
资料下载


如何解决多源数据融合分析过程灵活性差和处理效率低的问题方法说明
分享资料个
大规模网络环境和大数据相关技术的发展对传统数据融合分析技术提出了新的挑战。针对目前多源数据融合分析过程灵活性差,处理效率低的问题,提出了一种基于相似连接的多源数据并行预处理方法,该方法采用了分治和并行的思想。首先,通过对多源数据中的相似语义进行统一,对个性语义进行保留的预处理方法提高了灵活性;其次,提出了一种改进的并行MapReduce框架,提高了相似连接的效率。实验结果表明,所提方法在保证数据完整性的基础上,使总的数据量减小了32%.与传统的MapReduce框架相比,改进后的框架在耗费时间方面减小了43. 91%,因此该方法可以有效提高多源数据融合分析的效率.
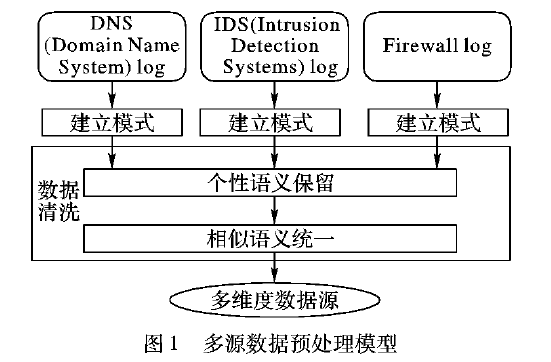
多源数据的预处理过程是网络环境进行安全分析的重要环节,根据实际的应用采取相应的具体措施山。一般性地,包括数据清理、数据格式转换、数椐简约等过程。其中数据清洗作为一个重要的环节,通过按照一定规则筛选数据,去除数据中的冗余部分。好的数据清洗方法不仅能够降低系统处理数据所需的时间,并且能够提高数据分析结果的准确度。为了对数据源进行灵活的数据清洗,尽量保留数据源的个性属性,本文采用基于相似连接的数据清洗方法。相似连接在相似对象匹配问题中得到广泛应用,如互联网、数据分析、数据库等,匹配对象也日益多样,如串、图、字符串和集合等。为了适应各种各样的场景和对象,相似连接相关算法也得到了优化和改进。无论是基于单行串行数据还是集合数据,或是基于树结构还是图结构,优化和改进的方案主要以提高效率和灵活性或伸缩性为主。为了解决单行申行的相似连接候选集过多的问题,等提出了一种基于划分的传递性的相似连接,该方法在相似匹配过程中利用传递性没有使用全部子串,从而减少了匹配的候选集数目,提升了匹配的效率。为了提升算法的灵活性与伸缩性,Wang等提出了种快速相似连接算法,该算法既考虑到了相似的准确度,又考虑到了相似连接属性的模糊度,可以进行灵活的筛选;然而随着大数据与云计算等的出现,由于数据量的庞大导致算法效率低,这也是相似连接算法面临的难题之一。

声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。 举报投诉
- 相关下载
- 相关文章




