

机器学习聚类计算方法
好的,机器学习中的聚类(Clustering)是一种无监督学习方法,旨在将数据集中的样本划分为若干个内在的、相似的组或簇(Cluster),使得同一簇内的样本彼此相似,而不同簇之间的样本尽可能不同。
以下是几种主要的聚类计算方法(算法):
-
基于原型(Prototype-Based)的聚类:
- 核心思想: 每个簇由一个“原型”(代表点)表示。样本被分配到距离其最近的原型所代表的簇中。算法会迭代地优化这些原型的位置。
- 代表算法:
- K-Means: 最经典、最常用的方法之一。
- 原理:
- 随机选择 K 个点作为初始聚类中心(质心)。
- 分配步骤: 计算每个样本到 K 个质心的距离(通常是欧氏距离),将其分配给距离最近的质心所属的簇。
- 更新步骤: 重新计算每个簇的质心(该簇中所有样本的均值)。
- 重复步骤 2 和 3,直到质心的位置变化很小或达到最大迭代次数。
- 特点: 简单、高效、适用于大规模数据集;需要预先指定簇数 K;对初始质心选择敏感;假设簇是凸形的(大致球形);对噪声和离群点敏感(因为它们会显著影响质心计算)。
- 原理:
- K-Medoids (PAM - Partitioning Around Medoids):
- 原理: 与 K-Means 类似,但使用簇中实际存在的样本(Medoid)作为原型,而不是虚拟的均值点(质心)。Medoid 是簇内与其他所有样本平均距离最小的那个样本。
- 特点: 比 K-Means 对噪声和离群点更鲁棒(因为原型是真实的数据点),但计算复杂度更高(需要计算样本间距离);同样需要指定 K。
- K-Means: 最经典、最常用的方法之一。
-
基于密度(Density-Based)的聚类:
- 核心思想: 簇是数据空间中样本密集的区域,被稀疏的区域分隔开。算法寻找被低密度区域分隔的高密度区域。
- 代表算法:
- DBSCAN (Density-Based Spatial Clustering of Applications with Noise): 非常流行的方法,特别擅长处理任意形状的簇和噪声。
- 原理:
- 基于两个参数:
ε(eps, 邻域半径) 和MinPts(核心点所需的最小邻域样本数)。 - 如果一个点的 ε-邻域(即距离该点小于或等于ε的区域)内包含至少
MinPts个样本,则该点被标记为核心点。 - 从任意一个核心点开始,找出所有从该点密度可达的点(即通过一系列密集相连的样本能到达的点),这些点形成一个簇。
- 如果某个点不能被任何核心点密度可达,则被标记为噪声。
- 基于两个参数:
- 特点: 能发现任意形状的簇;对噪声有天然抵抗力(能识别并将噪声点排除在簇外);不需要预先指定簇的数量 K;主要参数(
ε,MinPts)的设置需要一定的经验或尝试;在高维数据上可能表现不佳(“维度灾难”);对于密度差异显著的簇处理能力较弱。
- 原理:
- DBSCAN (Density-Based Spatial Clustering of Applications with Noise): 非常流行的方法,特别擅长处理任意形状的簇和噪声。
-
层次(Hierarchical)聚类:
- 核心思想: 通过计算样本间的距离相似性(或差异度),以树状结构(树状图 - Dendrogram) 的形式组织样本。层次结构可以代表不同粒度的聚类结果。
- 方式:
- 凝聚(Agglomerative) - 自底向上: 每个样本开始时是单独的簇。反复找出两个最相似(距离最小)的簇,将它们合并,直到所有样本都在一个簇中(或者达到了预定的簇数量)。
- 分裂(Divisive) - 自顶向下: 所有样本开始时在一个簇中。递归地将一个簇分裂成两个(或多个)子簇,直到每个样本都自成簇(或者达到了预定的簇数量)。凝聚法更常见。
- 簇间距离度量(决定哪些簇合并):
- 最小距离(单链接): 两个簇中最近的两个样本之间的距离。容易形成细长的链(“链式效应”)。
- 最大距离(全链接): 两个簇中最远的两个样本之间的距离。趋向于产生紧凑、大小相似的簇,但可能使大簇被拆开。
- 平均距离(均链接): 两个簇中所有成对样本距离的平均值。折衷方案,常用。
- 质心距离: 两个簇质心之间的距离。
- Ward's方法(离差平方和): 合并两个簇后总体簇内平方和(Inertia)增加最小的簇对。趋向于产生大小相近的簇。
- 特点: 提供层次关系(树状图可视化);不需要预先指定 K(但最终仍需在某个层次“切割”树状图以得到具体簇划分);凝聚法的计算复杂度通常较高(O(n³) 或 O(n² log n)),不太适合超大数据集;链式或反向链接效应可能影响结果;树状图有助于解释数据。
-
基于概率模型(Probabilistic Model-Based)的聚类:
