

UVM验证环境启动时及运行时的控制方案
描述
话说螺蛳壳里做道场,UVM推出这么多年以来每年DVCon会议上总还是有人分享他们基于UVM package做的一些改动,使其能够更适合项目的要求。正如这篇论文里针对uvm_cmdline_processor这个类做的改动,经过修改,UVM环境在运行时能够接收更复杂的参数,继而满足更好的控制随机数据发送的项目要求。
从项目要求来看,在验证前期随机数据的吞吐、间隔、长度并不需要特意去关注,而在数据完整性基本得到保证以后,就要考虑边界条件、性能表现等问题,也因此需要对随机数据的约束进行调节。SV调节约束,以往可以通过对随机值的rand_model或者约束块的constraint_mode进行调节,继而选择需要随机的变量和采取的约束,也可以通过在约束中植入有关影响随机范围的变量,而在仿真过程中影响这些变量去间接影响接下来生成的随机数值。
只不过,上面第一种办法对每个sequence item约束块的构造和组织有要求,而且还需要在仿真前重新编译继而影响整个RNG(random number generator),第二种办法可以在仿真过程中通过对某些变量的修改继而影响仿真过程中的随机数值,看起来是可以实现动态控制的,但也仍然不够灵活,无论是对随机数值的范围影响,还是将这种办法规范下来,都不适合在整个团队范围里去推广(可以用,但是不够完善)。
相比于将测试意图通过sequence和item传递到driver,再由driver解析驱动总线,在验证后期阶段,我们往往需要对测试序列做到更加精准的控制。论文中也提到了可以对以下几点做到控制:
对数据之间的间隔长短做控制,继而影响数据吞吐。
在处理器验证中,要控制的指令内容以及指令之间的关系均需要更多约束,往往还可以需要对操作数做到更准确的要求(比如其包含的指令、数据等信息)。
有时我们还需要在仿真过程中某个阶段,特意去控制某个component或者item,以往可以通过uvm_config_db传递(在仿真开始前)。

以上的控制尽管可以在代码中实现,但从以前的经验来看,这些代码仍然不够灵活。所谓更加灵活的要求是能够在仿真过程中将要求随时传递给仿真环境,而仿真环境又能及时接收这些配置、激励数据,继而动态地对验证模式、激励数据做出改变。
原本uvm_cmdline_processor可以支持传递int和string,但不够灵活以至于不能很好地控制上面所说的随机数有关的生成过程。而本文扩展的新类就能够从仿真时传递的命令项(同其他仿真参数一起传递并启动仿真模型)解析更为复杂的随机变量约束控制方式,继而更灵活地控制测试。
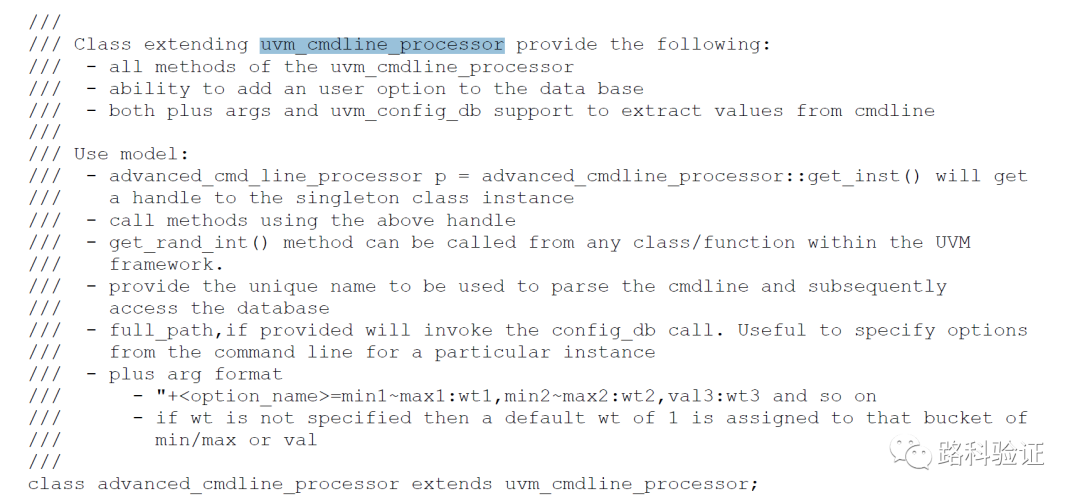
这个新的类advanced_cmd_line_processor可以解析的指令新囊括了与约束范围有关的min_val/max_val/value/weight的形式(对字符串参数形式更灵活的支持)

