
资料下载


TinyAnimal:Grove Vision AI上的动物识别实践
33391
分享资料个
描述
问题
有许多项目专注于边缘 AI/ML 的硬件。但在实际场景中,并没有在产品之上的软件侧学习细节的显着实践来展现,本文弥补了这一不足。
同时,该项目在一个廉价的边缘人工智能硬件上提供了完整的、可重现的EdgeML/TinyML动物识别工作流程,这在已知的现有项目中是很少见的。
硬件

该项目的硬件是Seeed SenseCAP K1100/A1100中的 Grove Vision AI 模块。官方商店有单机版的Grove Vision AI Module 。
Vision AI Module有一颗芯片:Himax HX6537-A。芯片上的mcu基于消费者比较陌生的ARC架构。主频是400Mhz,也不高。但最有趣的是 HX6537-A,具有快速XY SDRAM 内存架构来加速 TinyML,如 tensorflow lite 模型推理。我们稍后会看到这款芯片的性能。
工作流程
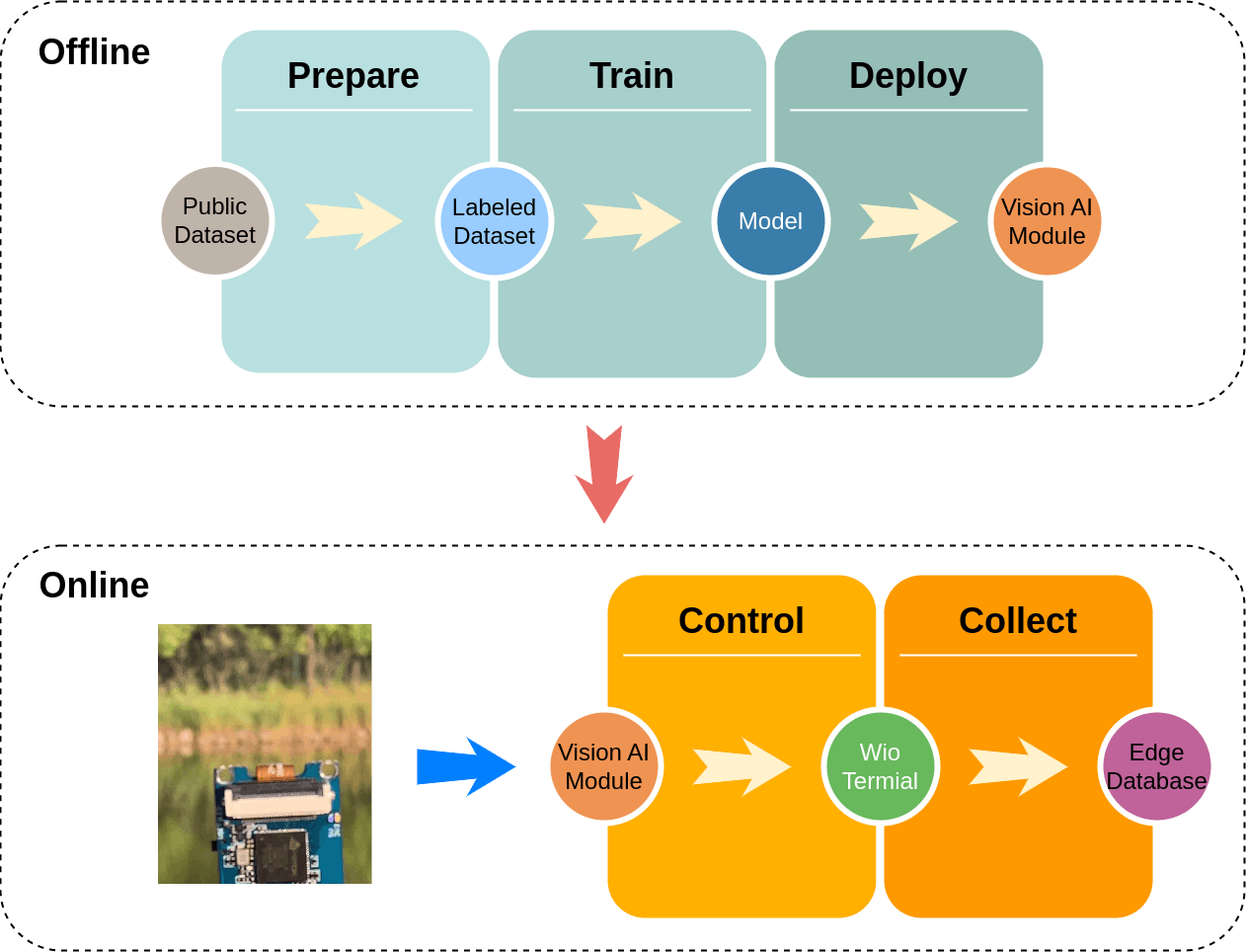
上面的工作流程很常见,也很清晰。我们只讨论一些有趣的需求:
- 该数据集是具有 9.6GB 图像的公共数据集。
这避免了样本太少或代表性不足的常见问题。
- 培训在当地完成。
这避免了样本太少或代表性不足的常见问题。
- 数据收集和实时分析是通过边缘数据库JoinBase完成的。
