

简述SystemVerilog的各种随机化方法
电子说
描述
我习惯将验证空间理解为:验证中原则上需要覆盖的芯片所有有可能出现的工作状态的集合。为了探索这片广袤的验证空间,验证的时候搞出了带有约束的随机测试(constrainted-random testing),并搞了覆盖率(coverage)作为评估机制。这也是一套成熟可信的工程学方法。
因为约束和随机化可以讲的干货太多,于是我做了拆分。本文要介绍的内容就仅涉及SV的随机化处理,包括伪随机数的产生、随机稳定性和编程示例。
伪随机数的产生
SystemVerilog提供了很多生成伪随机数的方法,比如产生随机数的内建函数**random, **urandom, $urandom_range,对象随机方法object.randomize(),标准库随机函数std::randomize()等等。这些函数的用法在很多教程中都会提到,而本文要做的,是要挖一挖这些函数的“玄机”。

1. Probabilistic Distribution System Functions
第一类随机函数是概率分布系统函数(probabilistic distribution system funtions),这类函数在LRM中明确包括**random, **dist_uniform, **dist_normal, **dist_exponential, $dist_poisson等可以产生满足不同概率分布的随机数的函数,并且在附录N中用C代码给出了这些函数的实现算法。这就意味着,使用相同的种子,这些函数在不同的仿真软件中产生出来的随机数序列应该是一致的。这也是这类函数跟其他类函数的主要区别。
2. Object and Scope Randomization Method
再来看对象随机方法object.randomize(),这个函数在LRM中被称为“the object and scope randomization method”。顾名思义,它专门被用来随机化对象。它是所有SV类中都会默认存在的内置虚函数(原型是virtual function int randomize()),但是它不能被覆盖(overridden)。当你使用object.randomize() 来对对象进行随机化的时候,注意它只会随机化类中有rand关键词修饰的成员变量,并且在成功随机化之后会返回1,失败则返回0。除此之外,每个类中还有randomize的两个回调函数pre_randomize()和post_randomize(),这两个函数分别会在执行randomize()的前后自动被调用。注意,这两个函数并不是虚函数(其函数原型没有virtual关键字),但他们是由虚函数randomize()来自动调用的,因此也表现为虚函数的多态行为。
这套使用类来描述和控制随机数据及其约束的机制相当强大。之所以这么说,一方面是因为有了类的继承特性的加持,随机变量可以方便地继承和扩展;另一方面是因为SV还提供了约束的覆盖、扩展、使能和禁用等功能。但这里有一个问题,就是object.randomize()还是只能随机化类的成员变量,不能随机化局部变量。为了解决这个问题,SV又搞来了一个可用于当前范围内,且不限于对象成员的随机化函数std::randomize(),它在LRM中的定性是scope randomize function。
Std lib下的std::randomize()的适用性比object.randomize()要好,不过它不能自动随机对象中的rand成员变量,也没有pre和post函数可以调用,毕竟鱼和熊掌不可兼得呀。std::randomize()在某些场景下前面的“std::”是可以省略的,但还是建议使用的时候加上比较好,能与上面讲的object.randomize()做出区分。除了可以随机化当前范围内变量,std::randomize()使用的时候可以将需要随机化的多个变量同时放到参数列表中一起做随机,且能适配这些变量的位宽。该函数返回结果跟object.randomize()一样,成功返回1,失败返回0。
3. Random Number System Function
最后要将讲的是SV中比较古老的随机函数和方法urandom()和urandom_range()。后者只是在前者的基础上增加了范围限制。**urandom的函数原型是function int unsigned **urandom [(int seed)]。可以看出来,这两个函数的返回值都是32bit的无符号数。如果初始随机种子一样,则相同工具的每一次仿真跑出来的随机数是一致的,这是涉及到下小节要讲的一个重要的特性:随机稳定性。
随机稳定性(Random stability)
在SV中,不同线程(thread)或对象(object)在随机化时使用的随机数产生器(RNG)是相互独立的。另一方面,相同线程或相同对象在相同随机种子的情况下,每一次仿真中产生的随机数序列是一样的。这个属性就叫random stability。
随机稳定性之所以重要,是因为在芯片验证中,随机验证方法是很重要的一部分,在用例回归之后,那些Failed的测试用例通常需要使用触发错误的随机种子来重现,比如把波形Dump出来。因此,有必要了解线程和对象的随机化机制。下面从三个层面看这套机制是怎么运作的。
**Initialization RNG:**初始化RNG是产生随机数的开始,用来给RNG初始化随机种子。每一个模块实例(module instance)、接口实例(interface instance)、程序块(program)和包(package)实例都有属于自己的初始化RNG,在不指定随机种子的情况下,默认的随机种子根据不同编译器的实现决定的。上小节讲的每一种伪随机数的产生方法都有自己指定随机种子的函数
**Hierarchy seeding:**分层分配随机种子是随机稳定性的重要机制。在创建新的线程或者实例化对象的时候,父线程使用的RNG的下一个随机值会作为这个新线程或者新对象的RNG的随机状态,即作为新的种子传递下去。
**Thread and Object Stability:**SV中将程序(program)、模块(module)、接口(interface)、函数(function)、任务(task)等这些独立的块叫Process。每个Process都有自己的RNG。每个RNG都有自己的随机状态(random state)。我们可以通过process::self()这个静态方法获取当前Process的RNG句柄,在通过句柄调用get_randstate()方法来获得随机状态。不同的仿真工具返回来的随机状态的值的表现方式可能会不一样,但基本都是一段看起来没有规律的字符串,这个字符串表示下一个要产生的随机数的值。
SV的这套随机稳定性机制,尽管通常不需要我们去做什么,但是要知道:在我们要复现一个执行失败的测试用例的时候,不要改动之前布下的种子,也不要改变程序中线程和对象创建的顺序,避免更改了分层随机种子的顺序。
编程示例
下面的例程和仿真结果展示了以上介绍到的随机函数和特性,代码中也附有必要的注释。如果需要源码,可以在公众号中直接回复"SV随机"获得下载链接。
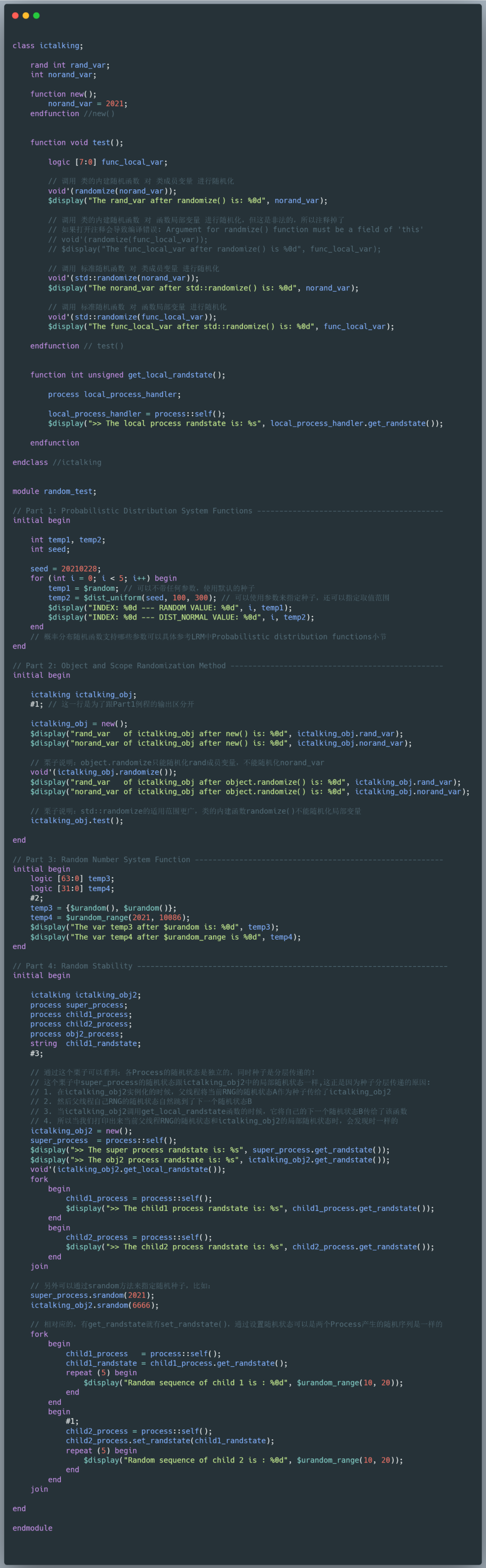
仿真结果如下图所示:

