

机器学习分类
更多
好的,我们来详细解释一下机器学习中的分类问题及相关分类体系。
“分类”在机器学习中主要有两个层面的含义:
- 机器学习任务的一种:指具体的预测任务类型。
- 机器学习模型的类别:指不同类型的机器学习算法或方法体系。
以下我们从这两个主要角度以及更细分的维度来进行说明:
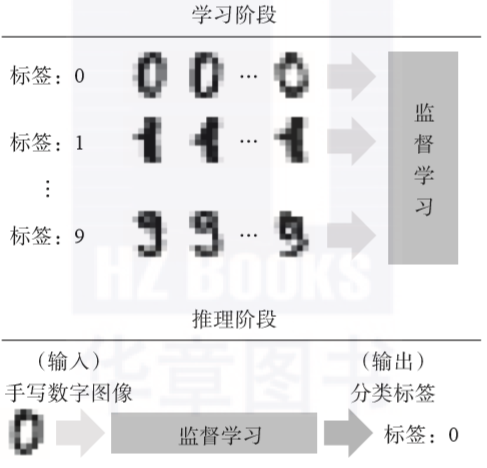
一、作为任务的分类
这是监督学习中最常见的任务之一。
- 定义:给定输入数据(特征),模型需要预测该数据所属的预先定义的离散类别标签(也称为目标变量)。
- 核心特点:
- 输出是离散的:结果只能是有限集合中的某一个类别(例如,“是/否”、“猫/狗/鸟”、“高/中/低”、“垃圾邮件/正常邮件”、“病A/病B/无病”)。
- 有标签数据:训练数据包含输入特征及其对应的真实类别标签。
- 与回归的区别:回归任务的输出是连续的数值(例如,预测房价、预测销售额)。分类预测“是什么类别”,回归预测“是多少数值”。
- 分类示例:
- 图像识别:输入图像 -> 输出类别(“猫”,“狗”,“汽车”...)
- 垃圾邮件检测:输入邮件文本 -> 输出类别(“垃圾邮件”,“正常邮件”)
- 医疗诊断:输入患者体征和检查数据 -> 输出类别(“健康”,“流感”,“肺炎”)
- 情感分析:输入一段评论 -> 输出类别(“正面”,“中性”,“负面”)
- 常见子类型:
- 二分类:只有两个互斥的类别(例如:垃圾邮件/非垃圾邮件,点击/未点击)。
- 多分类:有两个以上的互斥类别(例如:数字识别0-9,图像中的物体类型)。
- 多标签分类:一个样本可以同时属于多个类别(例如:一篇新闻可能同时属于“政治”和“经济”标签;一幅图像可能同时包含“天空”、“山”、“河流”)。
- 评估指标:准确率、精确率、召回率、F1分数、AUC-ROC曲线、混淆矩阵等。
二、作为模型/算法类别的分类(机器学习方法体系的分类)
这是指对机器学习的模型、算法或范式本身进行分类。以下是几种常见的、不同维度的分类方式:
-
根据训练数据是否有标签: 类别 定义 核心任务/方法 典型算法 监督学习 训练数据包含输入特征 X 和对应的预期输出标签/值 y。模型学习从 X 到 y 的映射关系。 分类、回归 逻辑回归、决策树、支持向量机(SVM)、K近邻(KNN)、线性回归、神经网络(用于分类/回归)等 无监督学习 训练数据只有输入特征 X,没有标签 y。模型发现数据中隐藏的结构、模式或关系。 聚类、降维、异常检测、关联规则挖掘 K均值聚类、层次聚类、DBSCAN、主成分分析(PCA)、t-SNE、Apriori、自编码器等 半监督学习 训练数据包含少量带标签数据和大量无标签数据。模型利用无标签数据的结构信息辅助学习。 利用无标签数据增强带标签数据的学习效果 标签传播、基于图的半监督方法、自训练、协同训练等 -
根据模型的学习方式/是否增量学习: 类别 定义 特点 批量学习 模型在所有训练数据上一次性训练完成。如需加入新数据,需要从头重新训练整个模型。 训练计算量大,可能无法适应快速变化的数据。 在线学习 模型逐个或按小批量接收新数据样本,并增量式地更新自身参数。 适用于数据流、资源有限、需实时适应变化的环境。需注意灾难性遗忘问题。 强化学习 智能体(Agent) 在与环境(Environment) 的交互中,通过不断尝试和接收奖励(Reward) 或惩罚,学习在特定状态下选择最优动作(Action) 的策略,以最大化长期累积奖励。 常用于游戏AI、机器人控制、自动驾驶、推荐系统、资源管理等决策优化问题。 -
根据模型的结构/表示能力: 类别 定义 典型算法/结构 特点 线性和广义线性模型 模型对特征的组合是线性(或通过链接函数变换后线性)的。 线性回归、逻辑回归、线性判别分析(LDA) 简单、计算高效、可解释性好。但对复杂非线性模式建模能力有限。 基于树的模型 通过递归地将特征空间划分为一系列决策区域来构建模型。模型由一组“If-Else”决策规则组成。 决策树、随机森林、梯度提升树(如XGBoost, LightGBM, CatBoost) 易于理解和解释(可视化)、对数据分布假设少、能处理数值/类别特征。随机森林和GBDT是强大且常用的集成方法。 基于核的方法 利用“核技巧”,将非线性问题映射到高维特征空间,在该空间中问题可能变成线性可分的。 支持向量机(SVM) 对于高维数据或样本量不是特别大的情况下效果不错。对参数和核函数选择敏感。 神经网络/深度学习 受生物神经元启发,由多层“神经元”(非线性计算单元)组成,通过多层次的非线性变换来学习数据的复杂模式表示。 多层感知机(MLP)、卷积神经网络(CNN)、循环神经网络(RNN)、长短期记忆网络(LSTM)、Transformer、自编码器(AE)等 模型表示能力极强,在图像、语音、自然语言处理等领域取得革命性突破。通常需要大量数据和计算资源,可解释性较差。 贝叶斯方法 基于贝叶斯定理进行概率推断的模型,显式地建模特征和标签之间的概率关系(条件概率)。 朴素贝叶斯分类器、高斯过程(GP)、贝叶斯网络 天然适合处理概率问题,可以方便地融入先验知识。朴素贝叶斯简单高效;贝叶斯网络可进行因果推断。 -