与 PostgreSQL 或 TimescaleDB 等常见数据库不同,JoinBase 直接接受 MQTT 消息。与云服务不同,JoinBase支持运行在边缘,可以在没有网络的环境下使用。最后,JoinBase 可免费用于商业用途,这也有利于边缘平台的进一步发展。
准备数据集
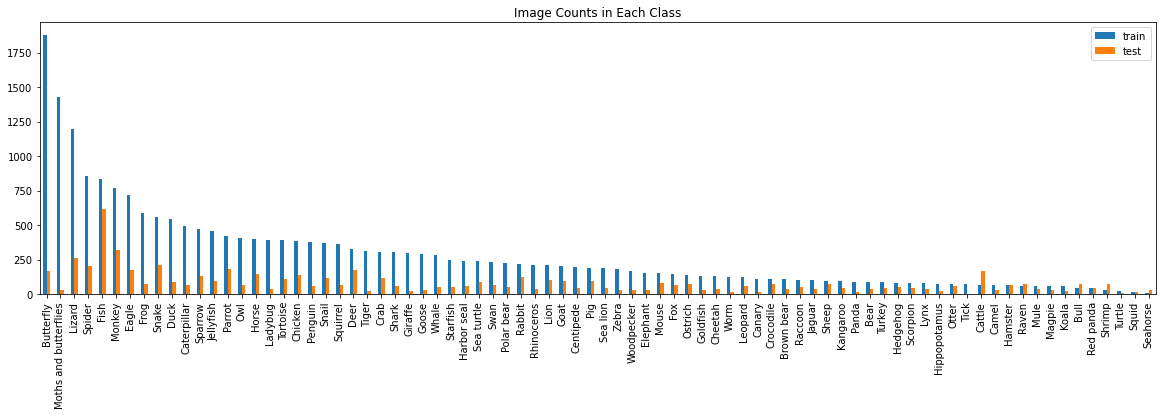
目前,针对野生动物或动物的工作边缘 AI 的公开研究并不多。使用了少数公开可用的动物数据集之一——来自 Kaggle 的动物检测图像数据集(称为“animals-80”数据集)。它包含 9.6GB 图像中的 80 只动物,对于常见的动物识别任务应该足够了。
准备训练数据
animals-80 数据集的好处是它已经被标记了。但是原始标签格式不是Yolov5标签格式。已经进行了准备工作。核心部分就是上图的预处理函数。请稍后的代码回购以获得更多信息。
火车
因为我们没有足够的资源来对完整的 9.6GB 训练进行完整的训练。因此,选择了animals-80数据集的一个子集。
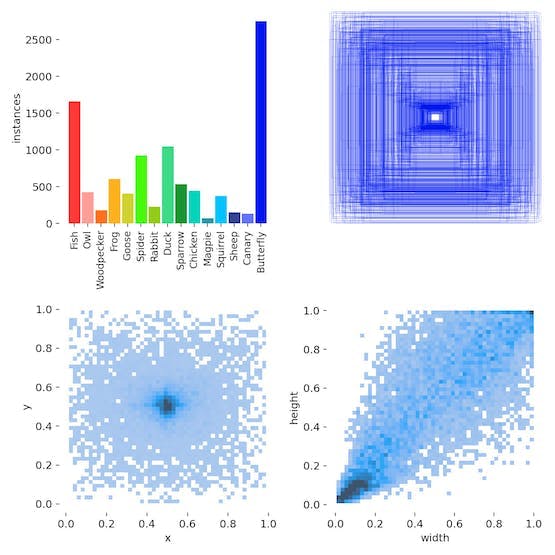
- 15-动物子集训练
我们使用 24c/48T Xeon Platinum 8260 处理器使用上面从官方示例中获得的命令进行训练。
python3 train.py --img 192 --batch 32 --epochs 200 --data data/animal.yaml --cfg yolov5n6-xiao.yaml --weights yolov5n6-xiao.pt --name animals --cache --project runs/train2
