

神经网络选择函数的技巧
选择神经网络中的激活函数(Activation Function)是模型设计的关键环节,直接影响学习能力和训练效率。以下是实用的技巧和考量因素:
一、 核心原则
- 引入非线性: 核心目的是让神经网络能够逼近任意复杂函数。没有非线性激活函数(或只用线性函数),无论多少层网络都等价于单个线性变换(感知机)。
- 缓解梯度消失/爆炸: 良好的激活函数应有助于在网络反向传播时保持稳定的梯度流,特别是深层网络。
- 计算效率: 激活函数及其导数的计算应相对高效,因为它们在训练和推理中会被频繁调用。
- 稀疏性(可选但有益): 某些激活函数(如ReLU)能产生稀疏激活(部分神经元输出为0),可能有助于特征选择和降低过拟合风险,提升泛化能力。
? 二、 常用激活函数选择策略
1. 隐藏层 (Hidden Layers) - 首选现代非线性函数
* **ReLU (Rectified Linear Unit):**
* **公式:** `f(x) = max(0, x)`
* **优点:**
* **计算极其高效:** 只需比较和取最大值。
* **有效缓解梯度消失:** 在正区间导数为1,梯度能稳定传递。
* **产生稀疏性:** 负输入输出为0。
* **缺点:**
* **"Dying ReLU"问题:** 如果大量输入持续为负(如学习率过高、权重初始化不当或数据分布问题),这些神经元会永久输出0且停止更新(梯度为0)。
* **输出不以0为中心:** 可能略微影响收敛速度(但实践中影响通常不大)。
* **技巧:** **这是绝大多数情况下隐藏层的默认首选起点。** 效果通常很好。
* **Leaky ReLU / Parametric ReLU (PReLU):**
* **公式:** `f(x) = max(αx, x)` (Leaky ReLU: α是小的固定值,如0.01; PReLU: α是可学习参数)
* **优点:** 解决了标准的"Dying ReLU"问题,负区间有非零梯度(αx),神经元不易"死亡"。
* **缺点:** 引入了一个额外的超参数α(Leaky需设定,PReLU需学习)。
* **技巧:** 如果使用ReLU遇到训练困难(如大量神经元不更新),优先尝试 **Leaky ReLU (α=0.01)** 或 **PReLU**。效果往往比ReLU稍好或持平。
* **Exponential Linear Unit (ELU):**
* **公式:** `f(x) = x if x >= 0; α(exp(x) - 1) if x < 0` (α通常是1或接近1的值)
* **优点:**
* 解决了"Dying ReLU"问题。
* 输出均值更接近0(有偏置效应),可能加速收敛。
* 在负区间平滑过渡。
* **缺点:** 计算量比ReLU大(涉及指数运算)。
* **技巧:** 在需要更高精度或对噪声敏感的任务中,**ELU** 是ReLU/Leaky ReLU的有力竞争者。
* **Swish:**
* **公式:** `f(x) = x * sigmoid(βx)` (β可以是常数(如1.0)或可学习参数)
* **优点:**
* 实验证明在深层网络上(尤其是图像分类)有时优于ReLU。
* 平滑、非单调(在负区间先下降后上升),在某些情况下拟合能力更强。
* 导数形式更复杂,但数值稳定性好。
* **缺点:** 计算量比ReLU大(涉及sigmoid)。
* **技巧:** 作为ReLU类函数的进阶选择,**当追求更高性能时可尝试调参使用Swish**。
* **GELU (Gaussian Error Linear Unit):**
* **公式:** `f(x) = x * Φ(x)` (Φ(x)是标准高斯分布的累积分布函数。常用近似:`x * 0.5 * (1 + tanh[√(2/π) * (x + 0.044715 * x³)])`)
* **优点:** 在大型模型(尤其是Transformer架构如BERT, GPT)中表现出色,被认为具有概率解释(神经元的输出取决于其输入高于其他输入的"概率")。
* **缺点:** 计算量更大(即使使用近似公式)。
* **技巧:** **在基于Transformer的模型中(NLP为主),GELU通常是首选或默认。**❌ 避免在隐藏层使用(或谨慎使用)
- Sigmoid / Logistic: 容易饱和导致严重的梯度消失(导数值在两头接近0),计算量也比ReLU大。通常只用于输出层。