- 核心思想: 假设数据是由一个混合概率分布生成。每个簇对应该混合分布中的一个子成分(component)。算法通过最大似然估计(Maximum Likelihood Estimation)或其他统计推断方法,确定样本最可能属于哪个子成分(簇)。
- 代表算法:
- 高斯混合模型(Gaussian Mixture Model, GMM): 最常用的概率聚类方法。
- 原理: 假设数据由 K 个多元高斯分布(正态分布)混合而成。每个高斯分布有自己的均值向量(中心位置)、协方差矩阵(形状、方向、大小)和混合权重(表示该分布的重要性)。
- 使用期望最大化算法(Expectation-Maximization Algorithm, EM) 迭代优化模型参数:
- E步(Expectation): 给定当前模型参数,计算每个样本属于各个子高斯分布(簇)的后验概率(Responsibility)。
- M步(Maximization): 使用 E 步计算出的后验概率,更新高斯分布的均值、协方差和混合权重,使数据出现的似然性(Likelihood) 最大化。
- 特点: 提供样本属于每个簇的概率(软聚类);可以模拟不同形状、大小、方向的簇(通过协方差矩阵);比较灵活;需要指定 K;EM 算法可能收敛到局部最优解;对模型假设(如数据是否接近高斯分布)比较敏感;计算复杂度比 K-Means 高。
- 高斯混合模型(Gaussian Mixture Model, GMM): 最常用的概率聚类方法。
-
其他值得注意的聚类方法:
- 谱聚类(Spectral Clustering): 将数据点视为图的节点,点之间的相似度构成边权重。通过对图的拉普拉斯矩阵进行特征分解,在低维空间中完成聚类(如使用 K-Means)。擅长处理非凸形状的数据,在图像分割等领域应用广泛。需要指定 K。
- 模糊 C-Means(FCM): K-Means 的模糊版本,允许样本以隶属度(Membership) 的形式同时属于多个簇(隶属度总和为 1)。适用于重叠簇的情况。
- 自组织映射(Self-Organizing Map, SOM): 一种将高维数据映射到低维(通常是二维)网格的神经网络方法,网格节点(神经元)通过竞争学习形成簇结构,常用于数据可视化和探索。
- 基于网格(Grid-Based)的聚类: 将数据空间划分为网格单元,然后在网格单元上进行操作(如合并密集单元成簇)。速度快,适合空间数据挖掘(如 STING)。
- 图聚类(Graph Clustering): 在复杂网络(社会网络、生物网络、引用网络)中,使用各种图划分方法(如模块度优化)进行社区发现(Community Detection)。
选择聚类方法时需要考虑的因素:
- 数据集特征: 规模、维度、样本间距离/相似性、是否存在噪声/离群点、数据的分布形状(球形、任意形状)等。
- 预期目标: 是否需要指定簇数?需要硬聚类(每个点唯一簇)还是软聚类(隶属度)?是否期望发现任意形状的簇?是否需要处理噪声?
- 算法可解释性: 结果是否容易解释(如层次聚类的树状图提供了层次信息)。
- 计算效率: 数据量大时,效率很重要(如 K-Means 通常非常高效)。
- 参数设置: 不同算法需要不同的参数(K-Means的K, DBSCAN的ε和MinPts, 层次聚类的簇间距度量...),理解参数意义并进行调优是必要的。
没有一个“万能”的最佳聚类算法,选择哪种方法最合适取决于具体的应用场景和数据集特性。通常在实践中会尝试多种方法并进行比较评估(如使用轮廓系数等指标)来确定最优解。
下表总结了主要聚类方法的特点:
| 聚类方法类型 | 核心思想 | 代表算法 | 主要特点与优势 | 主要弱点与局限 | 需要指定K |
|---|---|---|---|---|---|
| 基于原型 | 每个簇由原型表示 | K-Means | 简单、高效、易于实现,适合大规模数据,簇形趋近凸形 | 对初始点敏感,需指定K,对噪声和离群点敏感 | ✓ |
| K-Medoids (PAM) | 抗噪声能力强,原型为实际数据点 | 计算成本高于K-Means,需指定K | ✓ | ||
| 基于密度 | 簇是高密度区域 | DBSCAN | 可处理任意形状簇,能识别噪声,不需指定K | 参数设置(ε,MinPts)需调整,高维数据效果差 | ✗ |
| 层次聚类 | 构建簇的树状层次结构 | AGNES(凝聚)/DIANA(分裂) | 提供层次关系,通过树状图可视化,结果可解释性高 | 计算成本较高(O(n³)/O(n² log n)),存在连锁效应 | (切割树) |
| 概率模型 | 数据来自混合概率分布 | 高斯混合模型(GMM) | 支持软聚类(概率),可建模不同形状/大小的簇 | 计算复杂度较高,对模型假设敏感,可能陷入局部最优 | ✓ |
| 谱聚类 | 在图谱空间进行聚类 | 多种变体 | 擅长处理非凸形状,尤其适合图结构数据 | 计算成本中等,需指定K,核函数选择影响效果 | ✓ |
希望这个总结对你有帮助!