然而,两个小时后(是的,再次证明Don't use CPU to train even is a top Xeon SP),发现最后的识别效果很差。
主要指标非常低:精度为 0.6,召回率和 mAP_0.5 都在 0.3 左右。
事实上,这个结果接近于不起作用。
- 4-动物子集训练
让我们将可识别的动物种类减少为四种:蜘蛛、鸭子、喜鹊和蝴蝶,这当然是郊区野外最常见的动物。
注意,重新运行准备脚本以生成正确的data/animal.yaml.
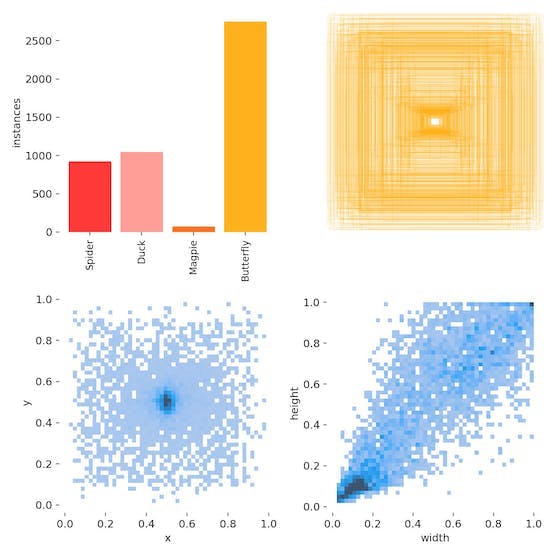
主要指标变得更好:精度约为 0.81,召回率和 mAP_0.5 约为 0.6。
我们将在后期推理试验和评估中回顾该模型的性能。可以只进行二元分类:一种动物和一种动物。但在这个项目中,我更期待在更复杂的场景下评估识别效果。
- YoLov5官方预训练模型的 4 动物子集训练
以上训练均由Seeed官方文档推荐完成。预训练模型yolov5n6-xiao可能缺乏良好的泛化能力。在这个项目中,我们尝试了一个 YoLOv5 官方最小的预训练模型yolov5n6,看看是否有一些差异。
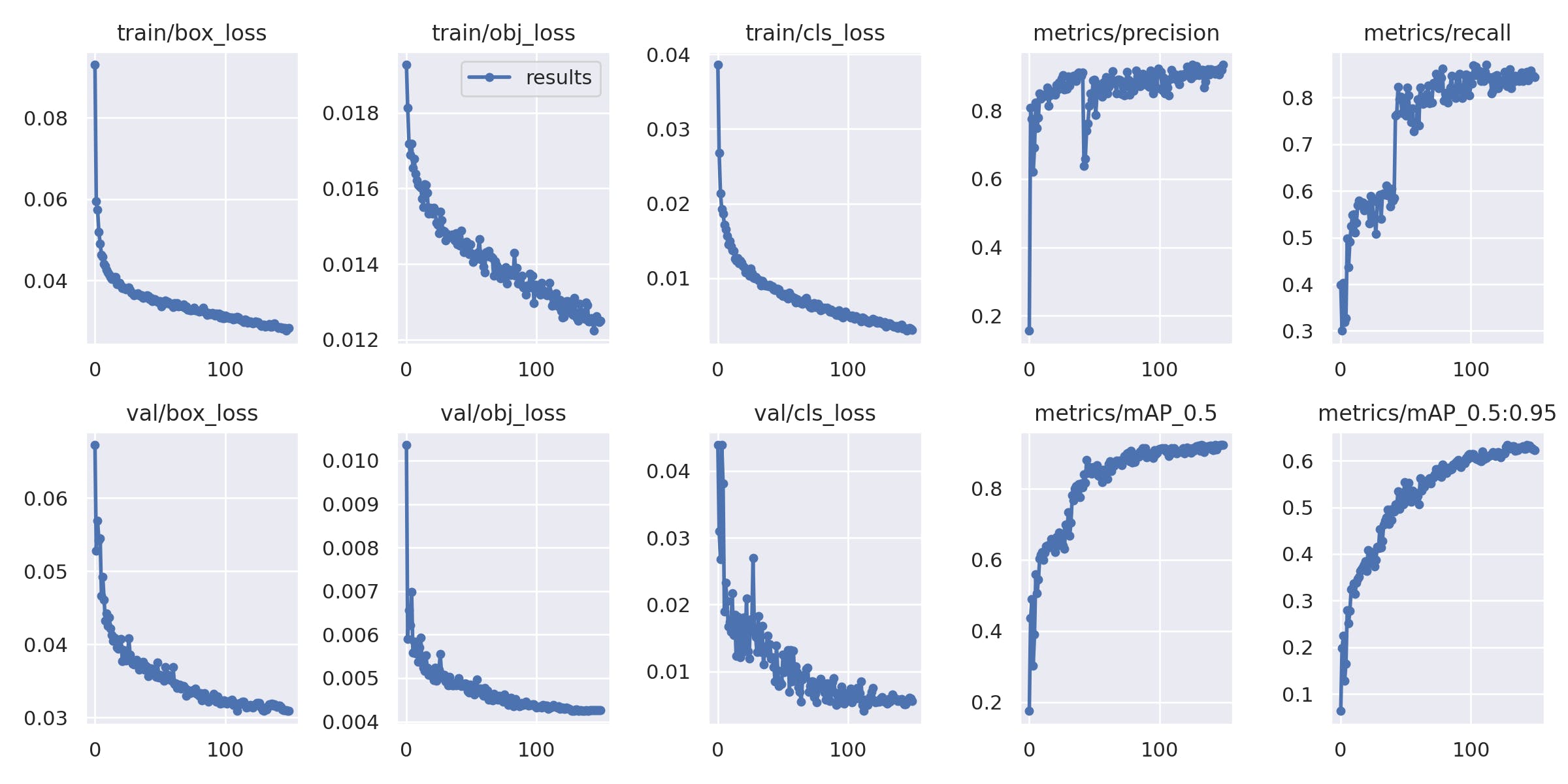
上面的结果是从官方yolov5n6模型中得到的epochs=150.结果很好。因为,
主要指标:precision、recall 和 mAP_0, 5 均大于 0.9。在 ML 中,mAP_0.5 在 0.6 和 0.9 之间的差异在现实世界的检测中是巨大而巨大的。
