

UVM设计模式:OOP特性、设计原则、规范与单元测试
电子说
描述
懂得“数据结构与算法” 写出高效的代码,懂得“设计模式”写出高质量的代码。
何为高质量的代码?
下面这些词汇是我们常用的形容好代码的词汇:
灵活性(flexibility)、可扩展性(extensibility)、可维护性(maintainability)、可读性(readability)、可理解性(understandability)、易修改性(changeability)、可复用(reusability)、可测试性(testability)、模块化(modularity)、高内聚低耦合(high cohesion loose coupling)、高效(high effciency)、高性能(high performance)、安全性(security)、兼容性(compatibility)、易用性(usability)、整洁(clean)、清晰(clarity)、简单(simple)、直接(straightforward)、少即是多(less code is more)、文档详尽(well-documented)、分层清晰(well-layered)、正确性(correctness、bug free)、健壮性(robustness)、鲁棒性(robustness)、可用性(reliability)、可伸缩性(scalability)、稳定性(stability)、优雅(elegant)、好(good)
如何写出高质量代码?
-
面向对象编程因为其具有丰富的特性(封装、抽象、继承、多态),可以实现很多复杂的设计思路,是很多设计原则、设计模式等编码实现的基础。
-
设计原则是指导我们代码设计的一些经验总结,对于某些场景下,是否应该应用某种设计模式,具有指导意义。
-
设计模式是针对软件开发中经常遇到的一些设计问题,总结出来的一套解决方案或者设计思路。应用设计模式的主要目的是提高代码的可扩展性。
-
编程规范主要解决的是代码的可读性问题。
-
重构作为保持代码质量不下降的有效手段。
面向对象
含义
面向对象编程的英文缩写是 OOP,全称是 Object Oriented Programming。对应地,面向对象编程语言的英文缩写是 OOPL,全称是 Object Oriented Programming Language。
面向对象编程中有两个非常重要、非常基础的概念,那就是类(class)和对象(object)。这两个概念最早出现在 1960 年,在 Simula 这种编程语言中第一次使用。而面向对象编程这个概念第一次被使用是在 Smalltalk 这种编程语言中。Smalltalk 被认为是第一个真正意义上的面向对象编程语言。
Systemverilog作为面向对象的语言,相比C++, 更"像“ Java. Java语言并不直接运行在真实机器上,而是有一个虚拟机(即Java Virtual Machine ,JVM)来承载其运行,JVM使用C++编写的,而C++是C的超集。
UML
UML(Unified Model Language),统一建模语言。用画图表达面向对象或设计模式的设计思路。对于UML的使用,纯软件人员之间仍存在一些争议。
示例:
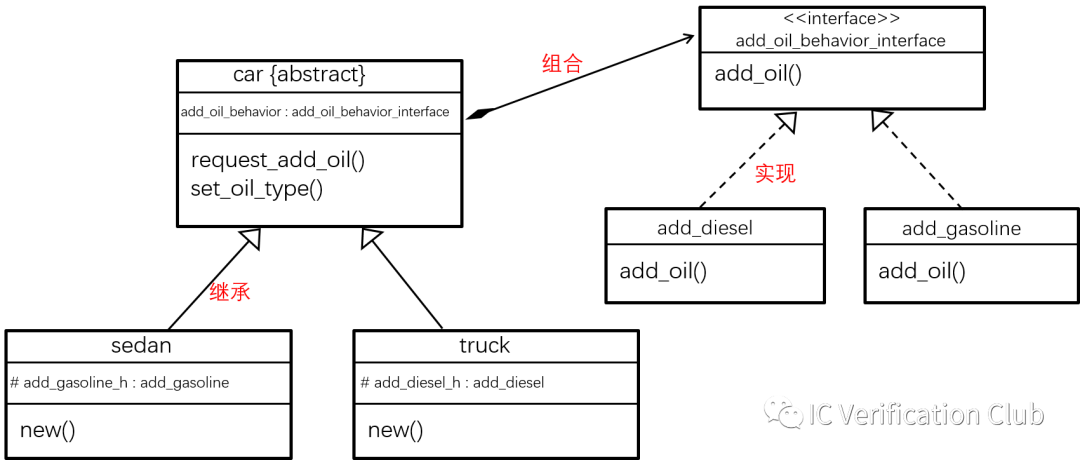
封装(Encapsulation)
将属性和方法封装到到类中,但类中的属性并不需要全部暴露出去,可以通过加上访问权限控制这一语法机制,限制对类属性的访问,修改。
Java中的权限修饰符:
private 修饰的函数或者成员变量,只能在类内部使用。
protected 修饰的函数或者成员变量,可以在类及其子类内使用。
public 修饰的函数或者成员变量,可以被任意访问。
SV中的访问权限控制qualifiers限定符:
