

一种智能网卡的形式验证流程
描述
介绍
这篇论文总体上不难理解,背景是开发智能网卡的团队在验证智能网卡IP过程中,由于需要考虑数量庞大的错误场景,而不得不在原本已经启动的随机约束仿真验证(CBRV)基础上,添加了形式验证(FPV),继而在更短的时间里,找到了数量更多且更复杂的bug(好吧,形式验证听起来总是那么酷,屠龙术就是这么傲娇)。
论文容易理解的一个特征在于它会把这篇论文的背景和相关知识交代得易于理解。就比如它在描述有哪些错误类型的时候,将系统错误逐一划分,继而一直到它接下来要处理的功能描述错误即specification violation errors,这类错误也属于可检测到的错误类型,并且需要由设计报告出来,并且在报告以后设计还能够恢复正常。即在验证这个智能网卡IP的过程中,不但需要关注功能正确,而且还需要特别关注它可能遇到的(几乎所有)错误情况,并且设计要能够将这些错误情况检测(detect)、报告(report)出来,最后从错误状态中恢复(restore)到一个可知状态,在人为较少介入的情况下,还能够继续处理后续的数据包。
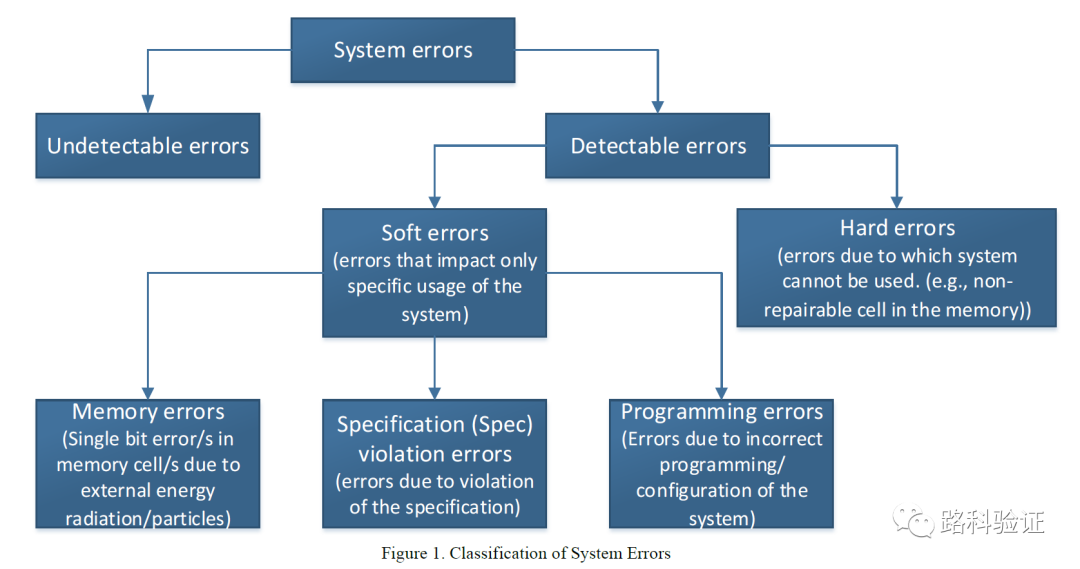
正由于本文智能网卡需要长期、频繁处理大量数据,它就有很多种出错的可能,而对于错误的处理就成了这个设计功能的一部分。这一点往往在很多其它设计中也有错误处理,但没有本文IP的要求高。但在CBRV中,由于UVM环境中的组件在设计时往往并没有充分考虑如何插入错误,这也使得让充分测试发生错误场景的要求变得困难,而且还可能带来较大的工作量。
提出问题
文中要验证的是NIC(Network Interface Card) IP中的一个解压缩IP,它的特点一如其它数据流处理的模块,也是需要对数据帧、数据块做数据接收、校验、格式检测等内容,并就违反数据协议的有关问题进行识别和报告。如果是要验证它的正常功能,那么就需要给它提供符合协议的经过压缩的数据。
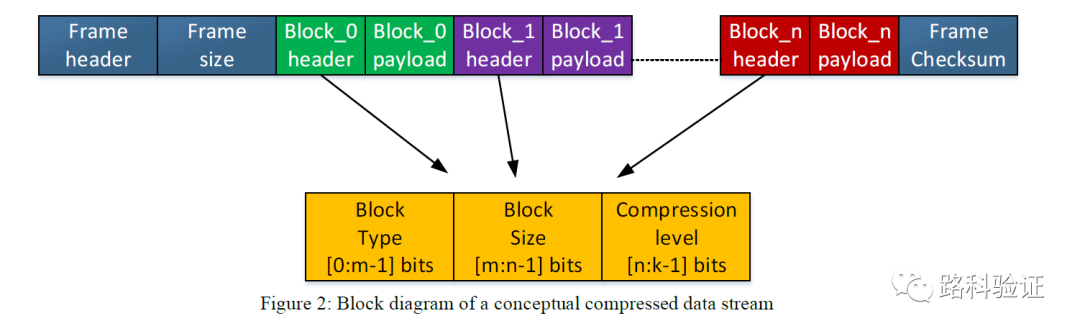
为了加速验证过程,在CBRV环境中他们采用的是软件压缩生成器(SW compressors),可以简单理解为通过已有的(来自外部或者内部的)软件压缩应用来对原始数据进行处理,并生成压缩后的数据文本,再将这些符合协议的数据通过协议激励的形式发送给解压缩IP,解压缩IP如果处理妥当的话,那么最终识别解包的数据可以通过monitor采集下来,并且与原始数据(在交给软件压缩生成器之前的数据)做比较。这种方式比较流程是从文中给的描述方式推断得出的。
只不过也正如文中谈到的,这种方式适合验证满足压缩数据协议的情况,但无法更好地解决一些验证完备性的问题,它们包括:
使用的软件压缩生成器并不足够灵活,只能生成协议中的一部分数据协议格式。