不幸的是,基于官方训练的最终模型yolov5n6接近4MB,而Grove AI模块的约束模型大小不超过1MB。因此,我们不能使用任何此类更大的模型(已尝试)。一些建议将在最后一节中讨论。 推论

经过以上训练,我们进行图片仿真,初步评估模型的效果。让我们看例子。
以上是 Grove AI 模块的输出。分类指数在中间,置信度在旁边。对应指标的动物名称可以在上面的训练图中看到。
第一次和第二次检测是正确的,第三次检测是错误的。第三张图是一只喜鹊在天上飞,推理结果是蝴蝶。我们只是在后面的real-wprld评估中看到这个分类模型的影响。
真实世界评估
现实世界中的推理比实验室中的推理更具挑战性。因为测试时所处的环境或测试者或被测对象的状态都会对结果产生很大的影响。这就是我们在工作流程部分进行规划的原因。
我们通过TinyWild 项目中的郊野公园野生动物调查进行了真实世界的评估。执行两种类型的检测:
- 基于动态视口(移动相机)的检测
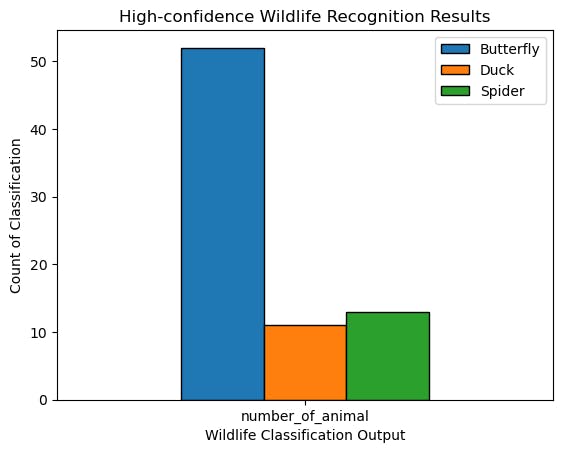
上图是整个调查的分类统计(置信度>75)。相机移动的时间很长。因此,这是一个基于动态视口(移动相机)的检测。源于软件逻辑的“未知”和空动物已被排除在外。
基本结论是,对于个体识别来说,不是特别理想,但是收集到的定性信息是有效的。
Bufferfly在统计上相对突出,但没有在公园里见过很多次的Magpie。
这似乎是喜鹊被识别为缓冲蝇,如上面推理部分的分析所示。它们的共同点是,它们经常在空中飞行。三个真实世界的因素:移动的相机、移动的物体和低分辨率,对识别结果有很大的影响。