local:表示的成员或方法只对该类的对象可见,子类以及类外不可见。
protected:表示的成员或方法对该类以及子类可见,对类外不可见。
除此之外,我们还常见const, static修饰变量。
const:分为两种:全局性、instance性的 (const 在run-time阶段,而 localparam需要在elaboration-time
被赋值)
全局性const:在声明时即赋值,之后不可修改;
instace性const:只使用const进行声明,赋值发生在new()中
const修饰的变量,不允许被修改,否则编译器报错。
为什么const修饰的变量不可以被修改呢?其实无论SV,C++还是C语言,各种语言的语法不同,但是最终都是通过编译器编译后,程序运行在系统内存里,如果const修饰的变量被编译器分配到了一个.rodata只读的内存段,那么就可以很好的解释为什么不可以被修改了。同理,static对应静态分配的地址(存储在全局数据区),该段地址相对automatic属性的地址段,不会被释放内存,自然可以在整个仿真过程一直存在。
为了地址对齐,SV仿真器会把byte放在32bit的地址空间。
对于task/function调用,则对应栈空间,如果使用的是input,output类型的参数,开始调用时“input” 变量 copy到栈中,结束调用时“ouput” 变量再pop出栈。所以在task/function中修改变量,修改的结果对其他调用函数不可见。如果使用SV中的ref,一方面对于数据量较大的数组,不用copy到栈空间,可以获得更佳的性能,同时修改变量的结果对外可见。
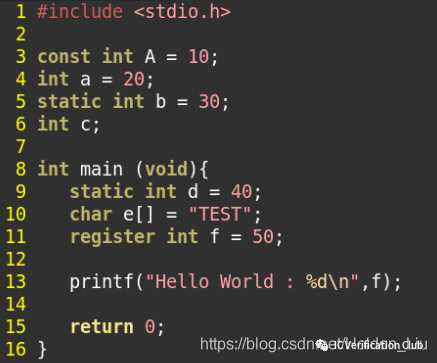
对于上述诸多的变量修饰符,从编译存储的角度分析,可以加深理解。C语言相对其他语言OOP语言,更接近硬件,可以通过objdump –dS a.out 反汇编查看各个变量的
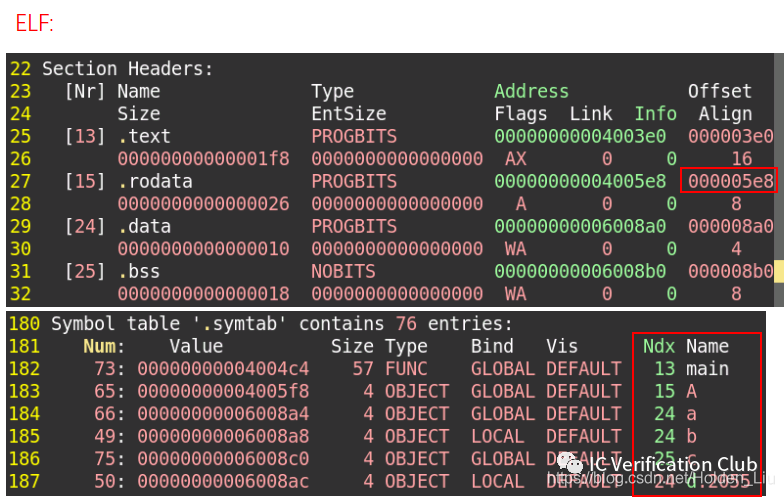
main 函数位于.text段,GLOBAL修饰属于External Linkage
‘A’ 位于 .rodata段
‘Hello World” 也位于.rodata段 hexdump –C a.out可以查看。
程序加载运行时, .rodata段和.text段通常合并到一个Segment中,操作系统将这个Segment的页面只读保护起来,防止意外的改写。
.data段中有 ‘a’, ‘b’, ‘d’ , 其中a是GLOBAL全局变量,b被static修饰,为LOCAL,不会被链接器处理。d被static修饰,并位于main函数中,静态分配。
.bss段紧挨着.data段,被0填充,不占内存。所以c位于.bss段,未赋值初始化为0. .data 和.bss在加载时合并到一个Segment中,这个Segment是可读可写的。
‘e’ 位于函数内部,放在栈上存储, 省略auto修饰
‘f’ 寄存器声明,保存在CPU寄存器上
参考:Linux C编程一站式学习 宋劲杉 19.3 变量的存储布局
抽象(Abstraction)
OOP中抽象这一特性本身就很“抽象”,如果单单从语法上看,SV在《IEEE Standard for SystemVerilog 1800-2012》才加入了像Java语言那样支持抽象(面向接口编程)的语法。关键词是 interface class, implements。
当一个class implements 一个 interface class时,必须override interface class 中的纯虚(pure virtual)方法,这也很符合 implements这个单词本身的含义。