如果企图去修改这些生成器似乎不那么容易做反向工程,因为有些协议中要求的部分被优化掉了(也就失去了插入一些错误逻辑的可能)。
软件压缩生成器与压缩协议是一致的,但本身(一般)不支持插入错误,更谈不上错误的格式配置(因为这往往只有在硬件验证的时候才需要,而软件压缩生成器只是为了做数据协议的通路验证)。

基于此,可能需要在CBRV进行到一半的时候,再考虑是否需要就协议数据包的生成专门去做一个数据包生成器(例如由UVM来实现),但这也会在带来额外的工作量,而且还需要考虑协议中的各种组合情况(CBRV本身不会去做穷举组合,但目前有工具可以帮助做穷举组合覆盖率的收敛)。同时,也需要在实现协议driver的过程中就考虑在其中插入多个错误回调函数(从我们过去的实现经验来看这么做更加合理),以便于在sequence中通过绑定错误回调函数和错误类型来最终实现错误数据协议的插入。
但问题依然在,如果我们像AHB、I2C这些数据总线的错误协议,我们可以根据VIP的错误类型来选择插入不同的错误(这些错误类型往往是根据对协议的理解由VIP(Verification IP)提供商考虑来实现的,但数据总线协议标准并没有规定所有的协议错误的情形),而文中的解压缩IP已经对出现的各种错误可能都做了错误代码划分,也就是说它对功能错误的重视程度与功能正确的情况是一致的,我们需要验证的是,该IP在【所有规定错误类型】的情况下,都能检测(detect)、报告(report)错误并从错误中恢复(restore)正常。
这意味着即便我们花了大力气去实现CBRV需要的可以做不同数据格式配置的一个满足协议的driver,但还需要在driver内部准备多处错误插入逻辑。从我们过去的实现经验来看,我们实现正常的协议逻辑从基本功能到复杂功能是在做加法,而在继续实现插入错误的逻辑上面,我们可能是在做乘法。因为我们既要能够实现插入错误的功能,还要让这个功能不会影响到原有的正常驱动功能,而且还别忘记,我们还要考虑monitor是否需要对这些错误进行分类监测识别。可以这样说,这几乎给我们带来了至少双倍的工作量。
总而言之,这种为了遍历错误(也是一种功能测试要求)而去让CBRV的环境更加完善(且投入更多人力)的考量,给本文作者他们带来了一些新的选择。他们试图让FPV也参与到验证过程中来,继而降低整体的工作量(我没有见过他们的项目数据,就降低整体的工作量我持谨慎态度)和提高发现bug的效率。
解决方案
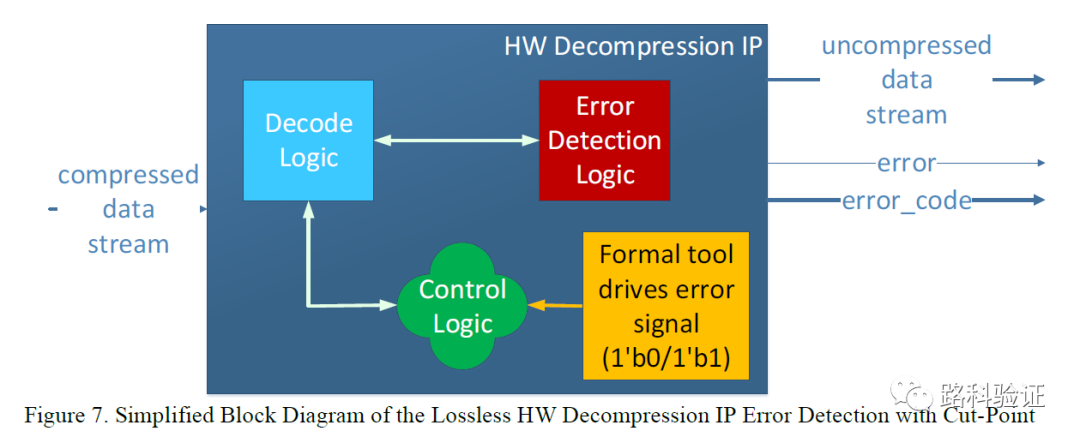
