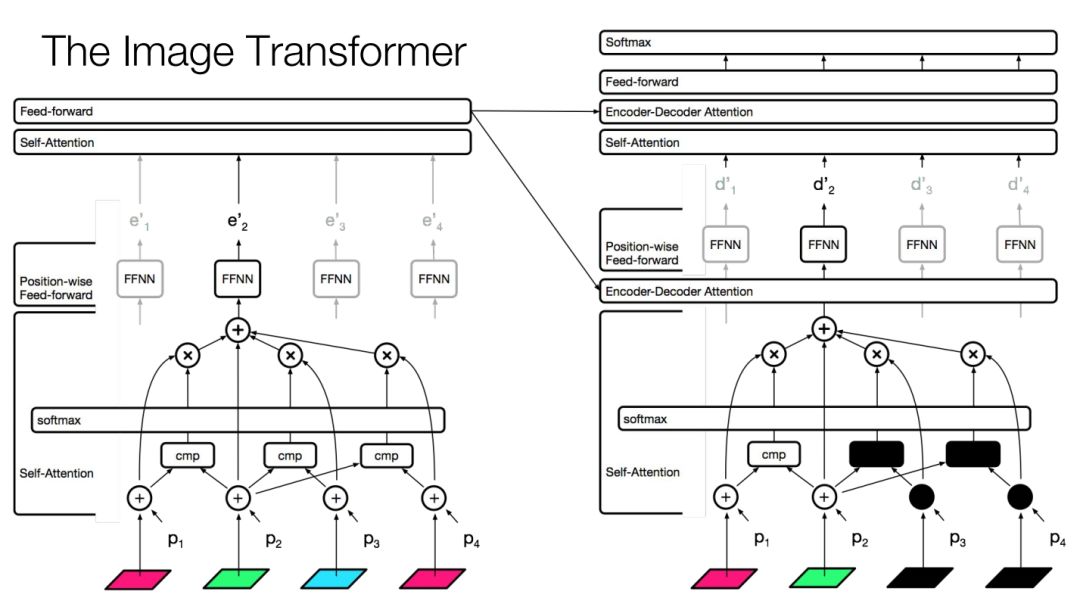
图像变换器
这里使用二维位置表征。
结合注意力和局部性
图像拉平后,长度一般很长。即使32x32的图像,拉平后也有1024像素,这限制了注意力机制。
简单的办法是像卷积一样,使用局部窗口。由于图像具有空间局部性,将注意力窗口限制在局部邻域,仍然可以获得较好的效果。
第二种方法是光栅化。
光栅化分成一维和二维。
在一维光栅化中,单个查询块沿着横向对记忆块做注意力。
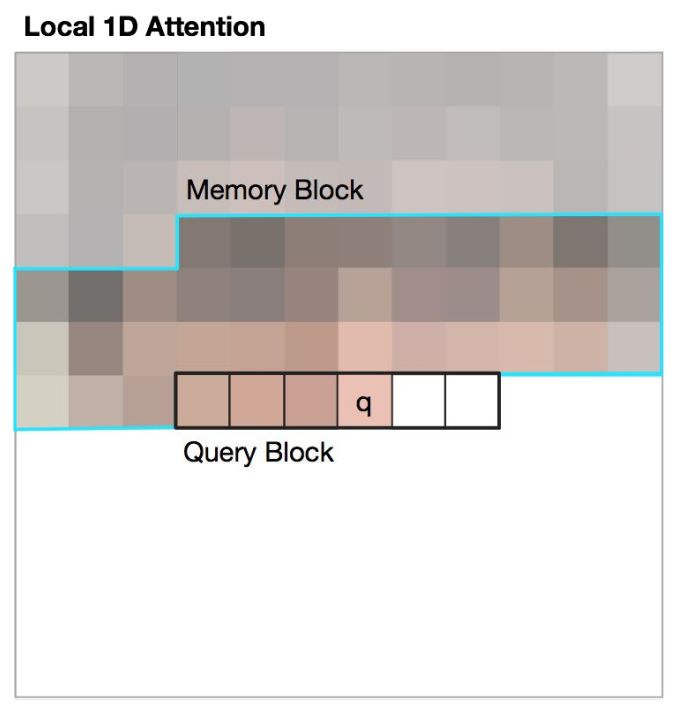
局部一维注意力
在二维光栅化中,仍然沿用标准的二维局部性,这实际上是在按块生成图像。
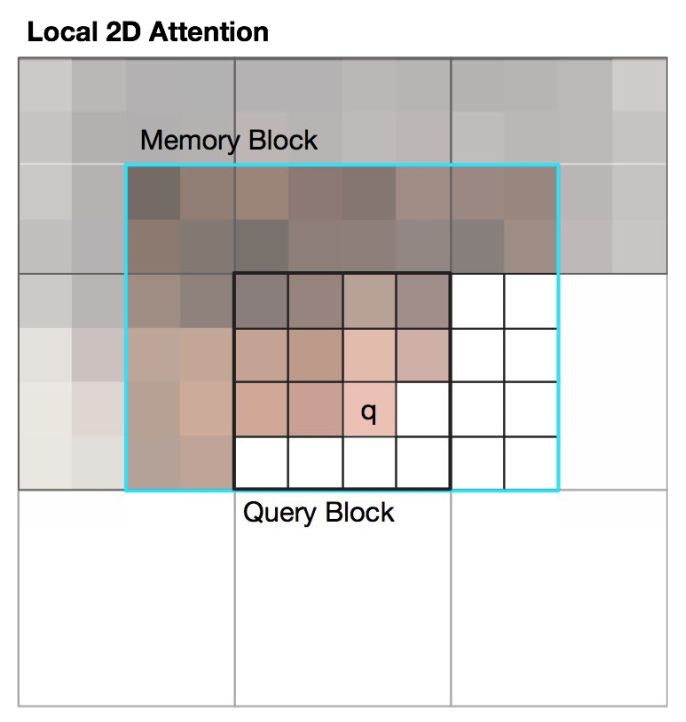
局部二维注意力
这些图像变换器都非常类似:
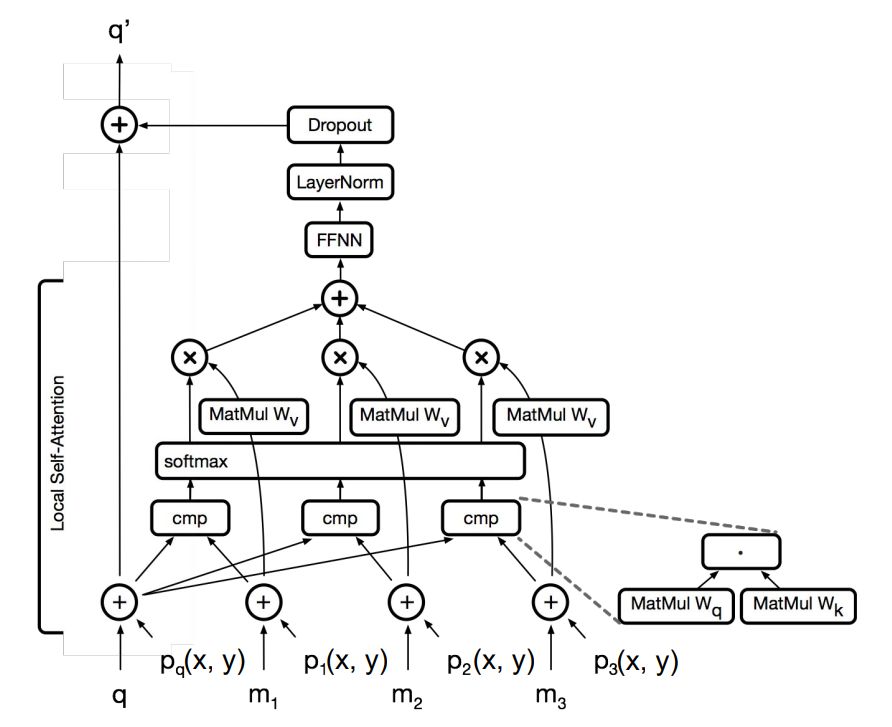
图像变形器层
下图是非条件图像生成模型效果对比:
