
资料下载


基于MapReduce的并行关联规则挖掘算法
分享资料个
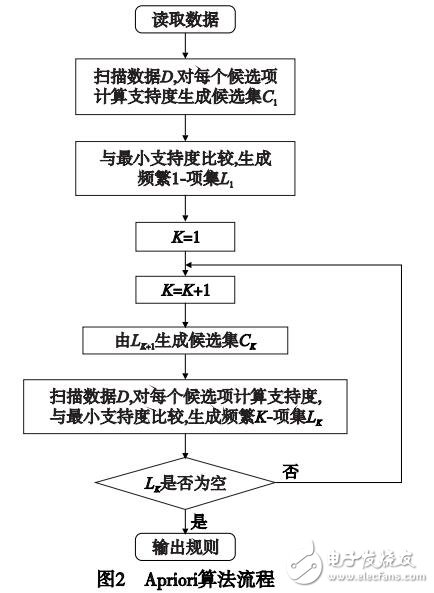
数据挖掘( data mining)又称做知识发现(knowledge disco-ver in database,KDD),其目的在于发现大量数据集中有价值的隐含信息。常见的数据挖掘任务有关联规则挖掘、分类、聚集、离群点检测等。关联规则挖掘是最重要的数据挖掘任务之一,由Agrawal等人提出,其目的是发现事务(项)之间存在的隐含关联。关联规则挖掘一般分为两个阶段,即发现频繁项集和根据频繁项集产生关联规则。由于根据频繁项集产生关联规则相对容易实现,所以关联规则挖掘研究主要关注的是如何在数据集中找到频繁出现的项集,这个过程也称为频繁项集挖掘( frequent itemsets mining)或频繁模式挖掘(frequent patterns mining)。传统的关联规则挖掘算法主要可以分为三类:a)产生测试方法,通过迭代产生候选频繁项集并进行分别计数,统计得到频繁项集,典型的算法是Agrawal等人心1提出的算法及其一系列的改进算法,如DHP、DIC等;b)模式增长方法,它不用产生候选项集,而是将所有频繁项压缩成一种特殊的数据结构(一般为树结构),通过在数据结构上进行遍历直接产生频蘩项集,典型的算法有FP-Growth、LP-tree、FIUT、IFP、FPUTPLElol等;c)垂直格式方法,是将水平格式的数据集转换成垂直格式,通过交运算来得到频繁项集,典型的算法有Eclat等。
随着信息技术的快速发展,需要存储和分析的数据量呈爆炸性增长,人类已经进入了大数据时代,传统的关联规则挖掘算法已经不能适应大数据挖掘的要求,主要困难是:单一计算机无法存储所需要挖掘的所有数据及挖掘过程中产生的中间结果;挖掘过程所需要的内存远远超过单一机器的存储量;计算时间太长无法忍受等。需要开发分布式、并行关联规则挖掘算法解决上述问题。
MapReduce是一种由Google于2004年提出的一种易用且功能强大的并行编程模型,具有使用简单、自动容错、负载均衡、伸缩性好等优点,其开源实现Hadoop已经广泛应用于很多大数据分析领域,已经有了很多将传统关联规则挖掘算法向MapReduce模型进行迁移的研究,很大程度上解决了大数据关联规则挖掘的问题。这些算法的主要思想都是利用Ha-doop中的分布式文件系统(HDFS)来解决海量数据存储和分片的问题,利用MapReduce未实现挖掘算法的并行执行。

声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。 举报投诉
- 相关下载
- 相关文章


下载排行榜
- 暂无相关数据

