
资料下载


×
DSP芯片功能扩展解析
消耗积分:1 |
格式:rar |
大小:0.4 MB |
2017-10-31
分享资料个
数字信号处理器(DSP)做某些模拟工作比模拟电路要出色,因此得以生存。在某些情况下,由于成本或复杂性的原因,任务甚至不能考虑用模拟电路,DSP仍然是一种可行的选择,在很多情况下可以轻松地完成那些任务。
这是因为DSP进行算术运算既好又快,如加法和乘法。聪明的数学家和工程师利用了这一实际,通过创造算法来解决主要采用两种数?运算的复杂的信号处理任务。
如今的DSP芯片不仅仅只是一个优秀的处理引擎。芯片上还集成了存储子系统、高速接口、I/O等等。增加这些部件的目的是为了提高整体性能,降低功耗以及针对特殊的处理任务。
为了更好地理解各种DSP芯片的可用选项以及器件各部分是如何配合作为一个整体,分析当今市场上几种有代表性的DSP是有帮助的。我们将仔细研究单核、单核加微控制器以及多核DSP芯片的例子。
单核DSP芯片
认为DSP芯片有一个单DSP核是很自然的,例如,TI的TMS320C6?52(图1)。此芯片是高性能固点DSP的TMS320C6?x+家族的一员,针对工艺密集的多通道电信基础设施和医用成像系统。DSP核只不过是芯片设计的一部分,芯片的其余部分还包括存储器、I/O以及其他功能模块。
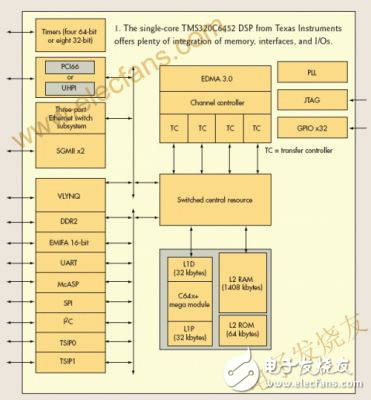
C6?52 DSP集成了组织为两级存储子系统的片上存储器。一级(L1)程序和数据存储器每个都是32k字节。此存储器可配置为映射RAM、高速缓存,或者两者的某种组合。
当配置为高速缓存时,L1程序(L1P)是一个直接映射高速缓存,而L1数据(L1D)是一个双向指令集结合高速缓存。二级(L2)存储在程序与数据空间之间共享。L2存储也能配置为映射RAM、高速缓存或者两者的某种组合。设计师可使用片上存储器为其项目增加特色。
C6?52还包括两个串行吉比特媒体独立接口(SGMII)以太媒体接入控制(MAC)口和一个吉比特开关。此开关通过自动监控数据流以确保只有一个合适的TI将决策门加到所能的开关上,例如,用来辨别语音和数据通信,以提高多芯片设计的效率。如果DSP全部用于语音处理,就会阻止数据流进入,这样可更有效地使用其处理带宽。此外,器件具有两个电信串行接口端(TSIP),可无缝连接至常见电信串行数据流。
C6?52上的其他I/O有一个66MHz PCI接口或通用主机端接口(UHPI);一个到外部存储器的双数据率(DDR2)接口;TI开发的专利串行通信接口VLYNQ;一个16位外部存储器接口(EMIFA);一个多通道通用音频串行口(McASP);以及其他熟悉的接口。从此DSP的I/O判断,可以肯定它是用于电信应用。其他应用用的是不同的I/O。
C6?52和TI其他几款DSP的核心是C6?x mega模块,其组成包括几个元件:C6?x+处理器、L1程序和数据存储控制器、L2存储控制器、内部DMA(IDMA)、中断控制器、掉电控制器以及外部存储控制器(图2)。Mega模块还支持对L1P、L1D和L2存储器的存储保护。此外还提供mega模块资源的带宽管理。
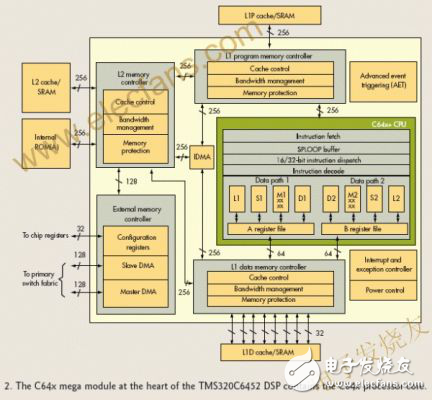
模块上的C6?x+处理器是一非常快速的DSP,工作速率可达1.2GHz。它采用8个功能模块、两个寄存器文件以及两个数据路径。在这八个功能单元中,有两个是乘法器或者M单元。每个M单元在每个时钟周期执行四次16位×16位乘法-累加(MAC)。
因此,在C6?x+核上,每个周期可执行8次16位×16位MAC。在1.2GHz时钟速率下,每秒钟可发生9600次16位MMAC。此外,C6?x+核的每个乘法器每个时钟周期可计算一次32位×32位MAC或者四次8位×8位MAC。顺便提一下,C6?52不是以900M的最快的速度工作。
C6?x+处理器的新特征有一个令人钟爱的名字SPLOOP。这一小型指令缓冲器有助于创建软件流水线操作环路,在这些环路中并行执行环路的多次迭代。SPLOOP缓冲器减小了有关软件流水线操作的代码大小。
DSP+微控制器芯片
