

从仿真器的角度理解Verilog语言1
电子说
描述
要想深入理解Verilog就必须正视Verilog语言同时具备硬件特性和软件特性。在当下的教学过程中,教师和教材都过于强调Verilog语言的硬件特性和可综合特性。将Verilog语言的行为级语法只作为语法设定来介绍,忽略了Verilog语言的软件特性和仿真特性。使得初学者无法理解Verilog语言在行为级语法(过程块、赋值和延迟)背后隐藏的设计思想。本文尝试从仿真器的角度对Verilog语言的语法规则进行一番解读。
“精分”的Verilog语言
在集成电路的设计流程中,Verilog源文件有两个主要作用:综合和仿真。在图1中,数字①②③④标注的位置都可以使用Verilog作为设计的描述方法。
·综合工具读入源文件,通过综合算法将设计转化为网表,比如DC。能够综合的特性要求Verilog语言能够描述信号的各种状态(0,1,x,z)、信号和模块的连接(例化)以及模块的逻辑(赋值以及各种运算符)。
·仿真器读入源文件,生成一个可执行程序用于仿真硬件的行为,比如VCS。能够仿真的特性要求Verilog语言又具有软件特性,对每一条语句的执行语义和顺序给出定义(延迟语句)。同时,软件特性使得Verilog语言更加灵活,具备了丰富的行为级仿真能力(条件分支、循环等)。
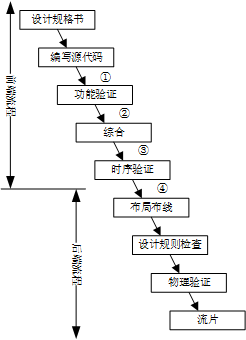
图1. 集成电路设计流程
为了满足综合和仿真的双重要求,Verilog语言的语法规则必须要同时满足硬件和软件的特质。编写Verilog代码的时候,不仅需要从硬件的角度去思考这一段代码会转换为什么样的硬件电路,还要从软件的角度去思考这一段代码在仿真器如何表现。如此日复一日,隐隐有精神分裂之感。Verilog代码与硬件电路的关系已经在大量的书籍中得到了充分的论述。本文重点聊一聊从软件的角度如何理解Verilog。
从软件的角度理解Verilog并不是要把Verilog看成一种可执行程序,试图去理解每一条语句对应的语义。如果这样做,就陷入更深的误区而不能自拔。很多的语句规则和规定也会变得混乱而不可理解。在试图从软件角度理解Verilog语言之前,必须要坚定Verilog是一种硬件描述语言的观点。
从软件的角度理解Verilog的本质是理解Verilog语言在软件仿真器中的行为。Verilog语言本身是不能执行的。实际上,Verilog提供了一套描述硬件电路行为的规范。这套规范的设计与仿真器的设计是相互适应的。仿真器根据Verilog文件产生一个可执行的仿真程序。这个仿真程序才是真正的软件程序。
在目前的教学过程中,Verilog的硬件特性得到了充分的强调。在开始学习Verilog的第一天,很多同学就会被老师们教育:Verilog描述的是硬件,Verilog不是软件。这般强调的目标是为了避免大家将Verilog语言与纯粹的软件语言(C,java,python等)混为一谈。但是同时也有些矫枉过正。对于Verilog的软件特性只介绍是什么而不介绍为什么,而且几乎不涉及仿真器的内容。在讲授Verilog语言的时候,也只能含糊地从语义的角度介绍Verilog的各种语法规则。不论是数字电路、集成电路设计等课程都不会给学生介绍仿真器的基本结构和运行机制。
此外,国内长期不重视电子设计自动化(EDA)工具的研究,不重视设计方法学和设计流程的探索和演进,习惯拿来主义。最终导致我国严重缺乏EDA专业相关人才储备。任课教师普遍对工具背后的软件机制不清楚,也只有避免讲Verilog的软件属性,才能避免课堂上的尴尬。在这样的教学方式下,学生很难对Verilog语言甚至HDL语言建立起正确的理解和知识体系。
仿真器基本架构
Verilog语言确实不是一种可执行语言。图2展示了利用Verilog源文件进行仿真的过程。绝大多数仿真器都遵循这一思路,比如VCS、iVerilog、ModelSim、Vivado和Quartus等。首先,准备Verilog源文件以及一些Verilog库文件(标准单元等)。仿真器接收这些Verilog文件并将其转化为可执行的仿真源文件(C/C++等)。在这一过程中,仿真器解析Verilog文件的语法结构,并且根据Verilog语法的规范,将语法结构转化为仿真器中的事件响应函数或代码段。这些函数和代码段与仿真器框架源文件一起成为可执行仿真程序的源文件。接下类这些源文件经过编译得到可执行的仿真程序。VCS和iVerilog可以看到生成的可执行文件。ModelSim、Vivado和Quartus使用GUI管理设计流程,从而将这个可执行文件屏蔽了,使其对于用户可透明。用户可以在工程中找到生成的可执行文件。最后,运行可执行的仿真程序,进行软件仿真。