- 基于静态视口(静态相机)的检测
为减少移动因素的影响,还在湖边开展了野鸭(野鸭)专项观测。
在上面的第一个捕获中,我们前端 UI 中鸭子的数量(其中一个有趣的地方是 UI 中的动态表是由 SQL 查询驱动的,请参阅我们未来项目中的更多信息)。突然,两个鸭子游入镜头范围。鸭子的数量已经增加到13。考虑到原来的鸭子是被数过的,13是当时精确的数。发现Grove AI 对附近的动物检测非常有效,就像我们在湖边所做的那样:当三只鸭子突然以相对静态定位游入相机范围时,我们得到了三个计数。(注:在TinyWild项目中,我们说有四项计数,但根据我们的录音应该更正为三项计数。)
建议
基于以上实践,我们针对廉价边缘人工智能硬件上的 EdgeML 或 TinyML给出以下建议:
- 尝试静态观察
即观察者不做大动作。
- 检测尽可能少的物体
例如,只做二元分类:人或没有人,猴子或没有猴子,鸟或没有鸟。
- 使模型的主要指标尽可能大
例如,precision > 0.8,recall 和 mAP_0.5 > 0.6。
- 尽可能提高识别准确率(比如,更长的训练时间)
廉价的边缘 ML 硬件通常资源有限,例如 Grove AI 模块的约束模型大小不超过 1MB,低于 yolov5 官方 yolov5n 预训练网络训练的模型大小。发现较小的模型会显着影响模型的主要指标。

声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。 举报投诉
- 相关下载
- 相关文章





