

 【核芯观察】ChatGPT背后的算力芯片(三)
【核芯观察】ChatGPT背后的算力芯片(三)
描述
【核芯观察】是电子发烧友编辑部出品的深度系列专栏,目的是用最直观的方式令读者尽快理解电子产业架构,理清上、中、下游的各个环节,同时迅速了解各大细分环节中的行业现状。以ChatGPT为首的AI大模型在今年以来可以说是最热的赛道,而AI大模型对算力的需求爆发,也带动了AI服务器中各种类型的芯片需求,所以本期核芯观察将关注ChatGPT背后所用到的算力芯片产业链,梳理目前主流类型的AI算力芯片产业上下游企业以及运作模式。
接上期ChatGPT背后的算力芯片(二)
AI服务器中的主要算力芯片之FPGA
市场现状
FPGA的最大特点就是,在芯片被设计、制造完成之后,用户依然可以通过修改其逻辑单元和开关阵列编程,来进行功能配置,实现所需要的功能。在AI算法快速迭代的过程中,用户可以通过持续优化FPGA的功能配置,来提高运算效率。这也是FPGA与CPU、GPU、ASIC等芯片最大的不同。
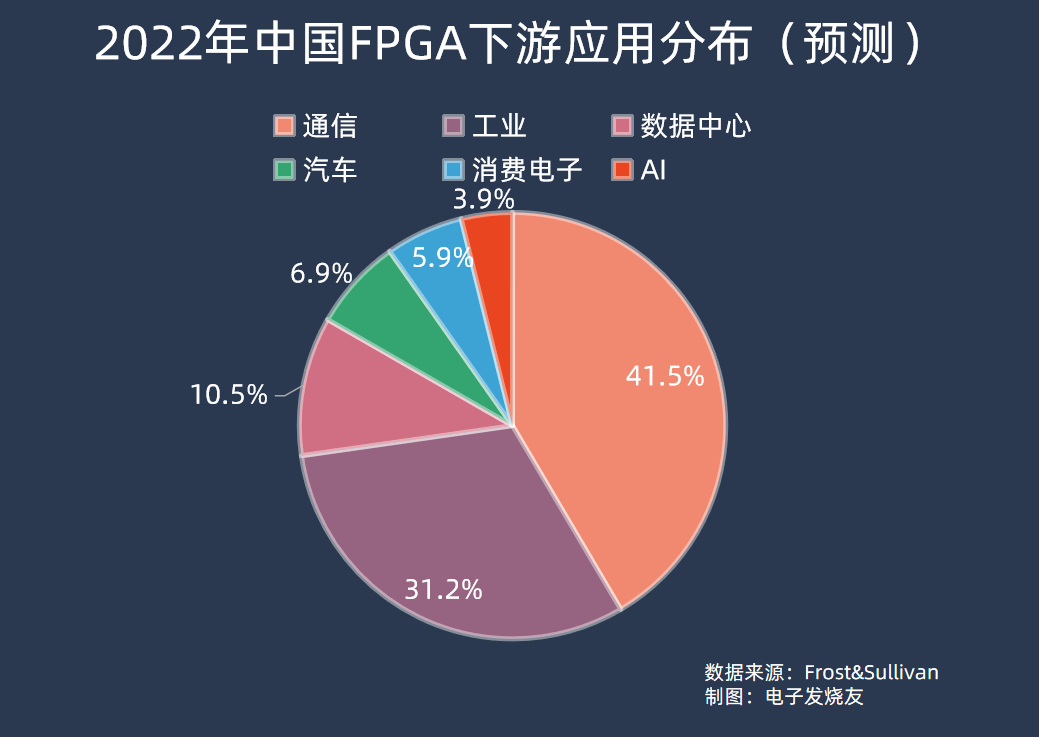
所以最初FPGA被大量用于通信领域,可以灵活更改高速通信协议的处理方式,适配不同场景。根据Frost&Sullivan的预测数据,2022年中国FPGA下游应用中,通信占比最高为41.52%,工业应用其次,占比31.23%。数据中心、汽车、消费电子、AI分别占比10.54%、6.94%、5.89%、3.88%。
从全球市场来看,根据Frost&Sullivan数据,估算2021年全球FPGA市场规模为68.6亿美元,2022年预计为79.4亿美元,同比增长15.7%;到2025年市场规模将增长至125.8亿美元,2021年到2025年年均复合增长率约16.4%。