将这个解压缩IP做结构简化的话,可以分为解码逻辑(decode logic)、错误检测+报告逻辑(error detection logic)和控制逻辑(包含错误恢复,control logic)。在形式验证中,我们需要遵循一个基本原则就是简化设计,或者说是简化每一个断言属性要检查的逻辑。这就要求我们在一开始就需要考虑将设计进行拆分,就拆分的逻辑部分分别做形式验证,采取“分而治之”的方案,这个方案在数据流类型设计的形式验证中经常被采纳。
于是他们给的方案是对错误的检测、报告和恢复(控制)逻辑分别展开验证。只不过实际上文中并没有对形式验证的覆盖率给出数据,这也使得在最后与CBRV验证做比较的时候,是针对bug发现情况做的比较。因为形式验证的覆盖率部分也能帮助指出整个完整数据通路是否可以通过形式验证完成,即数据完整性(data integrity)的验证,否则在文章最后就CBRV与FPV的比较维度就不够完整,也无法让我们放心是否有信心在今后的工作有可能只采用FPV,而完全搁置CBRV。要注意的是,本文是就CBRV与FPV在验证流程和发现bug上的比较,但其实仍然隐去了一部分“工程现实”。而我谈到的工程现实,却可能决定了一个方案是不是能够更可靠地去“落地”。

在介绍接下来的3种分而治之的验证方案前,还需要清楚的是,实际的形式验证工程实现并没有下面简化后的这样“完美”,因为从本质而言,形式验证也对应着“激励”(stimulus)、“监测”(monitor)和“比较”(check),只不过它是由断言属性的assume来实现了激励、assert property的前置算子(sequence)实现了监测以及assert property的后置算子(sequence)实现了比较。
比如下面的错误检测验证和错误报告验证的两种形式验证子任务,就没有就它们是如何构建assume来做描述,以及如何在已满足协议的多个assume中,添加多种错误的assume,继而实现不同的错误可能这些工程实现进行描述。要知道协议往往越复杂,那么构建一组满足协议的assume,以及基于这些assume再添加引起错误的assume,都需要经验。只不过,相比于CBRV实现的driver中软件处理逻辑,FPV中的assume要更偏向于粒子化(atomic),也因此我们要插入一种错误,更容易与原有的assume组进行融合,无外乎是disable某些assume,再引入某些引起特定错误类型的assume。
最糟糕的情况可能是不对输入数据的协议做任何assume规范,但这对于前期稳定设计、调试设计都有显著的不利影响,这属于过于宽松的约束。往往是在设计稳定(测试过大多数正常功能)以后,我们才开始将约束逐步放宽,而我们这里说的约束宽松或者收窄,在CBRV或者FPV中都有这样的激励原则。 因此请在阅读本论文有关如何实现这三部分设计逻辑的形式验证时,理解论文作者为此做的抽象和简化,懂得“理想和生活往往只有一步之遥”的距离那么远又那么近... ...
