

语音识别的原理是什么
好的,语音识别的核心目标是将人类说出的声音转换成对应的文字。这个过程相当复杂,融合了信号处理、声学模型、语言模型、模式识别和人工智能等多种技术。其基本原理可以概括为以下几个关键步骤:
-
声波采集与数字化(输入):
- 麦克风捕获说话人发出的声音(声波)。
- 声波是连续变化的模拟信号(波形)。
- 模数转换器将连续的模拟声波信号转换成计算机可以处理的数字信号(一系列离散的数字,代表不同时间点的声波振幅和频率)。
-
预处理(信号清洗):
- 数字化后的信号通常包含很多“杂质”:
- 环境噪音: 如空调声、键盘声、背景人声等。
- 录音设备引入的噪声: 如电流嘶嘶声(本底噪声)。
- 不需要的频段: 人类语音主要集中在 50Hz 到 8kHz 之间,尤其是低频和高频部分包含的信息较少或干扰较多。
- 预处理的目标是尽可能“纯净”地保留代表语音特征的主要信号:
- 降噪: 使用各种算法(如谱减法)减少背景噪声。
- 预加重: 提升高频分量,补偿发声时声带和嘴唇对高频的衰减,使频谱更平坦,便于后续分析。
- 端点检测: 找出语音开始和结束的位置(静音剔除),避免处理大段无用的静音部分。
- 分帧: 语音是短时平稳的(短时间内特性变化不大)。将数字信号切成许多短小的片段(一帧,通常 20-40 毫秒)。
- 加窗: 对每一帧应用一个窗函数(如汉明窗、汉宁窗),平滑帧两端的信号,减少因分帧造成的截断效应(频谱泄漏)。
- 数字化后的信号通常包含很多“杂质”:
-
特征提取(关键信息提炼):
- 这是最关键的一步。直接从原始声波或简单的频谱图中识别词语效率太低且不可靠。
- 目标是从每一帧语音信号中提取出能够有效区分不同发音单元(如音素、音节) 的声学特征向量。
- 最常用也最重要的特征是 MFCC:
- 模拟人耳感知声音频率的方式(人耳对低频更敏感)。
- 步骤:对每帧信号做傅里叶变换得到频谱 -> 通过一组梅尔尺度的三角滤波器组计算能量 -> 对每组的能量取对数 -> 做离散余弦变换 -> 取前 N 个系数作为 MFCC 特征。
- 其他常用特征包括:滤波器组能量、线性预测倒谱系数、一阶/二阶差分特征(描述特征随时间的变化)等。
- 最终输出是一个特征序列,每一帧对应一个特征向量(比如 13 维 MFCC + 一阶差分 + 二阶差分 = 39 维)。
-
模型匹配与识别(核心解码):
- 这一步利用训练好的模型,将上一步得到的声学特征序列映射到可能的文字序列上。
- 传统语音识别系统使用 隐马尔可夫模型与高斯混合模型组合:
- 声学模型: 核心任务是建模发音单元(通常是最小的发音单位:音素)。HMM 用来描述音素发音的时序变化特性(如起始、中间、结束状态)。GMM(或其他模型,如后来的DNN)则用来描述在某个特定状态上,观测到的声学特征向量的概率分布(即这个状态下某个特征向量出现的概率)。一个词的发音可以由若干音素的HMM连接而成。
- 词典: 包含了系统需要识别的单词及其对应的发音序列(由音素组成)。比如,“苹果” -> /p i n g g u o/(基于某种音标系统)。
- 语言模型: 描述单词或词语序列出现的概率规律(即一句话“说人话”的可能性有多大)。最常用的是 N-gram 模型(如三元文法,考虑前后词的影响)。语言模型帮助系统在多个发音相近的可能结果中,选出最符合语言习惯、语义通顺的句子。例如,“识别语音”比“识别生鲜”更常见。
- 解码器(搜索过程):
- 它的任务就是高效地搜索一个巨大的网络(由声学模型、词典、语言模型构建的搜索空间),找到一条最优路径。
- 这条路径的声学特征序列概率(声学模型)和单词序列概率(语言模型)结合起来的整体得分最高。
- 这就是最终识别的结果文字序列。著名的解码算法包括维特比算法和基于加权有限状态机的方法。
-
输出:
- 将解码器搜索得到的最优词序列输出作为最终的识别结果文本。
现代发展趋势:端到端模型
近年来,随着深度学习(尤其是深度神经网络) 的迅猛发展,语音识别技术发生了巨大变革:
- DNN-HMM 混合系统: 用 DNN 取代 GMM 来更准确地预测 HMM 状态的概率。
- 端到端模型: 这是一个重要的范式转变。
- 目标:直接训练一个单一的、复杂的深度神经网络模型(如基于注意力机制的序列到序列模型、Transformer、RNN-T),输入是声学特征序列,输出直接就是目标文字序列(字符、字或词)。
- 简化流程: 省去了传统流程中明确分离的声学模型、词典、HMM 状态和复杂的解码器。模型自己从海量数据中学习声学到文字的映射规则以及语言的统计规律。