- Tanh (Hyperbolic Tangent): 输出以0为中心(比sigmoid好),但同样存在梯度消失问题(虽然比sigmoid稍好)。在RNN中有时仍有使用,但在CNN/MLP的隐藏层中基本被ReLU族取代。
? 2. 输出层 (Output Layer) - 取决于任务类型
* **二分类任务 (Binary Classification):**
* **首选 Sigmoid:** 输出直接映射到 `(0, 1)` 区间,可解释为属于正类的概率。
* **多分类任务 (Multi-class Classification):**
* **首选 Softmax:** 将所有输出神经元的值归一化为概率分布(和为1),明确表现出类别的互斥性。
* **多标签分类任务 (Multi-label Classification):**
* **首选 Sigmoid (每个输出神经元一个):** 每个标签独立判断其是否存在(概率),标签之间不互斥。
* **回归任务 (Regression):**
* **无激活函数 (Linear / Identity):** `f(x) = x`。输出可以是任意实数。
* **ReLU:** 如果已知目标值总是非负(如房价、长度、像素强度)。
* **Softplus (近似平滑的ReLU):** `f(x) = ln(1 + exp(x))`。强制输出为正且平滑,但计算量稍大。有时用于约束输出为正的回归。
* **Sigmoid/Tanh:** 如果目标值需要被压缩到特定范围(如`(0, 1)`或`(-1, 1)`)。需注意饱和问题。? 三、 选择技巧与最佳实践
- 从 ReLU 开始: 对于大多数新的前馈网络(MLP, CNN),隐藏层优先尝试 ReLU。它简单、高效、效果通常不错。
- 遇到问题再换: 如果训练不稳定、收敛慢、大量神经元死亡,优先尝试 Leaky ReLU 或 ELU。它们在解决ReLU缺陷的同时保持了良好的性能。
- 输出层严格按任务选: 输出层的选择主要由任务性质决定(概率分布、范围限制)。不要轻易在输出层使用隐藏层常用的ReLU等函数(Softmax/Sigmoid/Linear除外)。
- 考虑深层网络特性:
- 在极深的网络中(如ResNet, Transformer),梯度流动是关键。ReLU及其变体(Leaky, PReLU, ELU)、Swish、GELU是主流。
- 残差连接(Skip Connections) 本身极大地缓解了梯度消失,使得ReLU族在这些架构中也能很好地工作。Transformer常用GELU/Swish。
- 权重初始化匹配激活函数:
- ReLU/PReLU/Leaky ReLU: 使用 He初始化 (Kaiming初始化) - 方差缩放因子为
2 / fan_in✅ - Sigmoid/Tanh: 使用 Xavier/Glorot初始化 - 方差缩放因子为
1 / fan_in或2 / (fan_in + fan_out)✅ - ELU/Swish/GELU: 通常也可以用He初始化或专门的初始化策略(如Transformer中GELU常配特定初始化)。查阅相关论文/框架实践。
- ReLU/PReLU/Leaky ReLU: 使用 He初始化 (Kaiming初始化) - 方差缩放因子为
- 监控激活状态: 在训练过程中或训练后,观察各层神经元激活值的分布和稀疏性。如果发现大量神经元长期输出为0(Dying ReLU),考虑换用Leaky ReLU/ELU或调整学习率/初始化。
- 实验验证是关键: 没有绝对最优的激活函数。在基线模型上尝试不同的激活函数组合(尤其是隐藏层)是提升模型性能的标准流程之一。 在小数据集或子集上进行快速实验来筛选。
- 关注框架默认选项: PyTorch的Linear/Conv层默认使用ReLU(需要手动指定时才换)。TensorFlow各层激活函数参数默认通常是None(线性)。了解你所用框架的默认行为。
? 总结
- 隐藏层: ReLU (默认起点) -> 有问题/追求更高 -> Leaky ReLU / ELU -> Swish / GELU (尤其在Transformer中)。
- 输出层: 严格按任务选:Sigmoid (二分类/多标签) / Softmax (多分类) / Linear (回归) / 约束ReLU/Softplus (正数回归)。
- 初始化匹配: ReLU族用He初始化,Sigmoid/Tanh用Xavier初始化。
- 实验是王道: 没有银弹,在具体任务和数据上尝试对比是最终手段。
遵循这些技巧,你可以更有方向性地为你的神经网络选择更合适的激活函数,从而提高模型的性能和训练效率。??
