

语音识别技术工作原理影视
好的,我们来拆解一下现代语音识别技术(尤其是基于深度学习的)的工作原理,重点放在影视制作中应用的相关点上。
简单来说,语音识别就是把人类说出来的声音(语音)转换成对应的文字文本。这个过程听起来简单,但在计算机里完成却相当复杂,尤其是在影视这种可能包含背景音乐、噪声、不同口音、现场声的环境下。
以下是其主要工作步骤和原理:
-
声音信号的捕获与数字化(麦克风):
- 起点是麦克风,它将物理的声音振动转换成连续的模拟电信号。
- 电脑的声卡将模拟信号转换成数字信号(一串离散的数字序列),这个过程叫采样和量化。影视录音通常会使用专业的录音设备和高质量采样(如48kHz或更高),以保证原始声音信息的完整性。
-
预处理:
- 降噪(去噪): 影视音频常常包含环境噪音(风声、机器声)、音乐、其他人声干扰等。技术会尝试过滤掉这些非语音部分。常用方法有:频谱减法、Wiener滤波等。
- 端点检测/语音活动检测: 检测录音中哪部分是真正的语音(人开始说话和结束说话的位置),剔除静音或长噪音段。这对处理影视素材中的间歇性说话很重要。
- 预加重: 提高高频分量,补偿发音时嘴唇等部位对高频的衰减,使频谱更平坦,便于后续处理(通常用一个高通滤波器)。
- 分帧(Framing): 语音是动态变化的,但短时间(如10-50ms)内可以看作是平稳的。因此将整个语音信号切分成一小段一小段的帧来处理,通常每帧重叠一部分(如50%)。
- 加窗: 为减小每帧两端的不连续性(信号突然被截断),用一个窗函数(如汉明窗)乘以帧信号。
-
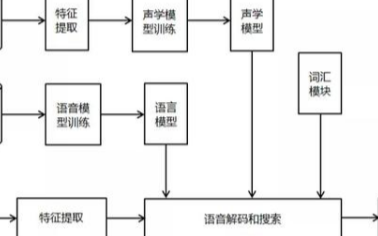
特征提取:
- 这步非常关键!目的是找到最能代表语音特性的信息,同时压缩数据量,去除冗余(比如声音的大小、说话人差异)信息。
- 主流特征:MFCC:
- 将每帧语音进行快速傅里叶变换,得到该帧的频谱。
- 通过一组三角带通滤波器(Mel滤波器组) 对频谱能量进行平滑和降维(模拟人耳对不同频率感知的敏感度差异)。
- 对每个滤波器的输出能量取对数(人耳对声音强度的感知是对数关系的)。
- 做离散余弦变换,得到最终的特征向量(Mel-Frequency Cepstral Coefficients)。这个向量能有效表征语音的声道特性(发什么音),相对弱化声源特性(谁在说话、大声小声)。
- 其他特征: PLP, 滤波器组系数等。
- 高级特征: 现代深度学习模型有时会直接使用原始频谱图(Spectrogram)作为输入,或进行更复杂的自动特征学习。
-
声学模型(核心):
- 核心任务: 学习语音特征与基本发音单位之间的映射关系。
- 关键概念:音素: 语音的基本单位(例如英文有约44个音素,“cat”由/k/, /æ/, /t/组成)。不同语言音素不同。
- 建模方法(深度学习主流):
- 输入: 预处理和特征提取后的特征序列(如MFCC向量序列)。
- 输出: 该序列对应于每个时间帧上,各个音素(或更小的状态,如音素的开始、中间、结束)的概率分布。
- 模型: 深度神经网络是绝对主流。
