

不同的Verilog代码功耗与面积(PPA)差距能有多大?
描述
ISP模块中的同样功能,两份代码,仿真功能都是OK的,区别是多打了一拍。PCLK时钟30MHz,且两个hsync脉冲之间的blanking是满足line_buf中数据移位输出的,如果不满足呢,那就必须多锁存一拍。
此处,在blanking时间必足够的情况下,经验丰富的老鸟可以敏锐发现问题,右下代码重复锁存,可能有提高timing的效果但并不明显,同时也浪费了19200个寄存器,存在面积浪费,那么实战一下,来对比下PPA的区别,结果一定让你“惊喜”。
优化前能跑25ns周期,即频点最大可到40MHz,
优化后能跑20ns周期,即频点最大可到50MHz,Performance性能提高25%。
PR结果:
RTL优化前如下:Density:59.67%,Gates=427032 Cells=65286 Area=3214018.7 um^2
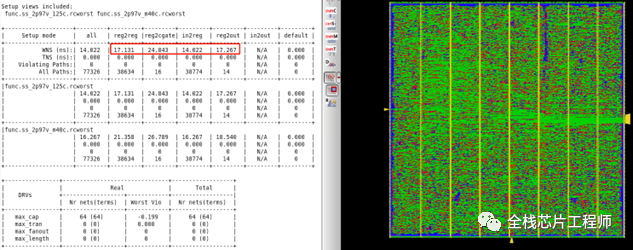
RTL优化后如下:Density:36.29%,Gates=259699 Cells=48340 Area=1954598.6 um^2
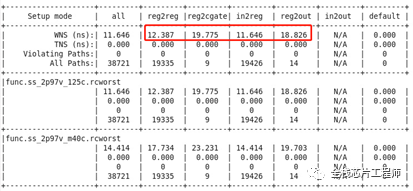
PR结论:gate从427032门降低到了259699门,节省了40%面积。在布线面积足够、timing都满足情况下,本次RTL优化节省了30%功耗、40%面积。
RTL设计优化永远止境,ICer要反复思考,追求PPA极致。
审核编辑:刘清
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
-
如何自动生成verilog代码2024-11-05 2338
-
数字前端生存指南—PPA2023-12-04 6926
-
PPA分析概述2023-08-08 836
-
Verilog边沿检测的基本原理和代码实现2023-05-12 5969
-
什么样的Verilog代码风格是好的风格?2022-10-24 2729
-
请问FreeRTOS对性能有多大提升?2020-06-19 2303
-
中美医疗水平差距有多大?2019-05-05 12674
-
8051 verilog 版代码2016-05-24 1200
-
verilog代码规范2016-03-25 774
-
verilog_代码资料2016-02-18 809
-
Verilog代码覆盖率检查2012-04-29 9141
-
Verilog HDL代码描述对状态机综合的研究2011-12-24 792
-
Verilog代码书写规范2010-04-15 696
全部0条评论

快来发表一下你的评论吧 !