下面看一个列子(from IEEE Standard for SystemVerilog 1800-2012 8.26):

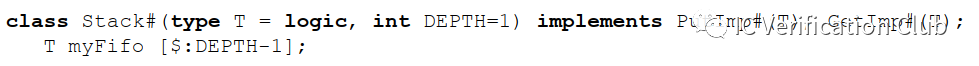

两个interface class,PutImp, GetImp 分别包含纯虚方法put, get的原型。class Fifo 和 class Stack 使用关键词 implementes来实现这两个interface class中的纯虚方法。
class Fifo and class Stack share common behaviors without sharing a common implementation.
classs Fifo 和 class Stack 都有 put, get的操作,但是实现的具体方式不同(FIFO:先进后出,Stack:先进先出)。这就体现了“抽象”的含义,interface仅仅暴露出的是common behavirs,调用人员不需要关心具体的实现。
实际上,如果上升一个思考层面的话,抽象及其前面讲到的封装都是人类处理复杂性的有效手段。在面对复杂系统的时候,人脑能承受的信息复杂程度是有限的,所以我们必须忽略掉一些非关键性的实现细节。而抽象作为一种只关注功能点不关注实现的设计思路,正好帮我们的大脑过滤掉许多非必要的信息。
可能因为intreface class这一语法加入SV较晚,并且EDA工具支持有一定延迟, 在UVM源码中,并没有使用 interface class这一语法。但抽象仅仅是一个非常通用的设计思想, 比如一个上报错误的function, 命名为report_error()就比命名为report_size_mismatch_error()抽象,具体的错误类型,不必体现在函数命名上。( 2016 DVCon US : SystemVerilog Interface Classes - More Useful Than You Thought 涉及 interface classes 在实际项目中的使用)
在SV没有加入接口类(intreface class)之前,也有抽象类(virtual class)可以代替抽象的特性。
抽象类不能直接例化,一个由抽象类扩展而来的类只有在所有虚方法都有实体的时候才能被例化。抽象类中可以定义非纯虚方法,但是接口类不行。
接口类的一些特性,抽象类并不具备。比如一个类可以实现多个接口类,并同时继承某一个类。比如下面这个用例。

extends 和 implements还是有本质区别的,extends继承,是 is-a的关系,而implements更像是has-a的关系。所以SV中加入interface class,使其更接近高级语言所具备的特性。
抽象类和接口类如何选择呢?抽象类是is-a的关系,解决代码复用问题,接口类是has-a的关系,更侧重于解耦,隔离接口和具体的实现,提高代码的扩展性。
基于接口而非实现编程(Program to an interface, not an implementation),将接口(interface)和实现(implements)相分离,封装不稳定的实现,暴露稳定的接口。
上游系统面向接口而非实现编程,不依赖不稳定的实现细节,这样当实现发生变化的时候,上游系统的代码基本上不需要做改动,以此来降低耦合性,提高扩展性。
UVM验证平台,已规定好了hierarchy结构和各component功能,验证工程师只需根据实际业务“填充”具体内容,属于硬件验证,而纯软件要实现多交互的复杂业务侧重设计,所以一般工作中没有需求用到抽象类和接口类。对于没有使用UVM方法学,自己写Systemverilog搭建的验证平台, 接口类,抽象类,纯虚方法可以建立具有统一观感的测试平台,这就使任何一个工程师都可以读懂你的代码并且快速理解其结构。
继承(Inheritance)
