
资料下载


×
基于表示学习方法的中文分词系统
消耗积分:1 |
格式:rar |
大小:0.74 MB |
2017-12-11
分享资料个
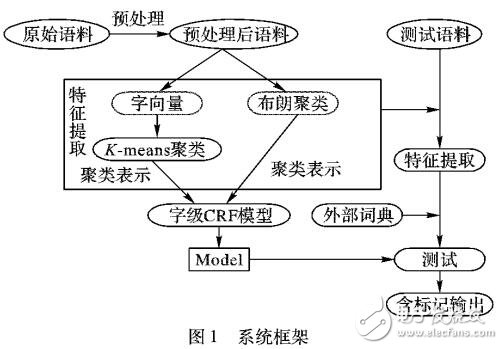
为提高中文分词的准确率和未登录词( OOV)识别率,提出了一种基于字表示学习方法的中文分词系统。首先使用Skip-gram模型将文本中的词映射为高维向量空间中的向量;其次用K-means聚类算法将词向量聚类,并将聚类结果作为条件随机场(CRF)模型的特征进行训练;最后基于该语言模型进行分词和未登录词识别。对词向量的维数、聚类数及不同聚类算法对分词的影响进行了分析。基于第四届自然语言处理与中文计算会议( NLPCC2015)提供的微博评测语料进行测试,实验结果表明,在未利用外部知识的条件下,分词的F值和OOV识别率分别达到95. 67%和94. 78%,证明了将字的聚类特征加入到条件随机场模型中能有效提高中文短文本的分词性能。

声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。 举报投诉
评论(0)
发评论
- 相关下载
- 相关文章