错误检测验证
在这部分里,作者对解压缩IP需要处理的多种错误类型做了一个归类展示以说明他们需要就这些错误可能在FPV过程中都激励到。

就比如举的一个例子,要检测数据块的最大size,可以通过简化后的2个断言来实现“有且只有”的该错误类型的检查。但要注意的是,下面断言中使用的变量block_size从何而来,如果来自于设计内的信号,那么就还需要就该信号的逻辑做补充验证。这种规则也符合我们谈到的“分而治之”的理念,即如果你需要按照灰盒去降低形式验证的复杂度,那么你就需要对使用的设计变量做补充验证,证明它们的逻辑正确。
在下面的例子中,就需要证明block_size信号跟设计端口接收到的数据有关,且是经过数据包拆分后得到的逻辑。这部分逻辑往往可以在形式验证中也采用always/task这样的“胶水”逻辑做补充处理,继而证明block_size的逻辑正确。当然,下面的例子我们也可以直接采用经过胶水逻辑处理后的变量。两种方法,第一种是灰盒验证式的(采纳部分设计变量),第二种是黑盒验证式的(全部采用自有变量)。

错误报告验证
既然能够检测出错误,那么将错误正确无误地归类并且将8位的错误码发送出去,就属于错误报告的验证部分了。
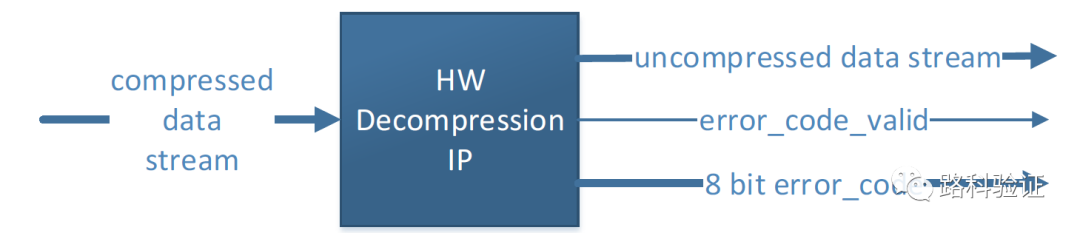
在下面简化后的代码中可以看到,只要错误能够检测出来(我们对这一步仍然做假设,可以利用设计中的变量,采取灰盒验证),就能够投入到错误报告的验证当中。在设计中,要归类这些错误类型,也往往会有可以直接使用的error flag变量,再结合输出端口的错误代码,即能够对这些错误报告做验证。

这部分代码显然可以复用,即当我们给入不同的error flag变量和对应的错误类型代码时,我们就可以同时验证256个错误类型。只不过形式验证不需要我们采用CBRV的方式去穷举这个256个test case,而只要我们的激励环境具备这个能力(assume group需要能够支持产生错误激励,且同时有条件出发不同的错误类型)。