bp神经网络和卷积神经网络区别是什么
结构、原理、应用场景等方面都存在一定的差异。以下是对这两种神经网络的比较: 基本结构 BP神经网络是一种多层前馈神经网络,由输入层、隐藏层和输出
2024-07-03 10:12:47
人工神经网络的原理及仿真实例
人工神经网络(Artificial Neural Network, ANN),亦称为神经网络(Neural Networks, NN),是由大量处理单元(神经
资料下载
![]() ah此生不换
2022-04-11 11:28:35
ah此生不换
2022-04-11 11:28:35
BP神经网络的研究进展
通过对传统BP神经网络缺点的分析,从参数选取、BP算法、激活函数、网络结构4个方面综述了其改进方法。介绍了各种方法的原理、应用背景及其在BP
资料下载
![]() 姚小熊27
2021-06-01 11:28:43
姚小熊27
2021-06-01 11:28:43
人工神经网络的发展和分类详细说明
节点代表一种特定的输出函数,称为激励函数( activation function )。每两个节点间的连接都代表一个对于通过该连接信号的加权值, 称之为权重, 这相当于人工
资料下载
佚名
2021-03-04 13:56:00
卷积神经网络激活函数的作用
卷积神经网络(Convolutional Neural Networks, CNNs)是深度学习中一种重要的神经网络结构,广泛应用于图像识别、语音识别、自然语言处理等领域。在卷积
2024-07-03 09:18:34
神经网络初学者的激活函数指南

作者:MouâadB.来源:DeepHubIMBA如果你刚刚开始学习神经网络,激活函数的原理一开始可能很难理解。但是如果你想开发强大的神经网络,
2023-04-21 09:28:42
如何构建神经网络?
原文链接:http://tecdat.cn/?p=5725 神经网络是一种基于现有数据创建预测的计算系统。如何构建神经网络?神经网络包括:输入层
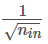
- 如何分清usb-c和type-c的区别
- 中国芯片现状怎样?芯片发展分析
- vga接口接线图及vga接口定义
- 芯片的工作原理是什么?
- 华为harmonyos是什么意思,看懂鸿蒙OS系统!
- 什么是蓝牙?它的主要作用是什么?
- ssd是什么意思
- 汽车电子包含哪些领域?
- TWS蓝牙耳机是什么意思?你真的了解吗
- 什么是单片机?有什么用?
- 升压电路图汇总解析
- plc的工作原理是什么?
- 再次免费公开一肖一吗
- 充电桩一般是如何收费的?有哪些收费标准?
- ADC是什么?高精度ADC是什么意思?
- dtmb信号覆盖城市查询
- EDA是什么?有什么作用?
- 苹果手机哪几个支持无线充电的?
- type-c四根线接法图解
- 华为芯片为什么受制于美国?
- 怎样挑选路由器?
- 元宇宙概念股龙头一览
- 锂电池和铅酸电池哪个好?
- 什么是场效应管?它的作用是什么?
- 如何进行编码器的正确接线?接线方法介绍
- 虚短与虚断的概念介绍及区别
- 晶振的作用是什么?
- 大疆无人机的价格贵吗?大约在什么价位?
- 苹果nfc功能怎么复制门禁卡
- amoled屏幕和oled区别
- 单片机和嵌入式的区别是什么
- 复位电路的原理及作用
- BLDC电机技术分析
- dsp是什么意思?有什么作用?
- 苹果无线充电器怎么使用?
- iphone13promax电池容量是多少毫安
- 芯片的组成材料有什么
- 特斯拉充电桩充电是如何收费的?收费标准是什么?
- 直流电机驱动电路及原理图
- 传感器常见类型有哪些?
- 自举电路图
- 通讯隔离作用
- 苹果笔记本macbookpro18款与19款区别
- 新斯的指纹芯片供哪些客户
- 伺服电机是如何进行工作的?它的原理是什么?
- 无人机价钱多少?为什么说无人机烧钱?
- 以太网VPN技术概述
- 手机nfc功能打开好还是关闭好
- 十大公认音质好的无线蓝牙耳机
- 元宇宙概念龙头股一览
湘ICP备2023036445号-105