继承是用来表示类之间的 is-a 关系,比如狗是一种哺乳动物。可以通过extends 关键字来实现继承(可以通过继承+参数化的类来实现多继承的效果,有点非常规操作,参考SystemVerilog: Reusable Class Features and Safe Initialization of Static Variables。另外interface class也可以实现多继承),C++和Python既支持单重继承,也支持多重继承。
在构造用例时,一般会创建一个base_class作为父类,子类extends继承父类的特性,使用super关键字指示编译器来显式的引用父类中定义的数据成员和方法。
SV语法规定父类的new()函数(构造函数),子类必须显示调用,写出super.new()。如果父类new()函数有参数,子类也需要传入参数。不管子类是否重载new()函数,都要显式调用父类的构造函数。
在实际验证工作中,一般不会出现下述问题,基本继承2次就足以覆盖大部分需求了,但是纯软件编程可能会因为业务复杂,导致继承过度,采用 “多用组合少用继承” 是一个规避办法。
继承的概念很好理解,也很容易使用。不过,过度使用继承,继承层次过深过复杂,就会导致代码可读性、可维护性变差。为了了解一个类的功能,我们不仅需要查看这个类的代码,还需要按照继承关系一层一层地往上查看“父类、父类的父类……”的代码。还有,子类和父类高度耦合,修改父类的代码,会直接影响到子类。
在SV使用中,我们也会遇到合成和继承的选择问题,合成使用了“有”(has-a)的关系,继承使用了“是”(is-a)的关系。
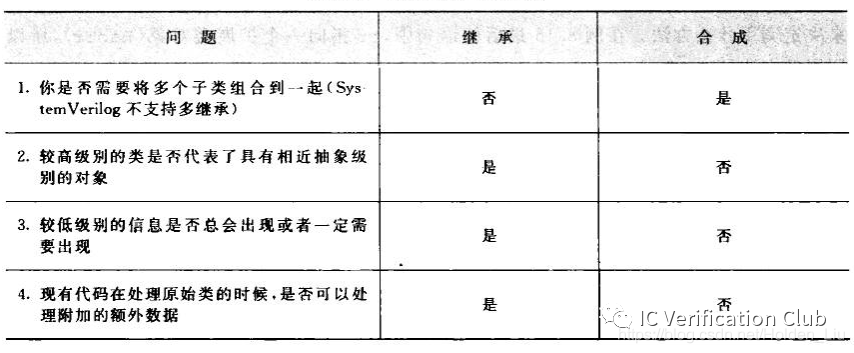
SV构建测试平台并非标准的软件开发项目,除了继承与合成之外,根据现实的场景使用,把所用变量集成在一个类中,通过条件约束达到目的。Constraint-driven 的策略更有利于我们的验证工作。
如下示例:(Systemverilog验证 测试平台编写指南 8.4)

多态(Polymorphism)
多态是指,子类可以替换父类,父类句柄可以指向子类的实例。(子类句柄不可以指向父类的实例,因为子类调用的方法,父类实例中或许并不存在)
多态的例子这里就不再列举了,建议学习《The UVM Primer》,这是一本很好学习OOP的书籍,足以应对工作中的绝大部分内容。
当父类句柄指向子类的实例时,通过父类句柄调用方法,如果方法使用virtual修饰,则会动态的调用子类的方法(虽然是父类句柄,但是实例是子类,实际调用子类override(重写or覆盖)的方法)。如果方法没有使用virtual修饰,则是静态的根据句柄调用方法(动态:实例 静态:句柄)。
父类的task/function已经用virtual修饰,子类没有必要在加上virtual了。
所以多态的实现要依赖虚函数virtual,总结就是“继承加方法重写 ”。
SV语法目前还不支持overload(重载),override指的是重写,也可以理解成覆盖,一般不做详细区分。
对于多态的底层实现及virtual, function override,$cast()转化的底层原理,需要深入研究编程语言的编译原理。检索并没有介绍Systemverilog的相关文章,可以通过学习C++或者Jave扩充学习,检索内存模型或者对象模型获取相关知识。
除了上述“继承加方法重写”实现多态的方法,Systemverilog也可以采用之前介绍的 interface class实现多态。还有一种是利用 duck-typing 语法,SV并不支持,动态语言Python才支持。
实例如下:
class Logger:
def record(self):
print(“I write a log into file.”)