在这种情况下,我们不必像CBRV为了每个test case去考虑支持插入的错误类型,要注意这些错误类型甚至都无法由某一个错误帧构成,可能是多个错误帧共同影响下的产物,FPV毫无疑问降低了为此我们要不断更新driver的压力。我们只需要让assume group能够自洽地去有条件产生一些我们想得到的和没有想到的激励,继而让它们去触发一些错误类型,并且去满足给定的错误类型断言。
可以预见到的是,错误类型断言未必都能够得到检查,即空成功(vacuous success),即这些没有被触发前置条件的错误断言类型由于我们给定的assume过约束(over constraint)而没有被触发检查。在这种情况下,我们往往需要多个任务场景,构建多种assume group,才能最终将这么多的错误类型都做到覆盖。
控制恢复逻辑验证
智能网卡对于能够从数量众多的错误中恢复正常数据处理的要求很高,这也使得在本文中的解压缩IP验证中,需要在错误检测和报告之后,仍然需要确保设计功能能够恢复正常。
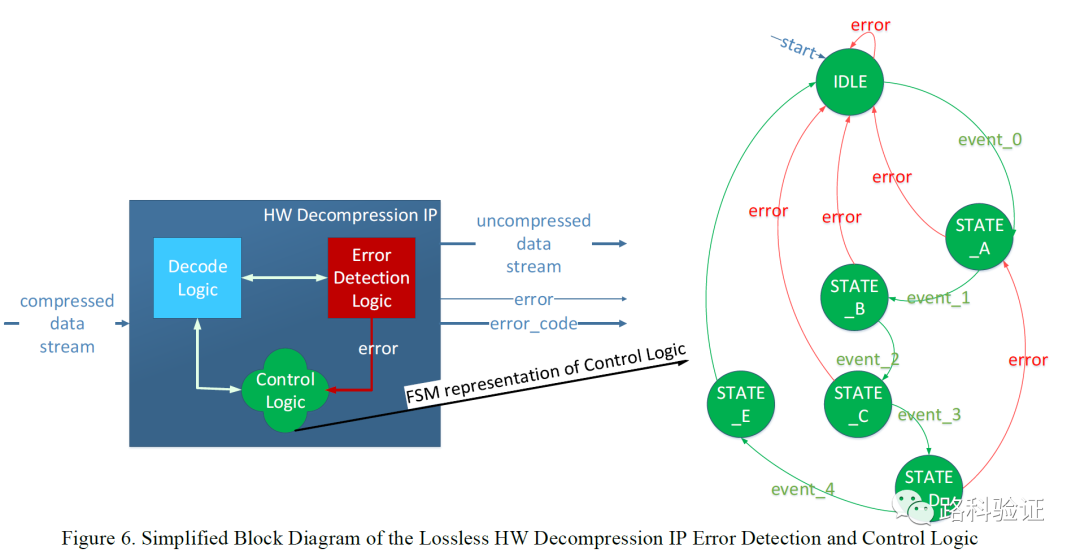
例如给出的这个简化后的状态机,既需要考虑是否所有的状态都已经遍历,而且也要在遍历之后检查设计功能是否正常。对于状态机的测试,在CBRV层面如果不受额外的人工介入,那么覆盖率将会在到达某个阶段后缓慢爬坡。而如果人工需要介入,那么就还需要考虑设计特定的测试场景去触发那些没有覆盖到的状态跳转情况。
往往状态机越复杂,用来分析状态机的难度就越大,用来单独设计为增加跳转覆盖率的测试用例就越难以把控。这里测试用例激励难以把控的原因是,这些激励需要通过若干不同的时序和逻辑处理后,才有机会去触发状态机的跳转,但这种跳转不是能够做到100%出现的。
