
资料下载


使用Arduino Nano 33构建嵌入式语音识别应用程序
王桂英
分享资料个
描述
团队成员
钟志哲 (cc128)
程文白 (wc47)
黄伟豪(wh28)
目标
我们使用 Arduino Nano 33 构建了一个嵌入式语音识别应用程序,将一秒钟的语音作为输入并对其进行分类。
为了更容易运行脚本,笔记本的第一个单元格在环境变量中存储了一些重要的值。这些将在运行时替换到脚本的命令行标志中。
WANTED_WORDS 允许我们选择用于训练模型的单词。默认情况下,选择的词是“是”和“否”。我们的模型选择了“stop”和“go”。
TRAINING_STEPS 是指一批训练数据将通过网络运行的次数,以及更新其权重和偏差的次数。LEARNING_RATE 设置调整率。默认情况下,模型将以 0.001 的学习率训练 15, 000 步,然后以 0.0001 的学习率训练 3, 000 步。我们的模型以 0.001 的学习率训练了 12,000 步,然后以 0.0001 的学习率训练了 3,000 步。
安装正确的依赖项
安装包含训练所需操作的特定版本的 TensorFlow pip 包。
克隆相应版本的 TensorFlow GitHub 存储库,以便我们可以访问训练脚本。
使用 TensorBoard 监控训练
它是一个用户界面,可以向我们展示图表、统计数据和其他有关培训进展情况的见解。
例如,TensorBoard 显示了两个图表,“accuracy”和“cross_entropy”,如图 2 和图 3 所示。
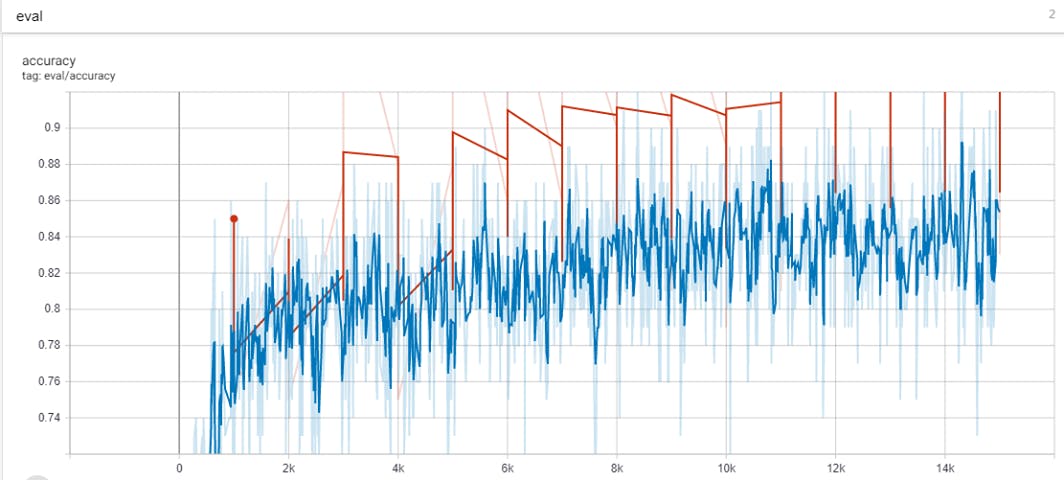
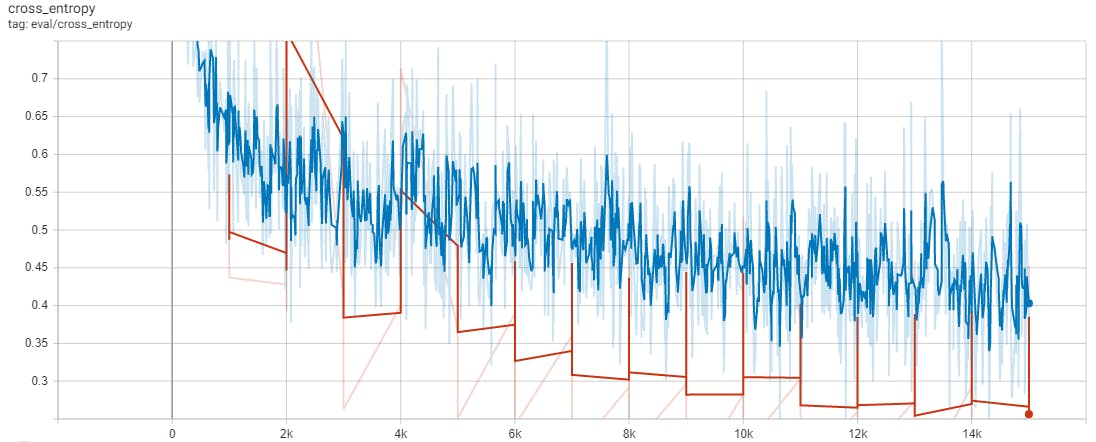
“准确度”图在其 y 轴上显示模型的准确度,这表明它能够正确检测到一个单词的时间。“cross_entropy”图显示了模型的损失,它量化了模型预测与正确值的差距。
将训练输出转换为我们可以使用的模型
首先,将冻结的图形文件转换为完整的 TensorFlow Lite 模型。
其次,将 TensorFlow Lite 模型转换为 C 数组。
在我们的项目中使用我们新训练的模型
更换模型
替换数组的内容和 micro_features_model.cpp 文件中常量 g_tiny_conv_micro_features_model_data_len 的值。
更新标签
将“是”和“否”换成“去”和“停止”。在 arduino_command_responder.cpp 文件中。
更新 arduino/command_responder.cpp
用“g”和“s”交换“y”和“n”。
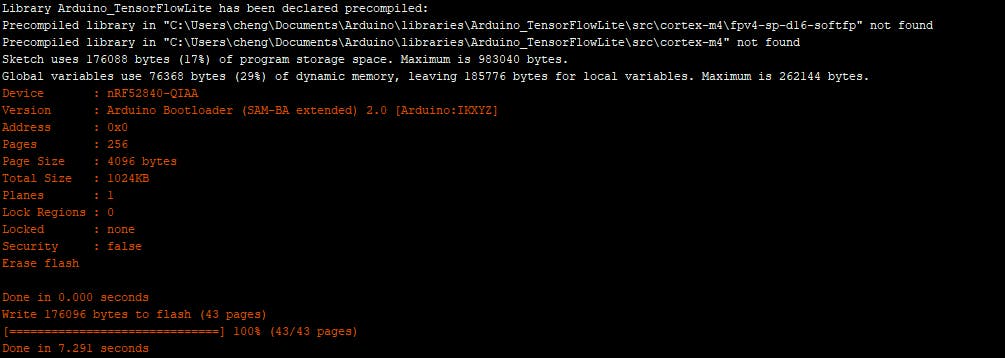
编译并上传板子
测试功能

声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。 举报投诉
- 相关下载
- 相关文章