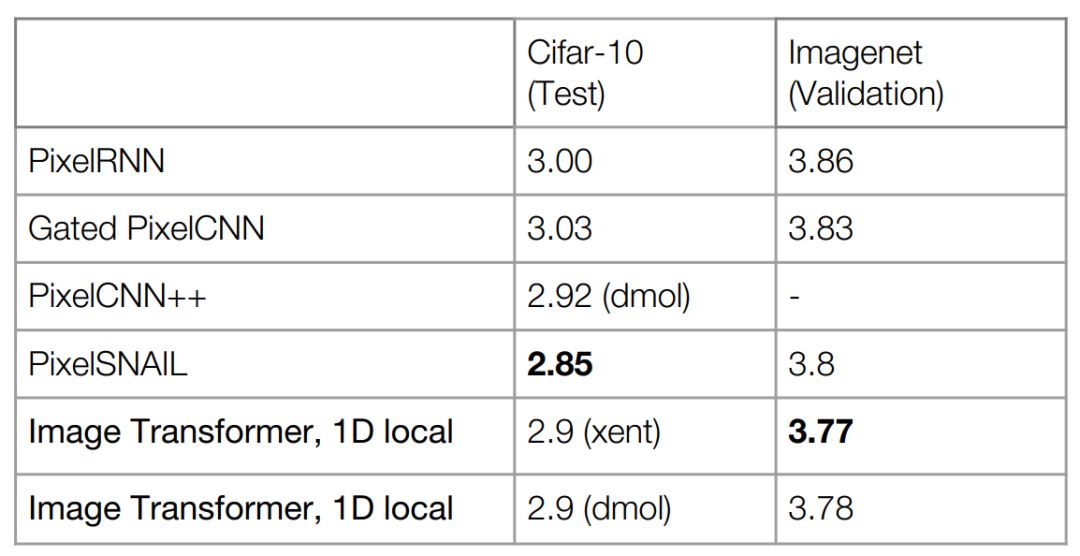
非条件图像生成
图像变换器可以获得更低的困惑度。但PixelSNAIL融合了卷积和注意力,所以效果超过了图像变换器。之所以使用困惑度度量,是因为这些是概率模型,相当于图像中的语言模型。语言模型如何分解仅仅取决于如何光栅化。在一维光栅化中,先行后列。在二维光栅化中,先块,然后在每块内光栅化。
如下图所示,注意力可以很好地捕获结构化对象。虽然还没有达到GAN的水平。
Cifar10样本
在超清图像生成中,需要大量条件信息,这时会锁定不少模式,所以输出端的选项会非常有限。
如下图所示,变换器的图像生成效果也好得多。可以得到更好的面部定位和结构。下图是不同温度下的样本。
CelebA超清图像
图像生成使用人工评测。变换器生成的假照片欺骗率差不多是之前成果的4倍。如下表所示:

CelebA超清图像
当然,这些成果与英伟达最新的GAN成果相比,简直是小巫见大巫。没办法,起步晚,希望能赶上来。
这里的重点是两个问题:
模型能否捕获某些结构?