class DB:
def record(self):
print(“I insert data into db. ”)
def test(recorder):
recorder.record()
def demo():
logger = Logger()
db = DB()
test(logger)
test(db)
设计模式之美 从这段代码中,我们发现,duck-typing 实现多态的方式非常灵活。Logger 和 DB 两个类没有任何关系,既不是继承关系,也不是接口和实现的关系,但是只要它们都有定义了 record() 方法,就可以被传递到 test() 方法中,在实际运行的时候,执行对应的 record() 方法。
设计原则
纯软件设计中的设计原则,对于IC的验证和设计工作也有指导意义,我们日常工作中的一些“习惯”,可能就是在践行某一个设计原则。依次列举如下:
单一职责原则
一个类只负责一个功能,避免设计大而全的类,避免不相关的功能耦合,提高内聚性。也可以延申到验证的测试用例,每个用例应该对应一个场景或者功能。
开闭原则
对扩展开放,对修改关闭。对于新加的功能,应在已有代码基础上扩展,而非修改已有代码。所以在最初代码编写时,就应该充分考虑可扩展性,当然也不是完全杜绝修改,要把握“粗细粒度”。对于已经充分验证的rtl模块,侧重在原来基础上新加功能,而不是“大修”原来的模块,容易引入bug, 相应的测试用例也可以做到最小修改。
里式替换原则
子类对象可以替换程序中出现的父类对象,并保证原来程序的逻辑行为的正确性。这一原则跟多态比较像,侧重于继承关系中子类该如何设计。
接口隔离原则
接口的调用者不应该强迫依赖ta不需要的接口。如果B模块内包含B-1,B-2两个模块,A模块的正常工作依赖于B-1模块的初始配置,C模块的正常工作依赖于B-2模块的初始配置。B模块的验证人员可以将B模块的初始配置流程写到一个函数中,这个函数供A,C模块的验证人员调用,这个函数就像API接口一样,调用者只负责调用,不用关心具体实现。如果B模块的函数同时包含B-1,B-2的初始配置,A模块的验证人员调用,虽然不会影响功能验证,但是B-2模块与A模块并无联系,恰当的做法应该是将B-1,B-2模块的初始配置隔离开来,供使用者按需调用。
依赖倒置原则
程序要依赖于抽象接口,不要依赖于具体实现。简单的说就是要求对抽象进行编程,不要对实现进行编程,这样就降低了客户与实现模块间的耦合。高层次的模块不应该依赖于低层次的模块,他们都应该依赖于抽象。和依赖接口编程的含义相近。
KISS、YANGI ,DRY原则
KISS: Keep It Stupid Simple 不要使用同事不懂的技术;不要重复造轮子,使用现有的方法;不要过度优化;
YANGI: You Ain't Gonna Need It 不要过度设计
DRT: Don't repeat yourself 减少重复的代码。对于重复的代码,思考是否可以通过封装到函数中,通过传参的方式实现。
迪米特法则
Talk only to your immediate friends and not to strangers,只与你的直接朋友交谈,不跟“陌生人”说话。
如果两个模块实体无须直接通信,那么就不应当发生直接的相互调用,可以通过第三方转发该调用。其目的是降低类之间的耦合度,提高模块的相对独立性。“高内聚,松耦合”
规范与重构
代码风格与规范:Easier UVM Coding Guidelines
代码测试:SV单元测试方法SVUnit SVUnit Download SVUnit blog
SVUnit采用了一种特别的方式来生成task。一般task负责时序相关的驱动和采样,开发者根据设计文档中的时序图编写task代码,但是代码的准确性有待验证。SVUnit从另一个思路出发,直接通过时序图,来生成对应task。这样便保证了task中时序的准确性,毕竟时序图要是都错了,那只能通过review发现了。