那么当这些错误状态越多,解压缩IP的错误恢复控制逻辑测试对于CBRV的要求就越高,不但需要创建指定场景(有时这种场景都未必容易造出来),还需要在这些测试中关注每一种特定的状态跳转事件,继而触发某些信号用来收集覆盖率。

对于熟悉CBRV验证的朋友来说,如何去让状态机提高它的跳转覆盖率本身就不是SV/UVM能够直接起作用的,目前EDA公司也在推他们的有关“智能收敛”的方案,往往会跟他们的回归工具和仿真器做绑定,如果你们公司有精力做这样的尝试,可以试着联系EDA厂商的AE,试着在你们的环境中找个piolot项目先做做看,评估一下是否便于落地。
说回到FPV的验证方案,那就是考虑就这部分控制逻辑做单独验证,因为从激励的角度来看,你的激励距离目标越近,那么就更容易控制、触发目标设计中的逻辑,也就是去提高状态机的各种跳转覆盖率。如果就CBRV而言,这种方式不是一个常规方式,因为CBRV的环境里如果这部分control logic处于设计内部,那么设计内部的逻辑驱会驱动它,这种传导关系要求我们仍然从设计端口给激励。当然,我们也可以采用“侵入式”(invasive)激励,直接将激励数据灌入到内部设计的边界,只不过这种方式还需要改造UVM环境,毕竟它不是仿真环境原生支持的。
对于形式验证工具,它可以通过先切断(cut-point)设计中的驱动逻辑,再将目标变量的驱动交由assume property去做激励的形式,灵活地将激励从解压缩IP外部送入,同时将一部分激励直接给入到需要验证的control logic部分。在这种情况下,FPV可以更直接地去对control logic模块做激励,并且收集它的信号。这部分额外的assume/assert property可以通过单独的模块bind到这部分control logic模块。