模型能否提供多样性?极大似然本质上能提供多样性。
于是设计了填图任务。为什么是填图任务?因为一旦确定一半图像,实际上去掉了很多可能的模式。这样更容易采样。
在下图中,第一列是模型输入,最右侧是真实图片。
条件图像生成
看第三行最左侧这匹马,乍一看,像是有人在拉。而模型输出的某些图像也确实有人影。模型,或者数据告诉模型要捕捉世界的某种结构。
再看第四行的小狗。模型拒绝想像整个椅子。
可见,图像生成仍然充满困难。
音乐变换器(Music Transformer)
图像有很多自相似,音乐也有很多自相似。
可以想见,变换器应该也适用于音乐生成。接下来会对自注意力做个扩展,即增加相对信息,以便用于音乐生成。
音乐的原始表征
先来看一看音乐的原始表征。
我们用语言作类比。
一段文本,经朗读后,会形成声音。
音乐也是类似。
作曲家产生创意,写下乐谱,演奏者演奏(显示为MIDI钢琴卷帘),再经过合成器后,形成音乐。如下图所示:
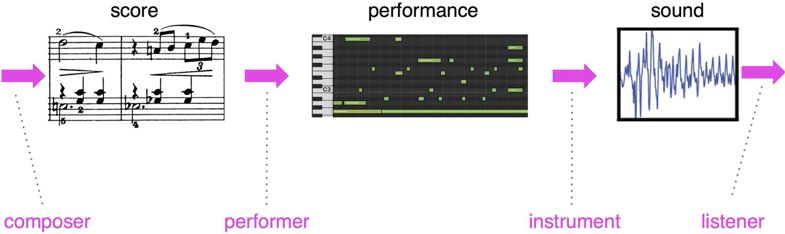
音乐生成分解
本节的主要关注点是乐谱,但其实是演奏。演奏是数字钢琴的符号化表征。所以演奏的相关信息可以记录下来。
音乐的语言模型
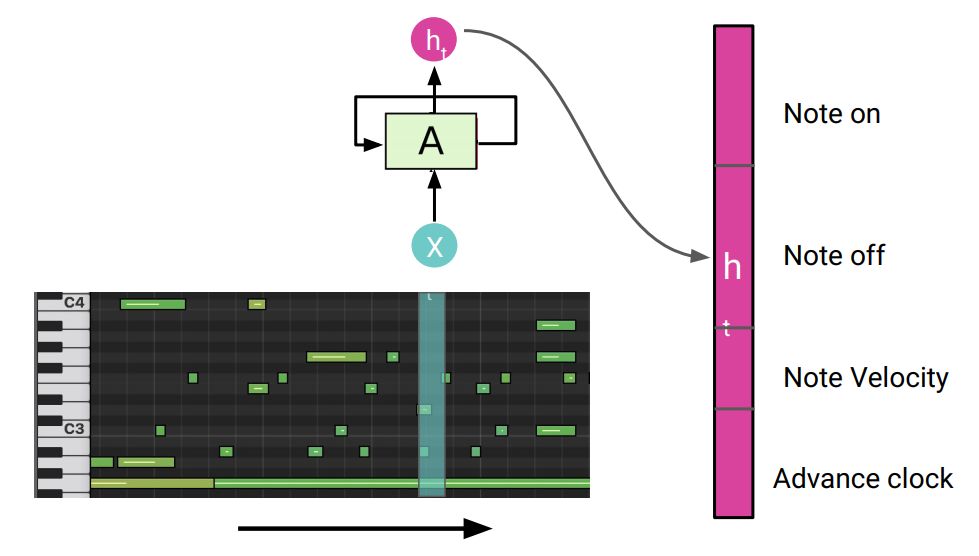
演奏RNN
具体而言,音乐序列模型的每一步输出是打开音符、推进时钟、关闭音符诸如此类的动态信息。
传统上都把音乐当作语言进行建模,因此大都使用循环神经网络。
但这涉及到大量的压缩,需要将较长序列挤压成固定长度的向量。如果音乐重复距离很长,这种挤压就变得非常困难。
