

语音识别技术的基本原理是什么?
更多
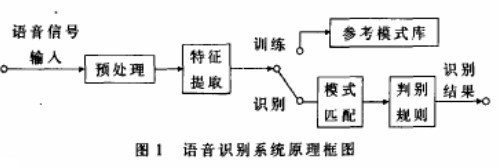
语音识别技术的核心目标是将人类的语音信号转换成对应的文字内容。其基本原理可以概括为以下几个主要步骤:
-
信号预处理与特征提取
- 输入: 原始的声音波形(一维时间序列)。
- 预处理:
- 采样与量化: 将连续的模拟声音信号转换成数字信号(离散的时间点和幅度)。
- 预加重: 提升高频部分能量,补偿语音信号中高频部分通常较弱的情况。
- 分帧: 将长段语音切分成非常短(如20-40毫秒)的小段,称为“帧”。这假设语音信号在短时间内是相对稳定的(“短时平稳”)。
- 加窗: 对每一帧信号应用窗函数(如汉明窗),以减少帧边缘信号不连续造成的频谱泄露。
- 特征提取:
- 提取最能代表语音内容的关键特征,同时尽量去除说话人个性、环境噪声、信道差异等无关信息。
- 最常用特征:梅尔频率倒谱系数(MFCC): 这是目前最主流的特征。
- 计算帧的功率谱(通常用快速傅里叶变换 - FFT)。
- 通过一组梅尔尺度滤波器组对功率谱进行平滑和压缩(模拟人耳对频率的感知特性,对低频更敏感)。
- 对每个滤波器的输出能量取对数(人耳对声音强度的感知也是近似对数的)。
- 进行离散余弦变换(DCT),得到MFCC系数。它代表了语音频谱的包络信息(反映了发音器官的形状),对声道特征特别敏感。
- 其他特征: 线性预测系数、感知线性预测系数、滤波器组能量(FBank)等。
-
声学模型(Acoustic Model)
- 任务: 建立语音特征序列(通常由一帧帧特征向量组成)与基本发音单元(通常是音素,Phoneme)之间的映射关系。
- 核心模型(传统与现代):
- 传统主流:隐马尔可夫模型 - 高斯混合模型(HMM-GMM)
- HMM: 用于对状态序列(对应音素的各个部分)以及状态之间的时序转移概率进行建模。
- GMM: 用来描述在每个HMM状态下,观测到的语音特征向量(特征向量) 的概率分布(即在这个状态下发出某个声音特征的可能性)。
- 组合HMM和GMM:HMM建模时序变化,GMM建模每个状态的观测特征分布。
- 现代主流:深度学习模型 (DNN, CNN, RNN, Transformer 等)
- 模型(如深度神经网络 - DNN)直接学习从输入特征帧到音素状态(HMM状态) 或音素的概率分布。
- CTC (Connectionist Temporal Classification): 一种常用训练准则,允许模型在不对齐输入帧和输出标签的情况下进行训练,特别适合处理输入输出长度不一致的序列问题。
- RNN/Transformer 等序列模型: 显式地建模语音信号的长时依赖关系。
- 混合模型: 如 DNN-HMM:用 DNN 替换 GMM 来计算 HMM 状态的后验概率,性能通常优于 HMM-GMM。
- 传统主流:隐马尔可夫模型 - 高斯混合模型(HMM-GMM)
- 输出: 给定输入特征序列,声学模型给出对应每个时间点上各个音素(或其状态)的概率分数。
-
语言模型(Language Model)
- 任务: 建模人类语言的内在规律,即词语序列出现的可能性(概率)。
- 目的: 帮助识别系统在多个可能的候选文字序列中选择更符合语法和语义习惯的那个。
- 常用模型:
- N-gram 模型: 基于统计,计算词语序列
w1, w2, ..., wm的概率,通常简化为基于前面 N-1 个词来预测第N个词的概率(即P(wi | w_{i-N+1} ... w_{i-1}))。简单高效。 - 神经网络语言模型 (NNLM): 使用 RNN、LSTM 或 Transformer 等深度学习模型来学习词语序列的长期依赖关系和更复杂的语言结构,表达能力强于 N-gram。
- N-gram 模型: 基于统计,计算词语序列
- 输出: 给定一串候选的词序列,语言模型给出该词序列的概率
P(W)。
-
发音词典(Lexicon / Pronunciation Dictionary)
- 作用: 作为桥梁,连接声学模型处理的音素和语言模型处理的词语。
- 内容: 一个词表,列出了系统中所有可能的词语及其对应的音素序列。
- 示例: "Hello" -> /h ə l oʊ/
-
解码与搜索(Decoder)