- 优势: 简化系统设计,性能往往更好,尤其在处理口音、噪声、口语化表达等方面展现出强大的鲁棒性。
- 代表模型: Connectionist Temporal Classification、RNN-Transducer、LAS、Transformer ASR 等。
总结流程图
说话声音 (声波) --> 麦克风采集 --> 模数转换 (ADC) --> 数字音频信号
|
v
预处理
(降噪、端点检测、分帧、加窗) --> 处理后的信号帧
|
v
特征提取 (如 MFCC) --> 声学特征向量序列 (如每帧一个39维向量)
|
v
解码器 + 模型 +--> 声学模型 (建模声音单元: e.g., 音素状态)
+--> 发音词典 (映射音素到单词)
+--> 语言模型 (建模词语序列概率)
|
v
搜索最优路径 (输出最可能文字序列) --> 识别文本一句话概括核心原理: 通过对声音信号进行数字化、降噪、特征提取,并利用训练好的声学模型(理解声音单元)和语言模型(理解词语组合规律),通过解码器在巨大的搜索空间中找出声学和语言概率最优匹配的文字序列。
这项技术广泛应用于语音输入法、智能助手、语音搜索、自动字幕、智能家居控制、语音生物识别等领域。端到端模型的发展使其性能和应用范围持续提升。
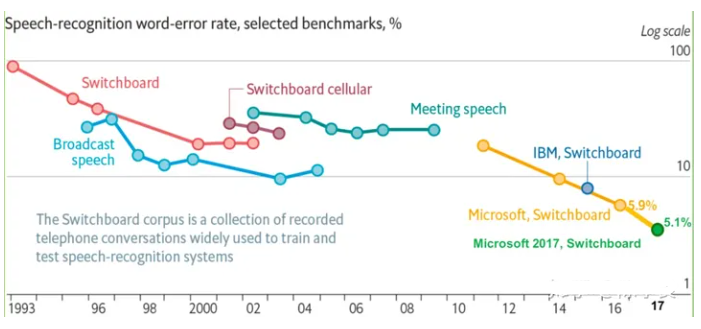
情感语音识别的挑战与未来趋势
。 二、情感语音识别的挑战 情感表达的复杂性:人类的情感表达非常复杂,不仅涉及到语音的音调、音色和音量等,还与语言表达、肢体动作、面部表情等多个
2023-11-30 11:24:00
语音识别发展 Python进行语音识别案例
摘要:随着信息化时代的快速到来以及计算机技术的不断完善发展,语音识别在众多领域都得到了应用,同时语音
资料下载
![]() 香香技术员
2023-07-19 14:32:18
香香技术员
2023-07-19 14:32:18
信号识别的意义和发展趋势及特定信号识别的方法说明
文章首先介绍了信号识别的意义和发展趋势,阐述了传统通信的信号识别方法;接着介绍了两种信号识别方法的实际应用案例,对信号
资料下载
佚名
2020-06-30 17:01:12
语音识别的技术历程
深度学习技术自 2009 年兴起之后,已经取得了长足进步。语音识别的精度和速度取决于实际应用环境,但在安静环境、标准口音、常见词汇场景下的语音
2019-08-22 14:21:40
- 如何分清usb-c和type-c的区别
- 中国芯片现状怎样?芯片发展分析
- vga接口接线图及vga接口定义
- 芯片的工作原理是什么?
- 华为harmonyos是什么意思,看懂鸿蒙OS系统!
- 什么是蓝牙?它的主要作用是什么?
- ssd是什么意思
- 汽车电子包含哪些领域?
- TWS蓝牙耳机是什么意思?你真的了解吗
- 什么是单片机?有什么用?
- 升压电路图汇总解析
- plc的工作原理是什么?
- 再次免费公开一肖一吗
- 充电桩一般是如何收费的?有哪些收费标准?
- ADC是什么?高精度ADC是什么意思?
- dtmb信号覆盖城市查询
- EDA是什么?有什么作用?
- 苹果手机哪几个支持无线充电的?
- type-c四根线接法图解
- 华为芯片为什么受制于美国?
- 怎样挑选路由器?
- 元宇宙概念股龙头一览
- 锂电池和铅酸电池哪个好?
- 如何进行编码器的正确接线?接线方法介绍
- 什么是场效应管?它的作用是什么?
- 虚短与虚断的概念介绍及区别
- 晶振的作用是什么?
- 大疆无人机的价格贵吗?大约在什么价位?
- 苹果nfc功能怎么复制门禁卡
- amoled屏幕和oled区别
- 单片机和嵌入式的区别是什么
- 复位电路的原理及作用
- BLDC电机技术分析
- dsp是什么意思?有什么作用?
- 苹果无线充电器怎么使用?
- iphone13promax电池容量是多少毫安
- 芯片的组成材料有什么
- 特斯拉充电桩充电是如何收费的?收费标准是什么?
- 直流电机驱动电路及原理图
- 传感器常见类型有哪些?
- 自举电路图
- 通讯隔离作用
- 苹果笔记本macbookpro18款与19款区别
- 新斯的指纹芯片供哪些客户
- 伺服电机是如何进行工作的?它的原理是什么?
- 无人机价钱多少?为什么说无人机烧钱?
- 以太网VPN技术概述
- 手机nfc功能打开好还是关闭好
- 十大公认音质好的无线蓝牙耳机
- 元宇宙概念龙头股一览
湘ICP备2023036445号-105