音乐生成示例
接下来分别给出RNN、变换器、音乐变换器生成的示例。先听一听有什么区别,然后介绍对变换器做的改进。
给定的主题是肖邦练习曲片段:
 起始主题
起始主题
使用RNN做的生成:

RNN音乐生成
可以看到,在刚刚开始的时候,模型能够能够很好得重复主题,但很快就跑偏了。所以在经过较长距离后,RNN对于过去的记忆越来越模糊。
接下来是变换器做的生成:
注意模型训练时的长度是所听长度的一半,希望模型能对更长长度进行泛化。
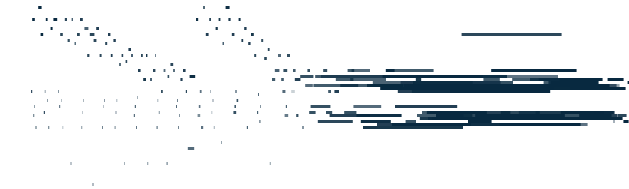
普通变换器音乐生成
可以看到,在开始的时候,模型能够能够很好得重复主题,但当超出训练长度后,模型效果开始变差,不知道如何应对更长的音乐背景。
最后是音乐变换器做的生成:
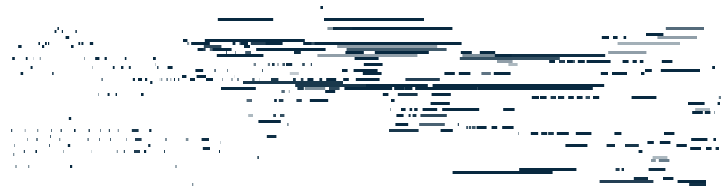
音乐变换器音乐生成
可以直观地看到,模型能够非常好得保持主题一致。
音乐中的自相似性
我们之前谈到音乐的自相似性。从下面这张图可以看到很多重复。
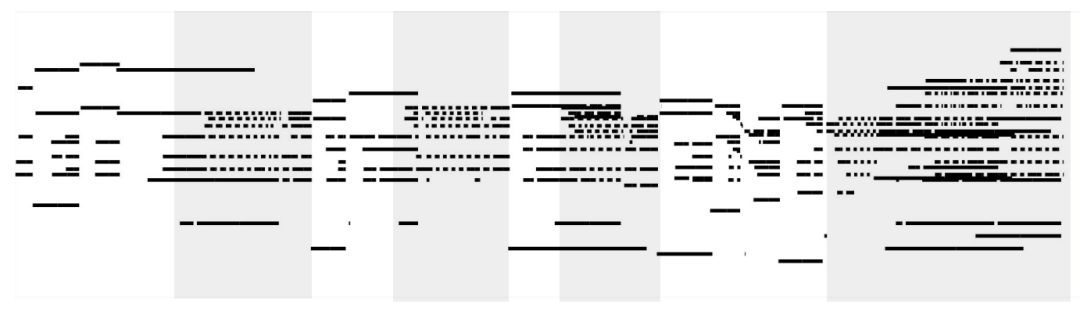
音乐中的自相似性
再看看自注意力结构,模型的确注意到了相关部分。
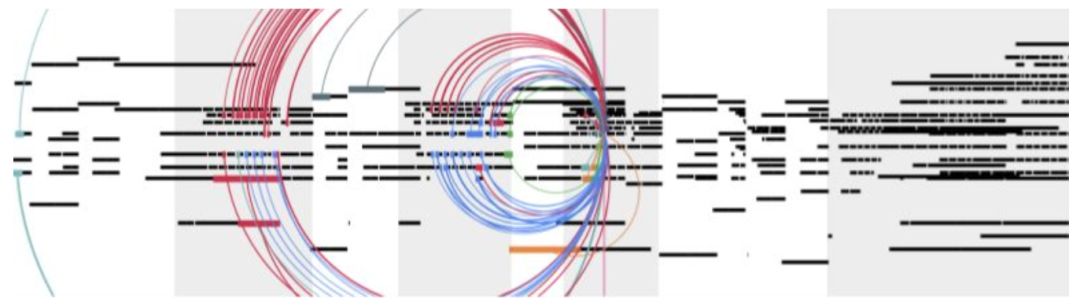
音乐变换器的片断
灰色部分是主题出现的地方。不同颜色代表不同的注意力头,这些注意力头注意到了灰色部分。
下面是示例动画,边播放边显示预测时正在关注的音符。这种自注意力是音符级或事件级的。所以观察时,会看到多个注意力头在移动。
那么音乐变换器是怎么做到的?