- 循环神经网络: 如LSTM, GRU。擅长处理序列数据(语音是时间序列),有记忆能力,能利用上下文信息。曾是主导。
- 卷积神经网络: 如1D-CNN。可以捕捉局部特征模式,对说话人变异有一定鲁棒性。
- Transformer: 基于自注意力机制,能更好地捕获长距离依赖关系。结合CNN构成Conformer模型,是目前最前沿、性能最好的声学模型架构之一。
- 输出层: 通常是Softmax,输出每个音素(或状态)的概率。
- 训练: 模型需要大量的“语音 - 对应标注文本”对来学习。标注文本必须准确到音素或词级别(对齐)。影视领域的训练数据最好能包含多种场景、口音、噪音类型。训练后模型就能预测出给定语音特征最可能对应的音素序列。
-
语言模型:
- 核心任务: 判断一个词序列作为一个自然语言句子的可能性(概率)。
- 作用: 声学模型只能识别音素或小片段,容易出错(同音字/词,口音误差),语言模型引入“知识”来纠正。比如声学模型可能识别出“我要去北京”和“我要去背景”,语言模型知道“去北京”是常见说法,“去背景”在语法和语义上不常见(除非在特定影视语境下),所以正确结果应为“去北京”。
- 建模方法:
- 统计语言模型: 基于N元文法,如计算“北京”出现在“我要去”之后的概率。需要大量文本语料库。
- 神经网络语言模型: 基于RNN/LSTM/Transformer等,能够捕捉更长距离的上下文依赖关系和更复杂的语义信息,效果更好。像BERT、GPT这类强大的预训练语言模型也能融入进来。
-
解码器(识别引擎):
- 核心任务: 把声学模型和语言模型(有时还有发音词典)的信息结合起来,在巨大的可能词序列空间中,搜索出最匹配输入语音信号的那个最优词序列(最终识别结果)。
- 原理:
- 词典: 包含所有可能的词及其音素发音序列。
- 搜索空间: 将词根据发音拆分成音素序列,然后映射到状态序列(HMM状态或神经网络输出状态)。所有词按照状态序列连接起来,形成一个巨大的状态转移网络。
- 动态规划/启发式搜索:
- 隐马尔可夫模型: 结合HMM(建模状态转移和观测概率)和Viterbi算法或前向后向算法进行搜索(传统方法)。
- 端到端模型: Connectionist Temporal Classification 或基于注意力机制的序列到序列模型,可以直接输出词或字母序列。它模糊了传统的声学模型、语言模型、解码器的界限,用一个模型完成。如DeepSpeech2, Wav2Vec 2.0等。
- 束搜索: 一种启发式搜索算法,只保留每一步最优的N条候选路径,大大减少计算量。
- 关键: 解码器需要平衡声学模型的置信度(这段声音像某个音)和语言模型的置信度(这个词串起来说得通),找出整体最优解。
-
后处理:
- 输出格式化: 添加标点符号(影视对白中非常重要)、大小写转换。
- 口语化处理: 将“呃”、“啊”、重复词等处理得更符合书面语(或根据需要保留)。
- 特定领域优化: 如影视中的人名、地名、特定术语、口音识别后校正。
- 结合场景信息(可选): 在有视频或剧本信息的情况下,可以进一步约束识别结果。
为什么在影视领域有挑战?