SVUnit将时序图转化成task的方法,是通过编写wavdrom可识别的json格式(有固定格式,但是很容易上手,支持网页,linux, window平台。UserGuide). 然后调用SVUnit中的脚本wavedromSVUnit.py解析json文件,生成时序图对应的代码。SVUnit对json文件做了额外描述,可以参照 test/wavedrom_0/1下面的json文件深入理解。
示例:
json描述:
{
"name": "read",
"signal": [
{"name": "clk", "wave": "p|...|." , "node": ".ab...d"},
{"name": "psel", "wave": "0.1...0" },
{"name": "penable", "wave": "0..1..0" },
{"name": "paddr", "wave": "x.=...x" , "data": ["addr"] },
{"name": "pready", "wave": "0....10" , "input": "True", "node": "......c"},
{"name": "prdata", "wave": "x....=x" , "output": "True", "data": ["data"] }
],
"input": [
{"name": "addr", "type": "logic [7:0]"}
],
"output": [
{"name": "data", "type": "logic [31:0]"}
],
"edge": ["a~>b 8,12", "c->d pready==1"],
config: { hscale: 3 }
}
waverom生成的时序图:

自动生成的task:
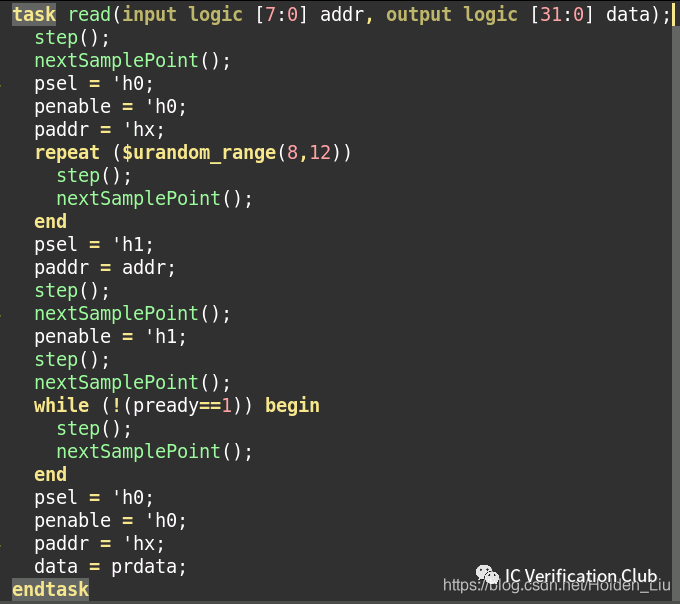
这种方式的限制就是仅适用于直接测试用例。
绝大部分验证人员开发UVC,都是一遍debug DUT, 一遍调试验证平台,并不会专门使用SVUnit对UVC进行验证。但是对于sv库的开发,使用SVUnit是一个很好的选择。
不过仍建议在monitor, driver开发初期,同时RTL还没有ready的情况下,使用SVUnit将波形转化成直接的时序激励,做一些直接用例的测试,及早发现问题。如果设计文档中的波形也是使用wavedrom绘制的,那么对于验证人员的工作又省了一步,可以直接拿设计人员波形的json文件生成用例。
重构:随着项目的推进,迭代,原来的代码也会慢慢变“差”,重构可能是一条"挽回“路径。在项目初期,尽可能地划分好验证平台的组件,目录,文件调用,宏定义,脚本等,重构的同时也在引入不确定性。
审核编辑 :李倩
-
边聊安全 | 软件单元测试的设计方法2025-09-05 10973
-
软件单元测试真的有必要吗?(上)2023-11-03 1938
-
电源与时钟的单元测试方案解析2023-03-03 1752
-
2022 RT-Thread全球技术大会:什么是单元测试2022-05-27 1561
-
如何对Web组件进行单元测试2021-12-20 1560
-
MCU如何进行单元测试2021-10-26 1310
-
什么是单元测试,为什么要做单元测试2021-04-28 11178
-
嵌入式需要单元测试吗?2020-10-23 3223
-
为单元测试“正名”2019-12-08 4025
-
单元测试常用的方法2017-12-21 42768
-
labview单元测试2012-10-10 3772
-
系统测试、单元测试、集成测试、验收测试、回归测试2008-10-22 2188
全部0条评论

快来发表一下你的评论吧 !