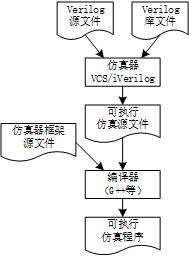
图2 从Verilog源文件到可执行仿真程序的流程
可执行仿真源文件和仿真器框架源文件一般是不可见的。不过在开源软件(例如iVerilog)中可以找到生成可执行仿真源文件的代码。
仿真程序通常采用基于事件的仿真架构。这种仿真架构的核心是事件队列。事件队列中按照事件的响应时间排列着一系列的事件。响应时间相同的事件之间不应该有决定性的事件依赖关系。如果需要确定这些事件之间的顺序,可以引入Δ时间。响应时间为t+Δ的事件必然晚于响应时间为t的事件。但是从仿真时间上,仍然表现为在相同时刻响应。
事件队列按照时间先后顺序逐个响应事件队列中的事件。每一个事件,除了标注事件响应时间,还会标注事件类型以及其他需要的参数。通过事件类型,仿真引擎可以找到对应的响应函数。其他的参数则作为事件响应函数的输入参数。事件响应函数会产生新的事件。这些新的事件还会插入到事件队列中,并且按照其响应时间排序。
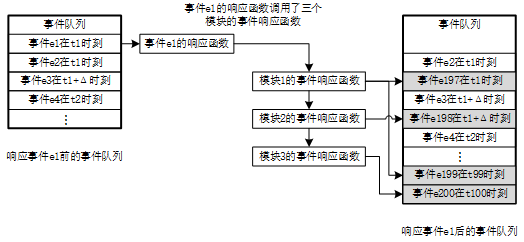
图3 事件队列仿真框架的示意图
图3展示仿真引擎响应一个事件的过程。仿真引擎响应事件队列中的第一个事件e1。事件e1被从队列中移除。事件队列从事件e2开始。仿真引擎根据e1的类型找到了事件响应函数。这个响应函数又调用了3个模块中的事件响应函数。这些事件响应函数模拟硬件电路的行为,并且产生了新的事件。模块1产生了事件e197和e199,分别插入到t1时刻和t99时刻;模块2产生了事件e198,插入t1+Δ时刻;模块3产生了事件e200,插入t100时刻。
通过“读出第一个事件-响应事件-插入新事件”的循环,事件队列可以一直运行下去,直到事件队列为空或者达到了仿真结束的时间。另一方面,在仿真开始的时候,必须向事件队列中插入起始事件,从而开始仿真循环。
Verilog仿真器提供了仿真引擎(在图2中的仿真器框架源文件部分),所以大家在写Verilog的时候不用去自己“造轮子”。但是仿真引擎并不知道事件和响应函数的对应关系以及响应函数的具体功能。仿真器的工作就是将Verilog文件转化为仿真响应函数并且与仿真引擎进行连接。生成的可执行仿真源文件和仿真器框架文件一起构成了完整的仿真器。
接下来,分析一下Verilog的语法结构(过程块、赋值和延迟)如何变成仿真器的源文件。
过程块
always过程块是Verilog最基本的行为级描述结构。通过在always语句中设置敏感列表,可以在恰当的时刻触发过程块内的操作。敏感列表中使用的条件主要是信号沿(上升沿、下降沿)以及信号值变化两种。如果敏感列表有多个条件,这些条件是“或”的关系,也就说只要有一个条件满足,always过程块中的语句就会执行一次。
对应到仿真器中,always过程块的语义就是给仿真中的特定事件绑定响应函数。always过程块中的语句序列是事件响应函数的函数体,而always语句的敏感列表确定了这个事件响应函数与哪些事件绑定。
例如下面的D触发器。
always @ (posedge clk) begin
q <= d;
end
经过仿真器的转换就变成为如下的响应函数:
function always_block1 :
q = d;
这个响应函数会与clk信号的上升沿事件(positive)进行绑定。当响应clk信号的上升沿事件的时候,仿真器会调用always_block1这个函数。
一个条件可以被绑定多个事件响应函数。比如时钟信号的事件可以与所有的always块的事件响应函数绑定。当时钟信号的事件发生的时候,与其绑定的事件响应函数会逐个被调用。如果一个信号在多个always过程块中都被赋值,那么一个变量会被多个事件响应函数修改。在硬件上,这些响应函数之间应该是并发的,没有先后关系。但是,串行执行函数的软件是做不到的这样的并发的。在仿真器中,always过程块之间也是有顺序的。Verilog规定,always块之间的执行顺序是按照always块在Verilog文件中的先后顺序。这仅仅是为了适应软件仿真器所引入的设定。
如果敏感列表中有多个条件,表示always块与这些信号都绑定。如果always块没有执行敏感列表或者是给出一个星号(*),表示always块应该与过程块中所有的右值变量绑定。在这种情况下,由每个事件都直接触发事件响应函数可能会引起重复响应,即在某个时刻事件响应函数被多次触发的情况。为了避免这样的错误,仿真器中引入了仿真阶段的概念。同一个仿真阶段中响应的事件,响应时间必须,而且Δ时间也必须相同。在同一个仿真阶段中,每个事件响应信号只能被触发一次。每个仿真阶段中,首先在事件队列中找到需要响应事件,然后累计需要调用的事件响应函数。最后再依次调用这些事件响应函数。这样就保证了同一个时间的信号变化只会触发同一个always过程块一次。