普通的注意力机制相当于过去历史的加权平均。如下图所示:
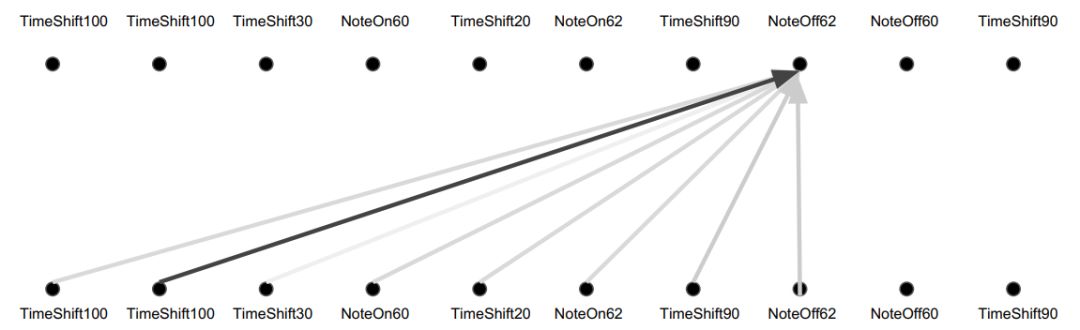
注意力:加权平均
注意力的优点是,无论距离多远,都能直接访问。如果前面出现某个主题,那么后面可以根据相似度检索到这些主题。但是这就像词袋模型一样,无法捕捉前后结构。
因此人们提出位置正弦曲线,如下图所示:
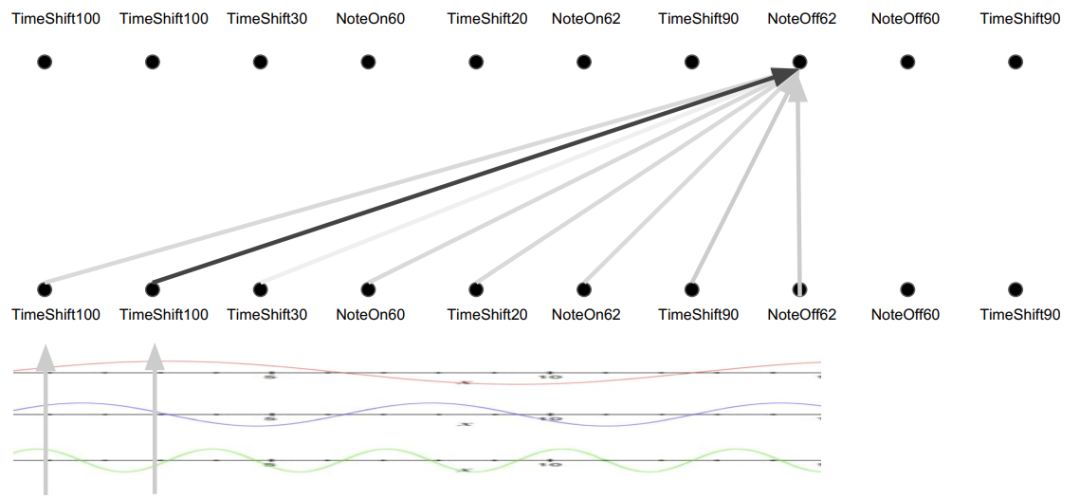
注意力:加权平均
这基本上是把索引放入不同移动速度的正弦曲线。距离近的位置具有相似的横截面积。
相比之下,卷积则通过固定滤波器的滑动来捕捉相对距离。如下图所示:
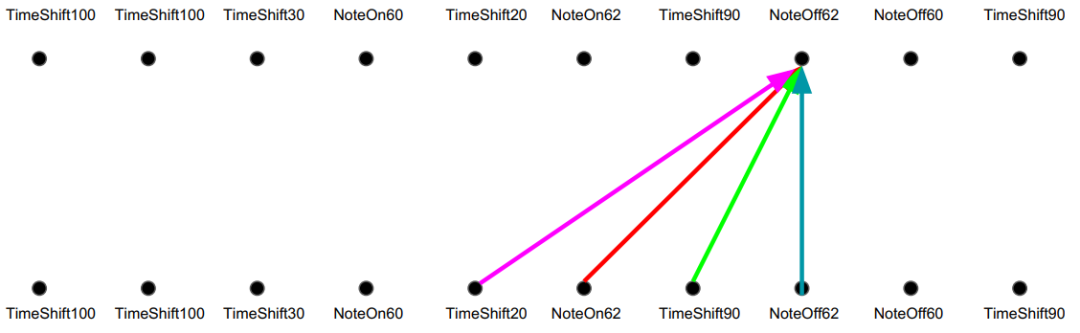
卷积:相对位置的不同线性变换
从某种程度而言,卷积就像一种刚性结构,可以明确地引入距离信息。
下面的多头相对注意力则是以上的融合:
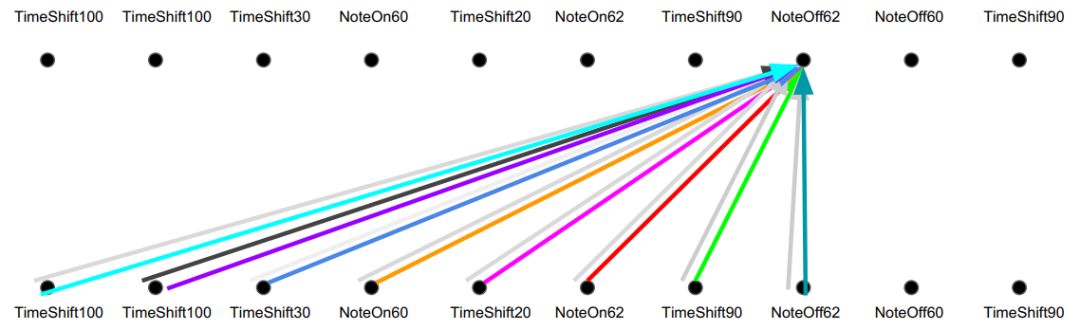
相对注意力:多头注意力+卷积
一方面,可以直接访问历史。另一方面,又能把握这个历史的相对关系,抓住平移不变性。音乐变换器之所以能根据起始样本,生成连贯的音乐,是因为在某种程度上依赖了这种平移不变性,将相对信息向前传递。
通常,变换器对比的是查询和键,得到的是自相似方阵。如下图所示:
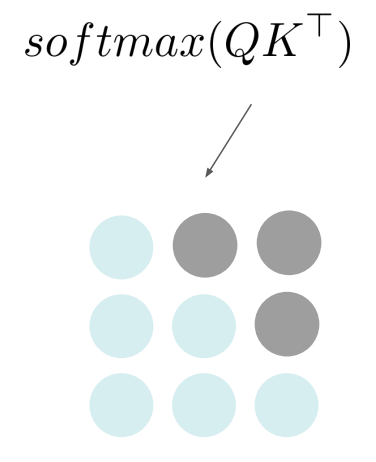
注意力