也可以支持对不同数据格式的支持,例如Hex/Bin/Int

由于可以在测试时传递更为多样的命令参数,UVM环境中也就可以利用advanced_cmdline_processor做相应的解析,继而获得参数。在Example1中,我们可以在测试时传递例如+opcode=ADD:80,SUB:20 或者 +operand=32'hfffffff0 或者 +oprand=32'h00000000~32'h0000000f等信息,也均可以在对应的组件中获得参数,并加以利用。

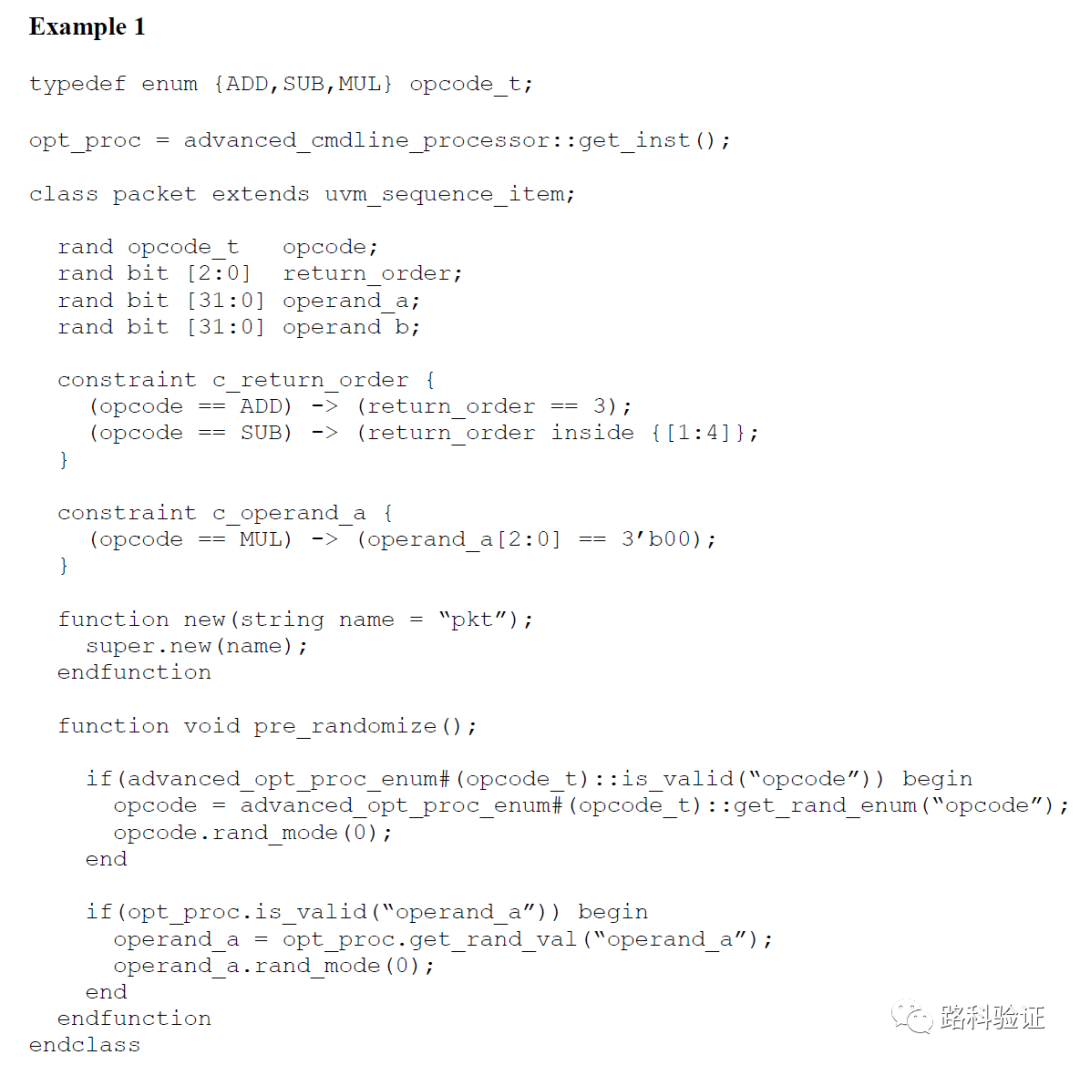
在packet::pre_randomize()函数中,就利用advanced_cmdline_processor的方法is_valid()检查测试时传递的参数,并通过get_rand_enum()获得一个符合+opcode=ADD:80,SUB:20要求的枚举值。同时,也可以通过get_rand_val()获得一个满足类似+oprand=32'h00000000~32'h0000000f要求的随机数。
除了通过命令项传递某个参数项以外,advanced_cmdline_processor也可以支持传递例如+uvm_set_config_string这样的命令项,这些命令项仍然可以通过get_rand_val()和其传递的对应UVM层次获得测试时传递的数值。这样的方法可以基于UVM层次将变量、约束范围、权重等信息更准确地传递到sequence中。
+uvm_set_config_string=*pkt_seq_1,pkt_delay,”0:50,1:50” +uvm_set_config_string=*pkt_seq_2,pkt_delay,”10~20:50,21~100:40,101~500:10”