参考文献
[1] IEEE Standard Association. "IEEE Standard for SystemVerilog-Unified Hardware Design, Specification, and Verification Language." (2013).
-
求教!!LabVIEW怎样数据的随机化2012-02-18 3277
-
高速ADC的数字输出随机化器2020-11-11 2320
-
新的随机化广播加密方案2009-03-24 443
-
SystemVerilog中的随机化激励2009-12-14 1036
-
System Verilog中的随机化激励2012-04-01 726
-
基于System Verilog中的随机化激励2017-10-31 1100
-
一种随机化的软件模型生成方法2017-12-30 976
-
华为手机已经开启了MAC地址随机化功能可以有效的防范WiFi探针2019-03-18 14540
-
华为手机EMUI 8.0及以上版本已经默认开启了MAC地址随机化功能2019-03-20 9194
-
固态硬盘的顺序读写和随机读写有何区别2019-09-28 23999
-
简述SystemVerilog的随机约束方法2023-01-21 3826
-
SystemVerilog的随机约束方法2023-09-24 4206
-
SV约束随机化总结2023-12-14 2207
-
随机化在PCIe IDE验证中的重要性2025-03-06 1573
-
蓝牙随机化RPA更新的重要性和工作原理2025-07-10 1422
全部0条评论

快来发表一下你的评论吧 !