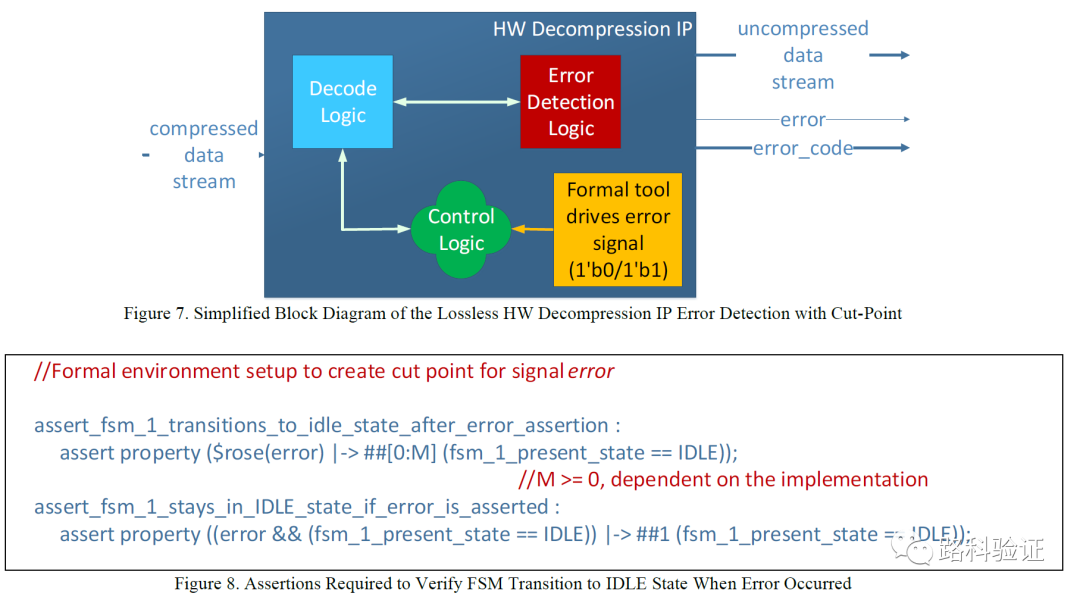
从上面简化的代码来看,就单独测试状态机而言形式验证的穷举模式会更有效,但也别忘记,我们仍然需要去证明所接管control logic的error signal功能(已由错误报告验证方案完成),以及它的输出控制信号最后对设计恢复正常功能的作用。
未提及的FPV部分
本文将三部分逻辑的功能和联系讲清楚了,尽管有较多的简化,但总体的功能逻辑是清晰的。只不过在接下来的总结部分,并未提及覆盖率的部分,无论是代码覆盖、断言覆盖率还是功能覆盖率。而且,还有重要的一点是,FPV的验证方案只做了“切分”和“简化”,但未提及对于整体数据通路的数据完整性验证。
要知道,如果没有这部分验证,那么我们肯定是对于FPV以后做独立完备性验证缺少信心的。但由于本文做了对比验证,那么CBRV部分的整体数据通路验证是完成的,也因此从项目上降低了对FPV的要求。也就是说,可以利用FPV的灵活性和穷举能力,让它更多地举出反例,帮助找到一些考虑不到的bug。往往是由于FPV的穷举能力,也就能够帮我们触发更多违例(violation)场景,挖掘到一些我们没有注意到的测试盲区并找到bug。
总结
一般形式验证的论文都会将FPV所发现的bug与CBRV做比较以此来证明它们“打扫全屋无死角”的能力,这对于开发IP确实很重要。那反过来看,如果IP验证时只采用了CBRV,而没有采用FPV的话,是不是意味着有很多“隐秘的角落”没有被访问过,手机前的你如果在做IP验证的话,是不是惊起了一身冷汗?
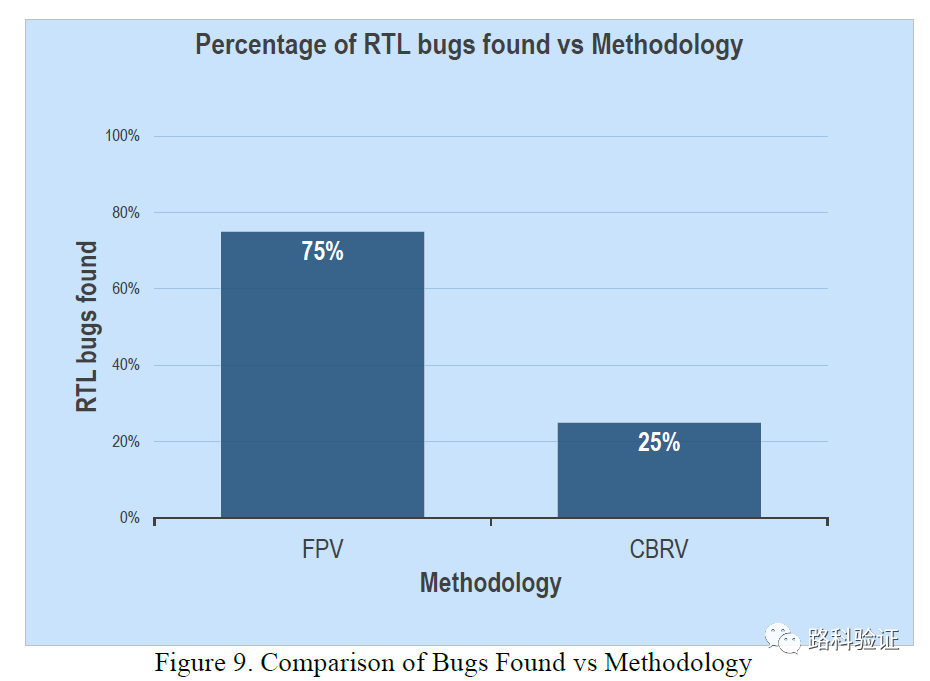
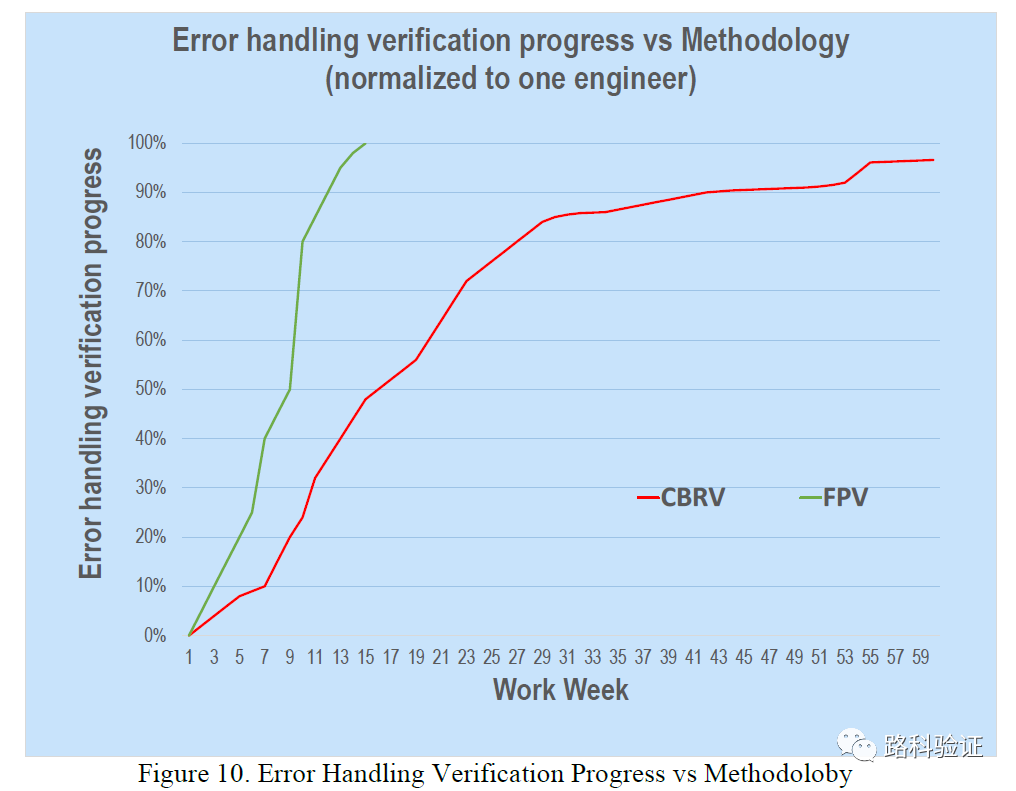