这篇论文写得要轻松一些,读者在阅读的时候也能跟的上,在解决了一些实际问题的时候可以会心一笑。更赞的一点是,它毫无保留地把解决方案里涉及到advanced_cmdline_processor和其它类/方法都展示在附录中。基于此,这篇论文提出了一个实际工作中的痛点,然后又轻巧地给出了一个解决方案。这样的论文生命周期往往可以延续更久,因为它的目标更聚焦、也解决很多验证工程师实际工作中的麻烦,更何况还有完整的代码呈现,可以说是拿来就能用了。
不过,我们还可以围绕着灵活控制随机测试再给出路科的另外一种解决方案(来自于V3课程的某个模块)。我们希望不仅仅是在仿真前通过传递参数项来控制验证环境和激励,还希望找到一种可能,在仿真过程中可以对验证环境中的变量、约束等内容进行修改。
这里以VCS工具为例,它的UCLI(unified command line interface)提供了一种办法,可以在Tcl命令窗口一侧去调用SV中的函数或者任务。那么,我们可以将可供Tcl调用的方法放置在某个域中(例如module或者interface)。
比如我们下面的这个例子就可以实现在仿真中查询、获得、配置等目的,这些方法在接口中实现以后,在UVM和Tcl两侧均可以利用这些方法。

这里定义了一些进入某些特定scope hierarchy的接口,以便在Tcl中调用,继而在该scope中调用某些方法。

这些接口方法可以用来在仿真中设定报告信息的冗余度。

这里给了一个例子,可以在Tcl脚本的特定时间,进入某个scope,再调用相应的调试接口方法,调用这些方式时也可以传递参数,并且取得返回值。
这样的案例用来展示某些调试接口方法在仿真运行时对验证环境的控制,实际上我们在文章上半部分谈到的对于随机值的影响、某些变量的修改、某些验证组件的工作模式等,只要我们的调试接口方法定义得当,那么都可以在仿真运行过程中随时调用。
从论文描述的解决问题的初衷来看,是为了更方便地去控制激励的数据内容,而如果要再拓展那么就可以采用我们给的第二种方式在Tcl中调用某个scope中的接口方法,让Tcl与测试用例之间形成一个互动。
其实不管是C-DPI的调用方式,还是Tcl调用SV的方式,都是为了让测试在运行时能够更灵活地配置、改动(SV的重复编译在更大的环境结构下更为耗时),而相比于C-DPI的方式,通过对UVM uvm_cmdline_processor的拓展在验证环境启动,或者通过Tcl调用SV方法在验证环境运行都更为灵活。而且这两种方案也都能够做成规范,推行到团队中去。
审核编辑:刘清
-
如何缩短Vivado的运行时间2019-05-29 15697
-
如何检查Linux服务器的运行时间2022-11-25 15959
-
数字IC验证之“什么是UVM”“UVM的特点”“UVM提供哪些资源”(2)连载中...2021-01-21 4416
-
一种基于UVM的混合信号验证环境2017-01-07 896
-
紫金桥组态软件新的功能_运行时组态2017-10-13 1260
-
电机运行时间进行排列 是分为两个部分来完成这个程序的设计的2019-07-19 8839
-
如何高效测量ECU的运行时间2021-10-28 3348
-
利用Systemverilog+UVM搭建soc验证环境2022-08-08 1301
-
Go运行时:4年之后2022-11-30 1753
-
什么是Kubernetes容器运行时CRI2023-02-20 3554
-
ch32v307记录程序运行时间2023-08-22 2022
-
Xilinx运行时(XRT)发行说明2023-09-14 810
-
AUTOSAR CP运行时环境与应用软件2023-10-27 2336
-
如何保证它们容器运行时的安全?2023-11-03 1724
-
jvm运行时内存区域划分2023-12-05 1312
全部0条评论

快来发表一下你的评论吧 !