另一类DSP在芯片上附加微控制器核。有时,为一个分离的核,如ARM处理器。有的情况下,处理器核同时包含DSP和MCU功能。这种情况就是众所周知的模拟器件公司(ADI)的Blackfin DSP架构。
Blackfin是基于具有混合16/32型指令集架构的10级RISC MCU/DSP流水线,包括双16位MAC DSP指令和一个32位类似于RISC的指令集。这种组合提供信号处理功能,具有与通用处理器有关的使用方便的特点。Blackfin处理器架构完全兼容SIMD(单指令多数据)并包括视频与图像处理加速指令。
这种处理属性组合使Blackfin处理器与其同类产品不同。他们被设计为在信号处理和控制处理应用方面工作都非常好,在很多情况下,设计中无需独立的异类处理器。Blackfin处理器在单核产品中速率高达756MHz。
除本地支持8位数据外,8位数据字长是很多像素处理算法常用的,Blackfin架构包括专门定义的指令,用于在视频处理应用中增强性能。例如,“SUM ABSOLUTE DIFFERENCE”指令支持用于视频压缩算法(如MPEG2、MPEG4和JPEG)的运动估算算法。
这种架构处理多长度指令编码。非常常用的控制型指令被编码为紧凑的16位字,更多算术密集的信号处理指令编码为32位值。处理器将16位控制指令与32位信号处理指令混合并连接成6?位组,以使存储器容量最大化。缓冲和取指令时,内核完全自动挑选总线长度,因为内核没有调整约束。
所有Blackfin处理器,如ADSP-BF523,都包含独立的DMA控制器,支持自动数据传输,而对处理器内核的操作压力很小(图3)。DMA传输可发生在内部存储器与许多具备可直接存储器存取(DMA)功能外设的任何部分之间。传输也能发生在外设和接至外部存储器接口的外部器件之间,包括SDRAM控制器和异步存储控制器。
存储器架构包括L1和L2存储器块。L1存储器直接连接到处理器内核,以全系统时钟速度运行,为时间关键的算法部分提供最佳系统性能。此外,L1存储器也可配置为SRAM、高速缓冲存储器或者两者的组合。
通过同时支持SRAM和高速缓冲存储器编程模型,系统设计师可分配关键的要求高带宽和到SRAM低存取的实时信号处理数据集合,同时在高速缓存中存储“软”实时控制和操作系统(OS)任务。L2存储器是一更大的大容量存储器存贮区,性能稍有降低,但仍快于片外存储器。
这是因为DSP进行算术运算既好又快,如加法和乘法。聪明的数学家和工程师利用了这一实际,通过创造算法来解决主要采用两种数?运算的复杂的信号处理任务。
如今的DSP芯片不仅仅只是一个优秀的处理引擎。芯片上还集成了存储子系统、高速接口、I/O等等。增加这些部件的目的是为了提高整体性能,降低功耗以及针对特殊的处理任务。
为了更好地理解各种DSP芯片的可用选项以及器件各部分是如何配合作为一个整体,分析当今市场上几种有代表性的DSP是有帮助的。我们将仔细研究单核、单核加微控制器以及多核DSP芯片的例子。
单核DSP芯片
认为DSP芯片有一个单DSP核是很自然的,例如,TI的TMS320C6?52(图1)。此芯片是高性能固点DSP的TMS320C6?x+家族的一员,针对工艺密集的多通道电信基础设施和医用成像系统。DSP核只不过是芯片设计的一部分,芯片的其余部分还包括存储器、I/O以及其他功能模块。
C6?52 DSP集成了组织为两级存储子系统的片上存储器。一级(L1)程序和数据存储器每个都是32k字节。此存储器可配置为映射RAM、高速缓存,或者两者的某种组合。
当配置为高速缓存时,L1程序(L1P)是一个直接映射高速缓存,而L1数据(L1D)是一个双向指令集结合高速缓存。二级(L2)存储在程序与数据空间之间共享。L2存储也能配置为映射RAM、高速缓存或者两者的某种组合。设计师可使用片上存储器为其项目增加特色。
C6?52还包括两个串行吉比特媒体独立接口(SGMII)以太媒体接入控制(MAC)口和一个吉比特开关。此开关通过自动监控数据流以确保只有一个合适的TI将决策门加到所能的开关上,例如,用来辨别语音和数据通信,以提高多芯片设计的效率。如果DSP全部用于语音处理,就会阻止数据流进入,这样可更有效地使用其处理带宽。此外,器件具有两个电信串行接口端(TSIP),可无缝连接至常见电信串行数据流。
