

机器学习程序代码大全
更多
以下是常用的机器学习代码示例(Python),涵盖数据预处理、模型训练、评估及可视化等关键步骤:
1. 数据预处理
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
# 加载数据
data = pd.read_csv('data.csv')
# 处理缺失值
data = data.fillna(data.mean()) # 用均值填充数值型缺失值
# 划分特征与标签
X = data.drop('target', axis=1)
y = data['target']
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)
# 特征标准化
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)2. 逻辑回归分类
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score
# 创建模型
model = LogisticRegression(max_iter=1000)
# 训练模型
model.fit(X_train, y_train)
# 预测
y_pred = model.predict(X_test)
# 评估
print("准确率:", accuracy_score(y_test, y_pred))3. 随机森林回归
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import mean_squared_error
# 训练模型
reg = RandomForestRegressor(n_estimators=100, random_state=42)
reg.fit(X_train, y_train)
# 预测与评估
y_pred = reg.predict(X_test)
mse = mean_squared_error(y_test, y_pred)
print("均方误差:", mse)4. 支持向量机(SVM)
from sklearn.svm import SVC
from sklearn.metrics import classification_report
# 训练模型
svm_model = SVC(kernel='rbf', C=1.0)
svm_model.fit(X_train, y_train)
# 输出详细评估报告
print(classification_report(y_test, svm_model.predict(X_test)))5. K均值聚类
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt
# 初始化模型
kmeans = KMeans(n_clusters=3, random_state=42)
clusters = kmeans.fit_predict(X_train)
# 可视化聚类结果
plt.scatter(X_train[:,0], X_train[:,1], c=clusters, cmap='viridis')
plt.show()6. 神经网络(使用TensorFlow/Keras)
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
# 创建模型
model = Sequential([
Dense(64, activation='relu', input_shape=(X_train.shape[1],)),
Dense(32, activation='relu'),
Dense(1, activation='sigmoid') # 二分类输出层
])
# 编译模型
model.compile(optimizer='adam',
loss='binary_crossentropy',
metrics=['accuracy'])
# 训练模型
history = model.fit(
X_train, y_train,
epochs=50,
batch_size=32,
validation_split=0.2
)
# 评估测试集
test_loss, test_acc = model.evaluate(X_test, y_test)
print("测试集准确率:", test_acc)7. 主成分分析(PCA)降维
from sklearn.decomposition import PCA
import matplotlib.pyplot as plt
# 降维到2D
pca = PCA(n_components=2)
X_pca = pca.fit_transform(X_train)
# 可视化降维结果
plt.scatter(X_pca[:,0], X_pca[:,1], c=y_train)
plt.show()关键库说明:
- Scikit-learn:传统机器学习算法(分类/回归/聚类)
- Pandas:数据处理与清洗
- NumPy:科学计算基础库
- Matplotlib/Seaborn:数据可视化
- TensorFlow/Keras:深度学习模型构建
典型应用场景:
| 任务类型 | 推荐算法 |
|---|---|
| 图像分类 | CNN(卷积神经网络) |
| 文本分类 | LSTM/Transformer |
| 结构化数据预测 | XGBoost/Random Forest |
| 无标签数据分组 | K-Means/DBSCAN |
| 降维可视化 | PCA/t-SNE |
重要提示:
- 实际应用需调整超参数(学习率、树数量、层数等)
- 分类任务注意处理类别不平衡问题
- 使用交叉验证避免过拟合:
from sklearn.model_selection import cross_val_score
建议根据具体任务选择合适算法,参考官方文档调整参数(如Scikit-learn官网提供详细API说明)。
基于LabVIEW和单片机实现DSP应用程序代码的自举模块设计
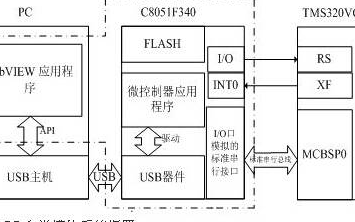
针对现有DSP自举模块普遍存在程序代码更新不便的缺陷,提出了一种可便捷高效地在线更新用户应用程序代码的DSP自举模块。该模块由基于LabVIEW的图形用户界面(GUI)软件与C8051F340单片机
2020-07-16 20:36:33
如何开发固件代码和驱动程序代码?
一个简单的函数使用CY7C634 13C,所有IO引脚只输出用于控制LED,无输入,无中断。如何开发固件代码和驱动程序代码,有没有简单的样例代码
2019-08-20 06:17:15
7天热门专题
 换一换
换一换
- 如何分清usb-c和type-c的区别
- 中国芯片现状怎样?芯片发展分析
- vga接口接线图及vga接口定义
- 芯片的工作原理是什么?
- 华为harmonyos是什么意思,看懂鸿蒙OS系统!
- 什么是蓝牙?它的主要作用是什么?
- ssd是什么意思
- 汽车电子包含哪些领域?
- TWS蓝牙耳机是什么意思?你真的了解吗
- 什么是单片机?有什么用?
- 升压电路图汇总解析
- plc的工作原理是什么?
- 再次免费公开一肖一吗
- 充电桩一般是如何收费的?有哪些收费标准?
- ADC是什么?高精度ADC是什么意思?
- EDA是什么?有什么作用?
- dtmb信号覆盖城市查询
- 苹果手机哪几个支持无线充电的?
- type-c四根线接法图解
- 华为芯片为什么受制于美国?
- 怎样挑选路由器?
- 元宇宙概念股龙头一览
- 锂电池和铅酸电池哪个好?
- 什么是场效应管?它的作用是什么?
- 如何进行编码器的正确接线?接线方法介绍
- 虚短与虚断的概念介绍及区别
- 晶振的作用是什么?
- 大疆无人机的价格贵吗?大约在什么价位?
- 苹果nfc功能怎么复制门禁卡
- amoled屏幕和oled区别
- 单片机和嵌入式的区别是什么
- 复位电路的原理及作用
- BLDC电机技术分析
- dsp是什么意思?有什么作用?
- 苹果无线充电器怎么使用?
- iphone13promax电池容量是多少毫安
- 芯片的组成材料有什么
- 特斯拉充电桩充电是如何收费的?收费标准是什么?
- 直流电机驱动电路及原理图
- 传感器常见类型有哪些?
- 自举电路图
- 通讯隔离作用
- 苹果笔记本macbookpro18款与19款区别
- 新斯的指纹芯片供哪些客户
- 伺服电机是如何进行工作的?它的原理是什么?
- 无人机价钱多少?为什么说无人机烧钱?
- 以太网VPN技术概述
- 手机nfc功能打开好还是关闭好
- 十大公认音质好的无线蓝牙耳机
- 元宇宙概念龙头股一览
湘ICP备2023036445号-105