- 任务: 将前面所有组件整合起来,在庞大的、潜在可能的词语序列空间中进行搜索,找到最优的文本序列。
- 输入: 声学模型输出的特征-音素概率、语言模型输出的词语序列概率、发音词典定义的词语-音素映射。
- 搜索算法: 核心是在由状态(音素/HMM状态)、词、词序列构成的状态空间中进行图搜索或束搜索(Beam Search),找到一条概率最大化的路径。
- 构建一个巨大的搜索图(搜索空间),节点代表状态或词汇信息。
- 声学模型分数: 衡量语音特征与候选音素序列的匹配度。
- 语言模型分数: 衡量候选词序列本身的合理性。
- 解码器目标: 找到一个词序列
W,使得 P(W | X)(给定语音信号X,词序列W的后验概率)最大化。根据贝叶斯定理,这等价于最大化P(X | W) * P(W),其中P(X | W)主要来自声学模型(通过发音词典将词转换成音素序列),P(W)来自语言模型。
- 输出: 最终识别出的文字序列。
简化流程图:
原始语音波形 -> 信号预处理 -> 特征提取(如 MFCC) -> [声学模型] -> (音素序列概率)
| |
发音词典 语言模型
| |
------> 解码搜索 <------
|
v
识别文本关键点总结:
- 从物理信号到抽象符号: 核心是将声音的物理波形一步步转化为有意义的文字符号。
- 统计学基础: 整个过程高度依赖概率统计(最大似然估计、贝叶斯准则)。
- 深度学习的统治地位: 现代语音识别系统的声学模型几乎全部由深度学习模型(特别是端到端模型如CTC、RNN-T、LAS)驱动,语言模型也广泛使用神经网络模型。HMM-GMM已退居二线。
- 联合优化: 端到端模型(如LAS, Listen, Attend and Spell)尝试绕过明确的声学模型-语言模型-发音词典的分割,直接学习从声学特征到文字序列的映射。
局限性(简要提及):
- 易受口音、背景噪声、语速、混响等因素影响。
- 识别领域外(没见过的)词语或专有名词困难。
- 远场语音识别依然挑战巨大。
- 语音识别 != 语义理解。系统能识别出文字,不代表它真正“听懂”了意思。
这是一个高度简化的描述,实际的语音识别系统涉及大量工程细节、优化策略和复杂的模型结构(如注意力机制、Transformer等)。

7天热门专题
 换一换
换一换
- 如何分清usb-c和type-c的区别
- 中国芯片现状怎样?芯片发展分析
- vga接口接线图及vga接口定义
- 芯片的工作原理是什么?
- 华为harmonyos是什么意思,看懂鸿蒙OS系统!
- 什么是蓝牙?它的主要作用是什么?
- ssd是什么意思
- 汽车电子包含哪些领域?
- TWS蓝牙耳机是什么意思?你真的了解吗
- 什么是单片机?有什么用?
- 升压电路图汇总解析
- plc的工作原理是什么?
- 再次免费公开一肖一吗
- 充电桩一般是如何收费的?有哪些收费标准?
- ADC是什么?高精度ADC是什么意思?
- EDA是什么?有什么作用?
- dtmb信号覆盖城市查询
- 苹果手机哪几个支持无线充电的?
- type-c四根线接法图解
- 华为芯片为什么受制于美国?
- 怎样挑选路由器?
- 元宇宙概念股龙头一览
- 锂电池和铅酸电池哪个好?
- 什么是场效应管?它的作用是什么?
- 如何进行编码器的正确接线?接线方法介绍
- 虚短与虚断的概念介绍及区别
- 晶振的作用是什么?
- 大疆无人机的价格贵吗?大约在什么价位?
- 苹果nfc功能怎么复制门禁卡
- 单片机和嵌入式的区别是什么
- amoled屏幕和oled区别
- 复位电路的原理及作用
- BLDC电机技术分析
- dsp是什么意思?有什么作用?
- 苹果无线充电器怎么使用?
- iphone13promax电池容量是多少毫安
- 芯片的组成材料有什么
- 特斯拉充电桩充电是如何收费的?收费标准是什么?
- 直流电机驱动电路及原理图
- 传感器常见类型有哪些?
- 自举电路图
- 通讯隔离作用
- 苹果笔记本macbookpro18款与19款区别
- 新斯的指纹芯片供哪些客户
- 伺服电机是如何进行工作的?它的原理是什么?
- 无人机价钱多少?为什么说无人机烧钱?
- 以太网VPN技术概述
- 手机nfc功能打开好还是关闭好
- 十大公认音质好的无线蓝牙耳机
- 元宇宙概念龙头股一览
湘ICP备2023036445号-105