工程与应用维度:
- 批处理vs实时处理: 处理数据是批量一次性处理还是实时流式处理。
- 集中式训练vs分布式训练: 模型训练是在单机进行还是分布到多台机器/多个设备进行。
- 云端部署vs边缘部署: 训练好的模型是部署在远程服务器(云)还是在靠近数据源的本地设备上(边缘端)。
- 经典模型vs深度学习模型: 根据不同问题特点选择合适的模型类型。
核心要点总结
- 明确语境:当提到“分类”时,首先要区分是指具体的预测任务(预测离散类别),还是指机器学习方法的类别划分。
- 任务分类:作为任务的分类是监督学习的关键类型,目标是预测离散标签(二分类、多分类、多标签)。
- 模型分类维度多:机器学习方法的分类可以从多个维度进行:有无标签(监督/无监督/半监督)、学习方式(批量/在线/强化)、模型结构(线性/树/核/深度学习/贝叶斯)等。
- 没有“银弹”:不存在一种在所有场景下都最优的机器学习算法或模型类型。 模型的选择取决于:
- 具体任务(是分类还是回归?是无监督还是有监督?)
- 数据规模、质量和特征类型
- 所需的计算资源(时间、内存、算力)
- 对模型可解释性的要求
- 部署环境限制等。
- 深度学习的地位:深度学习方法(尤其是神经网络)由于其强大的表征学习能力,已成为当前人工智能领域的核心技术引擎,在感知类任务(图像、语音、NLP)中占据统治地位,并在许多领域颠覆了传统的机器学习方法。
理解机器学习的不同分类体系,有助于你更系统地把握这个领域,并为解决实际问题时选择合适的工具和方法提供指导框架。你想重点了解其中哪一部分呢?
基于机器学习的恶意代码检测分类
基于特征码匹配的静态分析方法提取的特征滞后于病毒发展,且不能检测出未知病毒。为此,从病毒反编译文件及其灰度图出发进行特征提取及融合,采用机器学习中的随机森林(RF)算法对恶意代码家族进行
资料下载
佚名
2021-06-10 11:03:15
融合文本分类和摘要的多任务学习摘要模型
文本摘要应包含源文本中所有重要信息,传统基于编码器-解码器架构的摘要模型生成的摘要准确性较低。根据文本分类和文本摘要的相关性,提出一种多任务学习摘要模型。从文本
资料下载
佚名
2021-04-27 16:18:58
基于情感字典和机器学习的股市舆情情感分类可视化Web
本文档的主要内容详细介绍的是基于情感字典和机器学习的股市舆情情感分类可视化Web的资料免费下载
资料下载
佚名
2021-03-01 09:28:23
7天热门专题
 换一换
换一换
- 如何分清usb-c和type-c的区别
- 中国芯片现状怎样?芯片发展分析
- vga接口接线图及vga接口定义
- 芯片的工作原理是什么?
- 华为harmonyos是什么意思,看懂鸿蒙OS系统!
- 什么是蓝牙?它的主要作用是什么?
- ssd是什么意思
- 汽车电子包含哪些领域?
- TWS蓝牙耳机是什么意思?你真的了解吗
- 什么是单片机?有什么用?
- 升压电路图汇总解析
- plc的工作原理是什么?
- 再次免费公开一肖一吗
- 充电桩一般是如何收费的?有哪些收费标准?
- ADC是什么?高精度ADC是什么意思?
- EDA是什么?有什么作用?
- dtmb信号覆盖城市查询
- 中科院研发成功2nm光刻机
- 苹果手机哪几个支持无线充电的?
- type-c四根线接法图解
- 华为芯片为什么受制于美国?
- 怎样挑选路由器?
- 元宇宙概念股龙头一览
- 锂电池和铅酸电池哪个好?
- 什么是场效应管?它的作用是什么?
- 如何进行编码器的正确接线?接线方法介绍
- 虚短与虚断的概念介绍及区别
- 晶振的作用是什么?
- 大疆无人机的价格贵吗?大约在什么价位?
- 苹果nfc功能怎么复制门禁卡
- 单片机和嵌入式的区别是什么
- amoled屏幕和oled区别
- 复位电路的原理及作用
- BLDC电机技术分析
- dsp是什么意思?有什么作用?
- 苹果无线充电器怎么使用?
- iphone13promax电池容量是多少毫安
- 芯片的组成材料有什么
- 特斯拉充电桩充电是如何收费的?收费标准是什么?
- 直流电机驱动电路及原理图
- 传感器常见类型有哪些?
- 自举电路图
- 通讯隔离作用
- 苹果笔记本macbookpro18款与19款区别
- 新斯的指纹芯片供哪些客户
- 伺服电机是如何进行工作的?它的原理是什么?
- 无人机价钱多少?为什么说无人机烧钱?
- 以太网VPN技术概述
- 手机nfc功能打开好还是关闭好
- 十大公认音质好的无线蓝牙耳机
湘ICP备2023036445号-105