EMC计算方法和EMC仿真(1) 计算方法简介
EMC计算方法概述2021/11/16大家好!我是ROHM的稻垣。本文是第16篇,从本文开始我们来谈一谈电磁兼容性(EMC)的计算方法和仿真。
2023-02-14 09:26:28
基于成对学习和图像聚类的肺癌亚型识别
基因诊断是近年来提高肺癌治愈率的一种新型且有效的方法,但这种方法存在基因检测时间长、费用高、侵入式取样损伤大的问题。文中提出了基于成对学习和图像
资料下载
佚名
2021-05-10 11:20:56
一种基于图熵极值理论的领域概念聚类方法
为在领域本体学习过程中实现最优同领域概念聚类并解决概念重叠问题,通过引入图熵极值理论,提出种新的领域概念
资料下载
佚名
2021-04-01 15:39:44
EMC计算方法和EMC仿真(4)
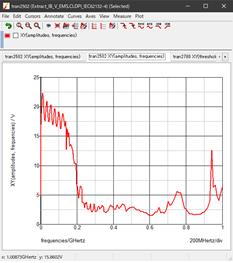
エンジニアコラム第19篇 EMC计算方法和EMC仿真(4)传导抗扰度(CI)的试行计算方法什么是IEC 62132-4 DPI法?大家好!我是ROHM的稻垣。
2023-02-14 09:26:26

金融机构使用案例分析机器学习算法——聚类clustering
在本文中,我们将讨论一个金融机构的实际使用案例,该案例使用-聚类clustering(一种流行的机器
2020-10-12 13:58:05
- 如何分清usb-c和type-c的区别
- 中国芯片现状怎样?芯片发展分析
- vga接口接线图及vga接口定义
- 芯片的工作原理是什么?
- 华为harmonyos是什么意思,看懂鸿蒙OS系统!
- 什么是蓝牙?它的主要作用是什么?
- ssd是什么意思
- 汽车电子包含哪些领域?
- TWS蓝牙耳机是什么意思?你真的了解吗
- 什么是单片机?有什么用?
- 升压电路图汇总解析
- plc的工作原理是什么?
- 再次免费公开一肖一吗
- 充电桩一般是如何收费的?有哪些收费标准?
- ADC是什么?高精度ADC是什么意思?
- dtmb信号覆盖城市查询
- EDA是什么?有什么作用?
- 中科院研发成功2nm光刻机
- 苹果手机哪几个支持无线充电的?
- type-c四根线接法图解
- 华为芯片为什么受制于美国?
- 怎样挑选路由器?
- 元宇宙概念股龙头一览
- 锂电池和铅酸电池哪个好?
- 如何进行编码器的正确接线?接线方法介绍
- 什么是场效应管?它的作用是什么?
- 虚短与虚断的概念介绍及区别
- 晶振的作用是什么?
- 大疆无人机的价格贵吗?大约在什么价位?
- amoled屏幕和oled区别
- 苹果nfc功能怎么复制门禁卡
- 单片机和嵌入式的区别是什么
- 复位电路的原理及作用
- BLDC电机技术分析
- dsp是什么意思?有什么作用?
- 苹果无线充电器怎么使用?
- iphone13promax电池容量是多少毫安
- 芯片的组成材料有什么
- 特斯拉充电桩充电是如何收费的?收费标准是什么?
- 直流电机驱动电路及原理图
- 传感器常见类型有哪些?
- 自举电路图
- 苹果笔记本macbookpro18款与19款区别
- 通讯隔离作用
- 新斯的指纹芯片供哪些客户
- 伺服电机是如何进行工作的?它的原理是什么?
- 无人机价钱多少?为什么说无人机烧钱?
- 以太网VPN技术概述
- 手机nfc功能打开好还是关闭好
- 十大公认音质好的无线蓝牙耳机
湘ICP备2023036445号-105