- 高噪声/背景音乐: 现场嘈杂的环境或复杂的背景音乐会严重影响声学模型的识别。
- 多说话人重叠: 多人同时说话让端点检测和分离变得困难。
- 远场拾音: 距离麦克风远的声音信号较弱,混响严重。
- 口音和方言: 演员的不同口音需要模型有足够的泛化能力。
- 非标准发音: 哭泣、低语、呐喊、歌曲等丰富的情感表达和说话风格。
- 专业术语/自造词: 影视剧本中常有的地名、人名、特殊设定词汇等。
说人话的总结
想象一下语音识别软件做三件事:
- 听清声音特征(声学模型): 像仔细分辨你朋友说话声里“a”、“b”、“c”这些基本音到底发得有多像。它不在乎你是谁,也不在乎整句话说啥,只关心这一小段声音是哪个音。
- 理解语言规则(语言模型): 像你朋友说“明天天气怎...”,虽然最后一个字含糊不清,但你根据前面的词和常识(语言模型)会猜到他想问“怎么样”。语言模型就是提供了这种“猜测”能力。
- 猜最佳答案(解码器): 结合“听到的音”和“可能的句子”这两方面信息,在所有组合里(比如“天气怎”后面可能是“么样”,“么好”,“么了”等等),计算机算出哪个组合最合理(结合语音像的程度和句子常见的程度),就是最终识别结果。
影视中需要克服的最大困难主要是背景噪音干扰(让它听不清基础音)和丰富的人声变化(让它难以判断各种发音),以及识别出精确的时间戳用于字幕同步。现代深度学习在解决这些问题上取得了巨大进步。

NRK220X语音识别模块语音芯片语音ic数据资料
NRK2202语音识别模块为广州九芯电子自主研发的一款模块,无须外围元件,直接对接外部,集成了一颗高性能、低成本的离线语音
资料下载
![]() 九芯电子语音IC
2021-10-22 10:59:30
九芯电子语音IC
2021-10-22 10:59:30
RFID读写器天线的工作原理和设计的基本步骤说明
本文简要介绍了RFID技术的基本工作原理,指出天线设计是RFID系统设计的关键部分。然后介绍了RFID读写器天线的基本工作原理,指明其相应的物理
资料下载
佚名
2020-10-20 14:41:26
近耦合射频识别系统的工作原理是怎么样的及如何进行天线设计
介绍一种近耦合射频识别系统(典型读写距离25 mm 的非接触读写卡系统) 的两个重要组成部分——邻近耦合设备和邻近卡的工作原理及由此设计的天线尺寸和匹配电路。
资料下载
佚名
2020-05-13 17:30:48

技术工作和工程工作的区别
。尽管技术工作和工程工作存在较大的区别,但这两项工作所需要的科学基础知识和技能却非常相似,由这此基础知识和技能组成的课程体系,逐步形成了现代大学
- 如何分清usb-c和type-c的区别
- 中国芯片现状怎样?芯片发展分析
- vga接口接线图及vga接口定义
- 芯片的工作原理是什么?
- 华为harmonyos是什么意思,看懂鸿蒙OS系统!
- 什么是蓝牙?它的主要作用是什么?
- ssd是什么意思
- 汽车电子包含哪些领域?
- TWS蓝牙耳机是什么意思?你真的了解吗
- 什么是单片机?有什么用?
- 升压电路图汇总解析
- plc的工作原理是什么?
- 再次免费公开一肖一吗
- 充电桩一般是如何收费的?有哪些收费标准?
- ADC是什么?高精度ADC是什么意思?
- EDA是什么?有什么作用?
- dtmb信号覆盖城市查询
- 中科院研发成功2nm光刻机
- 苹果手机哪几个支持无线充电的?
- type-c四根线接法图解
- 华为芯片为什么受制于美国?
- 怎样挑选路由器?
- 元宇宙概念股龙头一览
- 锂电池和铅酸电池哪个好?
- 什么是场效应管?它的作用是什么?
- 如何进行编码器的正确接线?接线方法介绍
- 虚短与虚断的概念介绍及区别
- 晶振的作用是什么?
- 大疆无人机的价格贵吗?大约在什么价位?
- 苹果nfc功能怎么复制门禁卡
- 单片机和嵌入式的区别是什么
- amoled屏幕和oled区别
- 复位电路的原理及作用
- BLDC电机技术分析
- dsp是什么意思?有什么作用?
- 苹果无线充电器怎么使用?
- iphone13promax电池容量是多少毫安
- 芯片的组成材料有什么
- 特斯拉充电桩充电是如何收费的?收费标准是什么?
- 直流电机驱动电路及原理图
- 传感器常见类型有哪些?
- 自举电路图
- 通讯隔离作用
- 苹果笔记本macbookpro18款与19款区别
- 新斯的指纹芯片供哪些客户
- 伺服电机是如何进行工作的?它的原理是什么?
- 无人机价钱多少?为什么说无人机烧钱?
- 以太网VPN技术概述
- 手机nfc功能打开好还是关闭好
- 十大公认音质好的无线蓝牙耳机
湘ICP备2023036445号-105