
资料下载


使用微型嵌入式设备实现嵌入式语音识别应用程序
分享资料个
描述
我们的目标:
我们使用微型嵌入式设备实现了嵌入式语音识别应用程序,该设备可以将一秒钟的语音作为输入并对语音进行分类。不同种类的声音由不同颜色的 LED 灯表示。该项目可用于许多现实世界的应用程序,例如 Google Assistant、Apple 的 Siri 和 Amazon Alexa 等。
机器学习模型:
为了处理原始音频数据,嵌入式设备的功能提供程序将原始音频数据转换为频谱图,频谱图是由频率信息切片组成的二维数组。二维张量的特征可以通过卷积神经网络 (CNN) 完美提取。
CNN 模型在称为语音命令数据集的数据集上进行了预训练。这包括 65,000 条 30 个短词的一秒长话语,在线众包。
我们的方法:
1.输入数据收集
该组件从麦克风捕获原始音频数据。为了验证设备在不同情况下的功能,所有组成员的音频都被用作输入。
“是”和“否”特征的可视化。
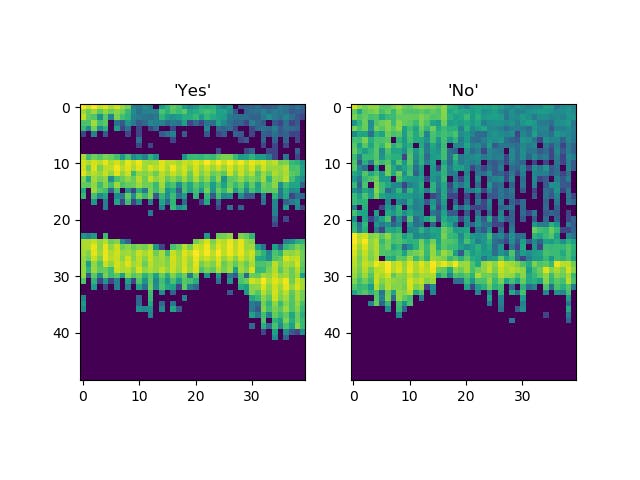
2.设置TF Lite解释器
在 Arduino IDE 中导入 micro_speech 库。生成 C++ 代码并自动设置 TensorFlow Lite 环境。在进行测试时,解释器运行 TensorFlow Lite 模型,将输入的频谱图转换为一组概率,并选择概率最高的一个作为输出。
Sketch uses 145184 bytes (14%) of program storage space. Maximum is 983040 bytes.
Global variables use 76952 bytes (29%) of dynamic memory, leaving 185192 bytes for local variables. Maximum is 262144 bytes.
Device : nRF52840-QIAA
Version : Arduino Bootloader (SAM-BA extended) 2.0 [Arduino:IKXYZ]
Address : 0x0
Pages : 256
Page Size : 4096 bytes
Total Size : 1024KB
Planes : 1
Lock Regions : 0
Locked : none
Security : false
Erase flash
Done in 0.000 seconds
3. 对开发板进行编程
将开发板连接到笔记本电脑并将代码上传到 Arduino 开发板。
Write 145192 bytes to flash (36 pages)
[ ] 0% (0/36 pages)
[= ] 5% (2/36 pages)
[== ] 8% (3/36 pages)
[=== ] 11% (4/36 pages)
...
[=========================== ] 91% (33/36 pages)
[============================ ] 94% (34/36 pages)
[============================= ] 97% (35/36 pages)
[==============================] 100% (36/36 pages)
Done in 5.652 seconds
4.测试功能
使用设备上的 LED 对不同的音频类型进行分类(绿色:是,红色:否,蓝色:未知)。如果听到命令,命令响应器会使用设备的输出功能让我们知道。然后我们用“是”和“否”测试几次,板上的灯显示它有效。由于该模型仍然有点幼稚,因此会重复多次测试以确保其运行良好。
“否”的测试用例:
'是'的测试用例:
“Don Don Don”的测试用例(预期用于“Unkown”):
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。 举报投诉
- 相关下载
- 相关文章