而从验证效率来看,FPV的收敛速度也较CBRV有明显提升,往往在设计75%测试点完成度上面,FPV使用了12周,而CBRV使用了28周的时间,也就是整整快了16周的时间(4个月,天啊,好奢侈的时间裕度)。不过从论文的描述来看,CBRV的环境是先行的,对于设计的理解和趟的坑也给后面开展FPV提供了提速条件。我推测做FPV和CBRV的人应该是同一批,他们一边做一边也在交叉记录和比较。
在最后的展望阶段,文章作者还预计要将这部分错误处理的经验带入到SoC验证上面,我倒是对他们准备如何展开SoC层面的分而治之的方案很感兴趣,不过相比之下我可能对于PSS的系统测试场景构建能力更有信心哦。
审核编辑:刘清
-
关于功能验证、时序验证、形式验证、时序建模的论文2011-12-07 7908
-
怎样去设计一种基于STM32的智能小车2021-10-11 1663
-
分享一种智能网卡对热迁移支持的新思路2022-07-05 4083
-
一种新的LTCC设计流程2010-07-26 1109
-
深层解析形式验证2010-08-06 4516
-
一种基于FPGA的双接口NFC芯片验证系统2017-01-03 783
-
一种基于UVM的混合信号验证环境2017-01-07 904
-
一种对于分散式交易市场中基于智能体的服务提供者的责任执行验证方法2018-05-16 4522
-
一种基于互调失真形式的射频连接器2019-09-09 980
-
一种基于UART&SPI接口验证工具的设计与实现2021-04-08 3490
-
数字芯片验证流程2022-07-25 8205
-
形式验证简介2022-07-28 3567
-
16nm技术的形式验证流程、优势和调试2022-11-24 2348
-
形式验证入门之基本概念和流程2022-12-27 4116
-
Formal Verify形式验证的流程概述2023-09-15 3268
全部0条评论

快来发表一下你的评论吧 !