相对注意力则增加了一项,便于每次做对比时,考虑相距多远。
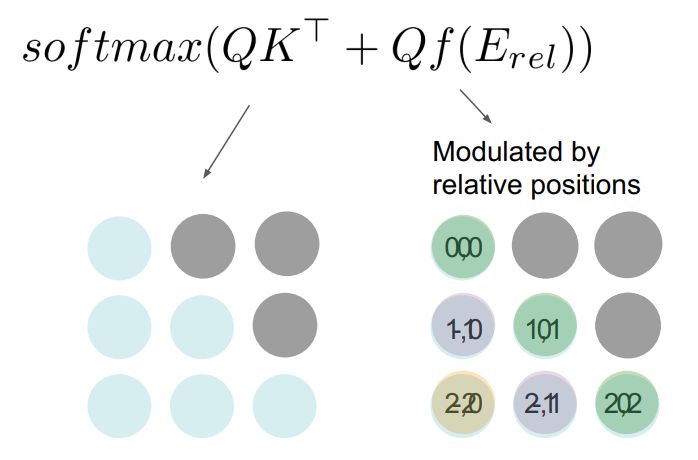
相对注意力
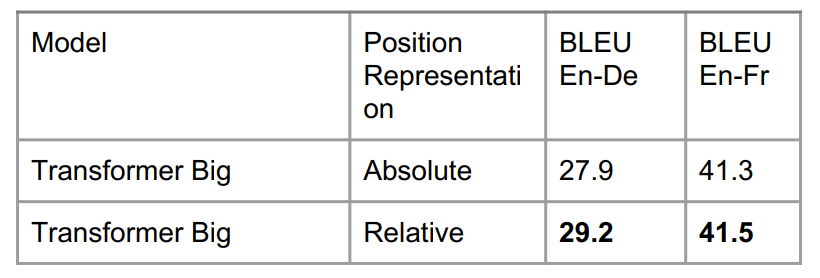
从英德翻译来看,变换器有相对位置表征比无相对位置表征效果要好。
但在翻译中,序列通常较短,可能只有50到100个单词。但在刚才的音乐中,时间步达到了2000。由于要构建下图所示的三维张量,这非常耗内存。
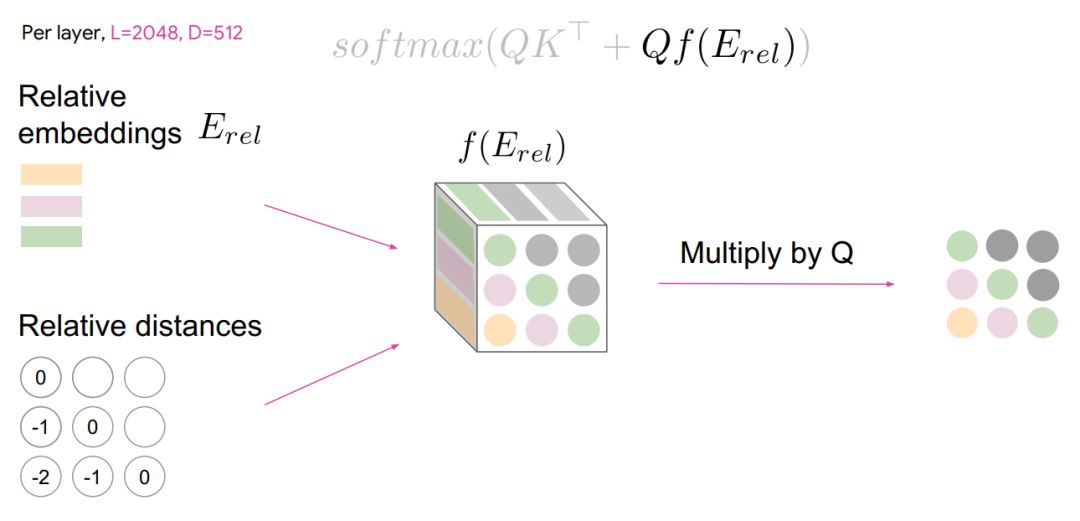
首先要计算相对距离,然后查找与之对应的嵌入。这就有LxL的矩阵。另外还要在每个位置收集嵌入,即深度。这就是三维张量。
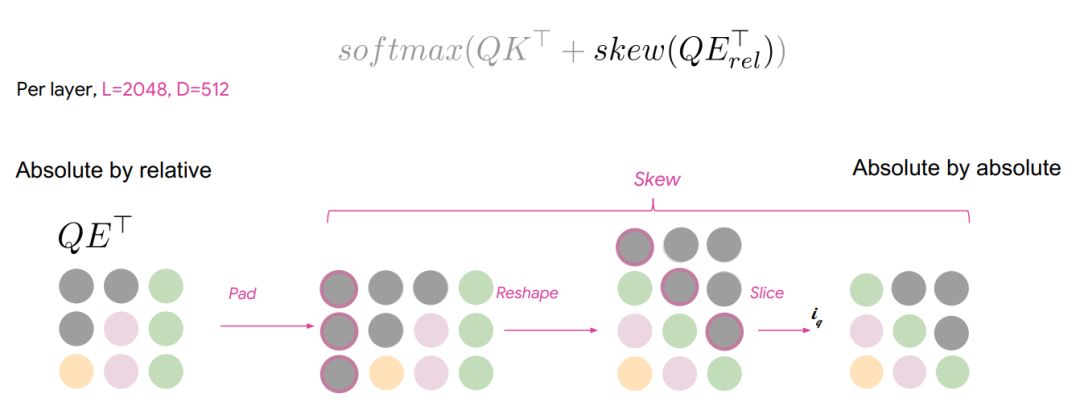
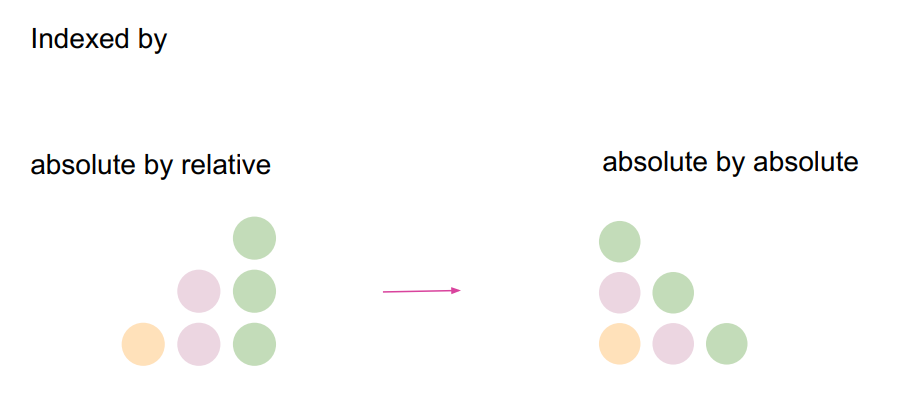
实际上,查询和嵌入距离可以直接相乘,这时得到按相对距离排序的查询,但是需要按键排序的查询。我们只需做一系列的歪斜,使之变成右边的配置。如下图所示:
下图是两者内存需求的差异:
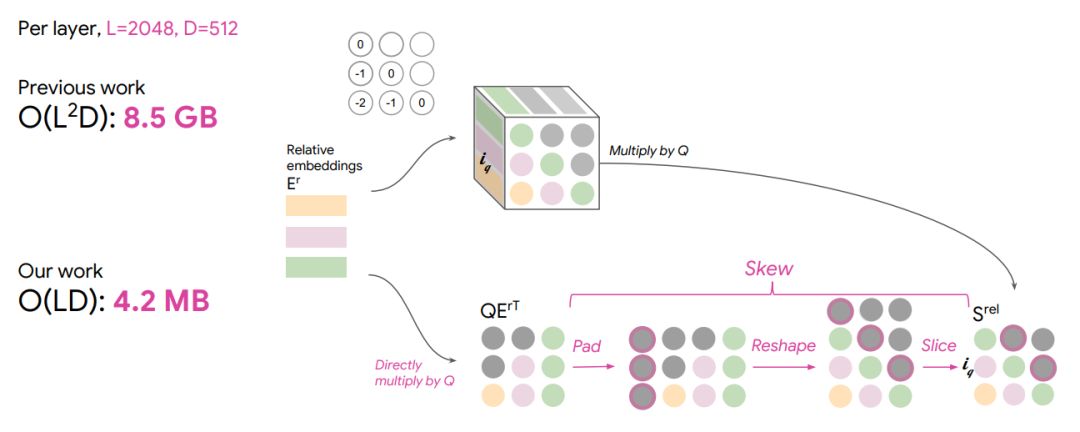
其实很多情况下,真正的挑战是提高内存效率,以便建模更长的序列。
下面欣赏一段音乐变换器生成爵士乐:
总而言之,相对注意力是做音乐生成的强大机制,当然它也有助于机器翻译。
平移不变性