除了always过程块,在Verilog中还定义了其他的过程块。与always过程块不同,这些过程块不由信号的事件触发,而是要单独在事件队列上插入事件,并且与过程块转化成的响应函数绑定。initial过程块只在仿真开始的时候执行一次。也就是说,如果定义initial过程块,那么事件队列上的第一个事件就是initial过程块的事件。repeat过程块和forever过程块在事件响应函数结束时向电路中添加触发下一次响应函数的事件。这个事件在下一个Δ时刻就会响应,由此往复。当重复了足够多次数后,repeat过程块会停止向事件队列中添加事件,从而结束repeat语句。forever过程块的循环不会结束。
赋值语句
Verilog语言提供了阻塞赋值和非阻塞赋值两种赋值语句。
a = b; // 阻塞赋值
a <= b; // 非阻塞赋值
按照语法定义,阻塞赋值会阻塞之后语句的执行;非阻塞赋值则不会阻塞之后语句的执行。阻塞语句达成的效果是下一条语句执行之前信号a已经变修改。非阻塞赋值达成的效果是,信号a的值只有到整个过程块执行完,才会被修改。需要注意的是,非阻塞赋值虽然被延后,但是所赋的值仍是之前得到的值。
这一段话着实令人感到疑惑。现在我们从软件仿真器的角度重新来解析赋值语句。赋值语句其实包含两个过程:评估和更新。评估过程确定了需要赋给信号的值,而更新过程才真正的修改了信号的值。评估过程和更新过程是相互独立的。这两个过程中的关联只有需要赋的值。
阻塞赋值的评估过程和更新过程是连续执行的,评估之后立即更新。所以,在执行下一条语句的时候,信号已经被修改了。在转换成仿真器代码时,阻塞赋值不需要特殊处理。例如
always @(a, b, c) begin : add_mux1
t = a + b;
d = t * c;
end
上述代码转化后的事件响应函数为
function add_mux1 :
t = a + b;
d = t * c;
非阻塞赋值的评估过程和更新过程是分开的。过程块中执行到赋值语句的时候,只进行了评估过程,确定需要赋给信号的值,然后继续向后执行。更新过程被延后到整个过程块执行之后。例如
always @(a, b, c) begin : add_mux2
t <= a + b;
d <= t * c;
end
上述代码转化后的事件响应函数为
function add_mux2 :
t_update = a + b;
d_update = t * c;
t = t_update;
d = d_update;
当阻塞赋值和非阻塞赋值混合的时候,也遵循同样的规则。例如
always @(a, b, c) begin : add_mux3
t <= a + b;
d = t * c;
end
上述代码转化后的事件响应函数为
function add_mux3 :
t_update = a + b;
d = t * c;
t = t_update;
对信号的赋值会产生一个事件,事件表示被赋值的信号发生了变化。如果有其他的过程块依赖于被赋值的信号,那么这个事件会被添加到事件队列中;反之,这个事件会被忽略。事件的响应时间为当前时间加Δ。赋值语句是仿真引擎能够持续运行的关键。大部分always块都是通过赋值语句向事件队列添加新的事件的。
-
从仿真器的角度理解Verilog语言22023-05-25 1714
-
解码国产EDA数字仿真器系列之二 | 如何实现全面的SystemVerilog语法覆盖?2023-04-07 1364
-
verilog仿真工具编译2022-08-15 9929
-
Vivado仿真器进行混合语言仿真的一些要点2022-08-01 2088
-
从仿真器的角度对Verilog语言的语法规则进行解读2022-07-07 1196
-
STM32-DAP仿真器的使用(1)2021-11-18 1934
-
使用Vivado仿真器进行混合语言仿真的一些要点2021-10-28 4189
-
Verilog语言中阻塞和非阻塞赋值的不同2021-08-17 7497
-
Verilog硬件描述语言参考手册免费下载2021-02-05 1725
-
快速理解Verilog语言2020-03-22 5974
-
明德扬至简设计法--verilog的综合器和仿真器2018-10-08 1831
-
VERILOG仿真器2011-04-05 1768
-
模拟/混合信号仿真器2011-03-31 1213
-
Aldec 多语言仿真器锁定主流用户2010-02-08 1630
全部0条评论

快来发表一下你的评论吧 !
