


Parca 是一个针对应用程序和基础设施的持续分析项目。持续分析以分析 CPU、内存使用情况,直至行号。节省基础设施成本、提高性能并提高可靠性。
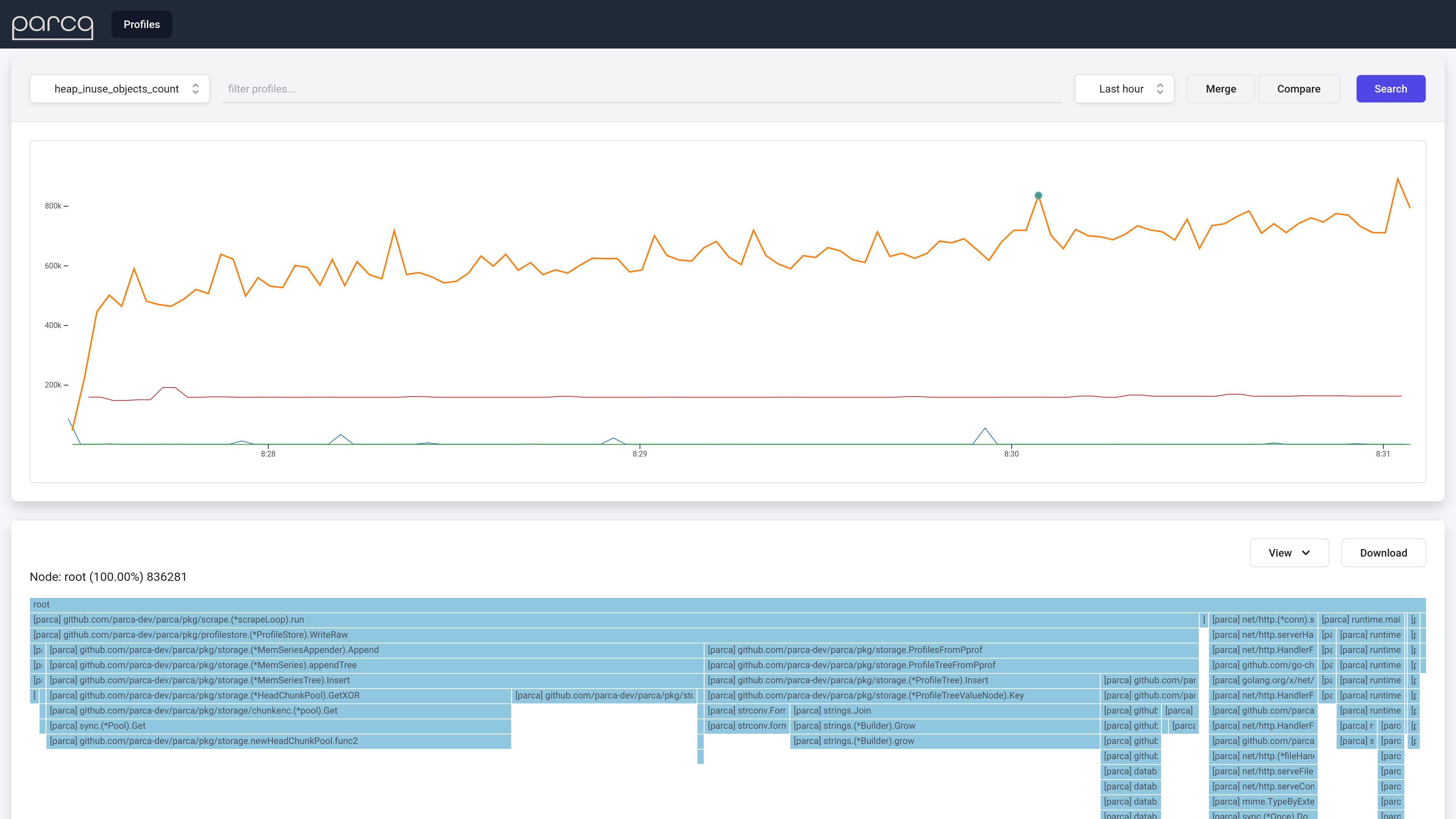
持续分析是以系统的方式对程序进行剖析(如CPU、内存、I/O等)的行为。Parca 收集、存储并提供可在一段时间内查询的配置文件。它有一个强大的多维数据模型、存储和查询引擎,专门为剖析数据设计。
特性:
-
eBPF Profiler:单个 profiler,使用 eBPF,以非常低的开销自动从 Kubernetes 或 systemd 跨整个基础架构发现目标。支持 C、C++、Rust、Go 等。
-
Open Standards:使用基于 eBPF 的 profiler 生成 pprof 格式的配置文件,并摄取任何 pprof 格式的配置文件,允许广泛的语言采用和与现有工具的互操作性。
-
优化的存储和查询:有效地存储分析数据,同时保留原始数据,并允许通过基于标签的搜索对数据进行切片和切块。聚合分析数据基础架构范围内的数据,及时查看单个配置文件或在任何维度上进行比较。
优势
- 省钱:许多组织通过轻松优化的代码路径浪费了 20-30% 的资源。Parca 代理旨在通过要求整个基础设施的 0 检测来降低进入门槛。
- 提高性能:使用随时间收集的分析数据,Parca 可以自信地和具有统计意义的确定要优化的热门路径。此外,它还可以显示任何标签维度之间的差异,例如部署、版本和区域。
- 了解事件:分析数据可提供对流程随时间执行的内容的独特见解和深度。内存泄漏,以及导致意外行为的 CPU 或 I/O 中的瞬时峰值,传统上难以排除故障,而通过连续分析则轻而易举。