相对注意力在图像中的作用类似于卷积,那就是实现了平移不变性。
例如,计算红点的特征不依赖于狗在图像中的位置,也就是不依赖于绝对位置。
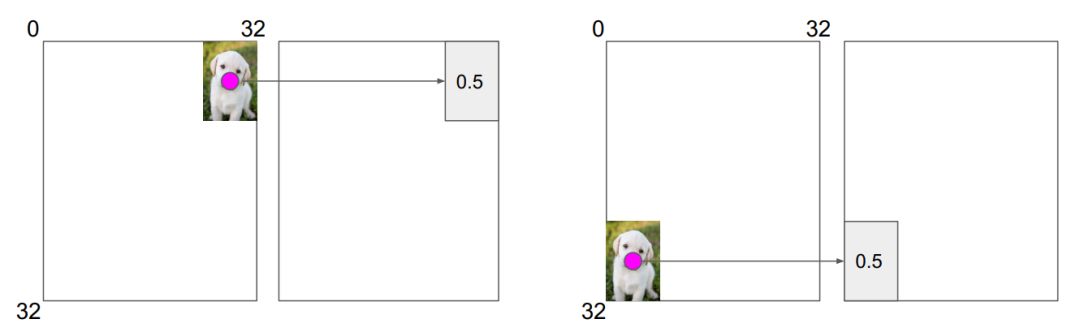
卷积在平移不变性这方面做得非常好。
现在,相对注意力达到了完全相同、甚至更好的效果。
实现平移不变性对于图像处理而言是非常重要的。
所以在图像半监督学习中运用自注意力会是一个很好的方向。
相对注意和图
相对注意力的另外一个用武之地是图结构。
设想下面的相似图。红边代表公司的概念;蓝边代表水果的概念。
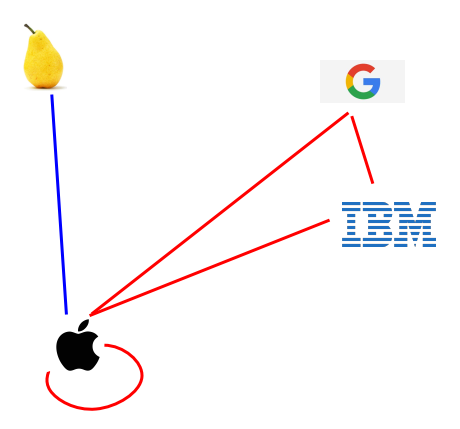
关系归纳偏见
苹果占了两种形式。
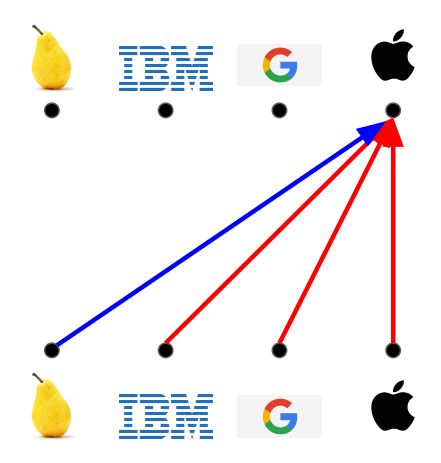
相对注意力
可以想象,相对注意力可以用来建模不同元素概念的相似度。
所以图问题可以使用相对注意力。
消息传递神经网络
在图方面,之前也有相关工作,被称为消息传递神经网络。
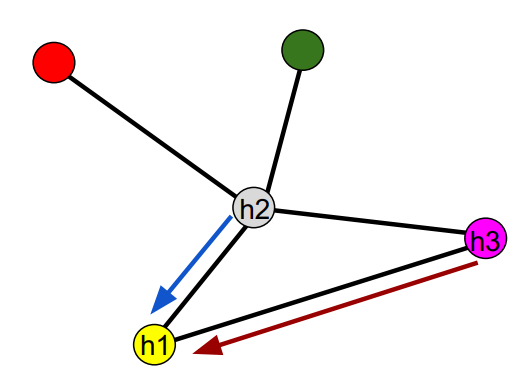
量子化学中的神经消息传递
如果看一看消息传递函数,其实只是在两个节点之间传递消息。
实际上,可以把自注意力看成全连接双偶图,并在节点之间传递消息。
自注意力和消息传递网络的唯一不同之处在于:
消息传递网络是在两个节点之间传递消息,自注意力是在所有节点之间都有互动。
另外,消息传递论文还提出了多塔的概率,这和多头注意力如出一辙。