C6?52上的其他I/O有一个66MHz PCI接口或通用主机端接口(UHPI);一个到外部存储器的双数据率(DDR2)接口;TI开发的专利串行通信接口VLYNQ;一个16位外部存储器接口(EMIFA);一个多通道通用音频串行口(McASP);以及其他熟悉的接口。从此DSP的I/O判断,可以肯定它是用于电信应用。其他应用用的是不同的I/O。
C6?52和TI其他几款DSP的核心是C6?x mega模块,其组成包括几个元件:C6?x+处理器、L1程序和数据存储控制器、L2存储控制器、内部DMA(IDMA)、中断控制器、掉电控制器以及外部存储控制器(图2)。Mega模块还支持对L1P、L1D和L2存储器的存储保护。此外还提供mega模块资源的带宽管理。
模块上的C6?x+处理器是一非常快速的DSP,工作速率可达1.2GHz。它采用8个功能模块、两个寄存器文件以及两个数据路径。在这八个功能单元中,有两个是乘法器或者M单元。每个M单元在每个时钟周期执行四次16位×16位乘法-累加(MAC)。
因此,在C6?x+核上,每个周期可执行8次16位×16位MAC。在1.2GHz时钟速率下,每秒钟可发生9600次16位MMAC。此外,C6?x+核的每个乘法器每个时钟周期可计算一次32位×32位MAC或者四次8位×8位MAC。顺便提一下,C6?52不是以900M的最快的速度工作。
C6?x+处理器的新特征有一个令人钟爱的名字SPLOOP。这一小型指令缓冲器有助于创建软件流水线操作环路,在这些环路中并行执行环路的多次迭代。SPLOOP缓冲器减小了有关软件流水线操作的代码大小。
DSP+微控制器芯片
另一类DSP在芯片上附加微控制器核。有时,为一个分离的核,如ARM处理器。有的情况下,处理器核同时包含DSP和MCU功能。这种情况就是众所周知的模拟器件公司(ADI)的Blackfin DSP架构。
Blackfin是基于具有混合16/32型指令集架构的10级RISC MCU/DSP流水线,包括双16位MAC DSP指令和一个32位类似于RISC的指令集。这种组合提供信号处理功能,具有与通用处理器有关的使用方便的特点。Blackfin处理器架构完全兼容SIMD(单指令多数据)并包括视频与图像处理加速指令。
这种处理属性组合使Blackfin处理器与其同类产品不同。他们被设计为在信号处理和控制处理应用方面工作都非常好,在很多情况下,设计中无需独立的异类处理器。Blackfin处理器在单核产品中速率高达756MHz。
除本地支持8位数据外,8位数据字长是很多像素处理算法常用的,Blackfin架构包括专门定义的指令,用于在视频处理应用中增强性能。例如,“SUM ABSOLUTE DIFFERENCE”指令支持用于视频压缩算法(如MPEG2、MPEG4和JPEG)的运动估算算法。
这种架构处理多长度指令编码。非常常用的控制型指令被编码为紧凑的16位字,更多算术密集的信号处理指令编码为32位值。处理器将16位控制指令与32位信号处理指令混合并连接成6?位组,以使存储器容量最大化。缓冲和取指令时,内核完全自动挑选总线长度,因为内核没有调整约束。
所有Blackfin处理器,如ADSP-BF523,都包含独立的DMA控制器,支持自动数据传输,而对处理器内核的操作压力很小(图3)。DMA传输可发生在内部存储器与许多具备可直接存储器存取(DMA)功能外设的任何部分之间。传输也能发生在外设和接至外部存储器接口的外部器件之间,包括SDRAM控制器和异步存储控制器。
存储器架构包括L1和L2存储器块。L1存储器直接连接到处理器内核,以全系统时钟速度运行,为时间关键的算法部分提供最佳系统性能。此外,L1存储器也可配置为SRAM、高速缓冲存储器或者两者的组合。
通过同时支持SRAM和高速缓冲存储器编程模型,系统设计师可分配关键的要求高带宽和到SRAM低存取的实时信号处理数据集合,同时在高速缓存中存储“软”实时控制和操作系统(OS)任务。L2存储器是一更大的大容量存储器存贮区,性能稍有降低,但仍快于片外存储器。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。 举报投诉
评论(0)
发评论
- 相关下载
- 相关文章