多塔结构
总结和展望
自注意力
总结一下,自注意力机制具有以下优点:
任何两个位置之间的路径长度是固定的
具有无限记忆,无需将信息压缩到有限固定空间
易于并行化
可以模拟自相似性
相对注意力有平移不变性,能够建模时间、音乐和图
-
rnn是递归神经网络还是循环神经网络2024-07-05 1946
-
循环神经网络和卷积神经网络的区别2024-07-04 3354
-
卷积神经网络与循环神经网络的区别2024-07-03 8530
-
cnn卷积神经网络模型 卷积神经网络预测模型 生成卷积神经网络模型2023-08-21 2465
-
神经网络算法是用来干什么的 神经网络的基本原理2022-12-12 7527
-
卷积神经网络模型发展及应用2022-08-02 13388
-
卷积神经网络一维卷积的处理过程2021-12-23 2092
-
基于异质注意力的循环神经网络模型2021-03-19 1137
-
基于深度神经网络的文本分类分析2021-03-10 2337
-
卷积神经网络的优点是什么2020-05-05 3643
-
什么是图卷积神经网络?2019-08-20 2415
-
卷积神经网络如何使用2019-07-17 2892
-
全连接神经网络和卷积神经网络有什么区别2019-06-06 6025
-
循环神经网络注意力的模拟实现2018-10-22 2364
全部0条评论

快来发表一下你的评论吧 !