中国市场上,2021年FPGA市场规模为176.8亿元,到2025年 FPGA芯片销售额将达到332.2亿元,2021至2025年年均复合增长率将达到17.1%。出货量方面,中国市场FPGA芯片出货量在2020年约为1.6亿颗,预计到2025年将达到3.3亿颗,2021至2025年年均复合增长率将达到15.0%。
其中数据中心、AI领域市场增长迅速,FPGA能够使数据中心的不同器件更加有效地协同,最大程度发挥每个器件的硬件优势避免数据转换导致的算力空耗;在运算加速领域,FPGA 在矩阵运算、图像处理、机器学习、非对称加密、搜索排序等领域有着很广阔的应用前景。
在中国数据中心细分市场,Frost&Sullivan预计该市场规模在2021年为18.7亿元,到2025年会达到34.6亿元,其间年均复合增长率将为16.6%。
不过自去年年底以来,由OpenAI掀起的AI热潮,有望推动FPGA市场以远超出此前预期的速度增长。
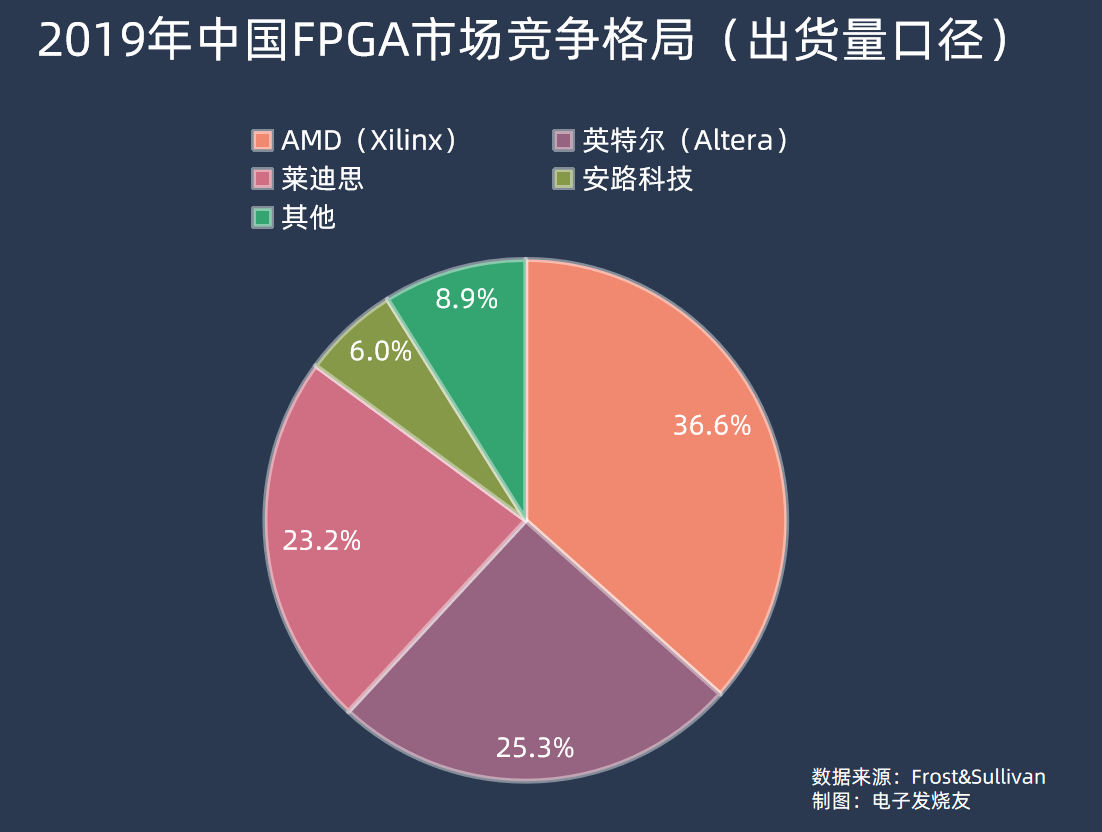
近年没有新的FPGA市场份额数据,按照Frost&Sullivan 2019年的数据,中国市场上AMD(赛灵思)、英特尔(Altera)两家占到FPGA市场销售额的九成以上,分别为55.1%和36%。而按照FPGA出货量来看,同期AMD占36.6%、英特尔占25.3%、莱迪思占23.2%、安路科技占6%。
FPGA的核心参数是逻辑单元容量,按照逻辑单元容量来分,2019年中国FPGA市场中需求量最大的是100K以下和100K—500K逻辑单元容量的FPGA,份额分别占市场的38.2%和31.7%,更高端的500K-1KK以及1KK以上逻辑单元容量的FPGA则分别占24.4%和5.7%的份额。
全球范围来看,FPGA市场目前由AMD和英特尔双寡头垄断,占整个市场份额近90%,第二梯队的海外厂商有莱迪思、Microsemi等,各占5%左右。国内FPGA厂商主要有复旦微电子、紫光国微(紫光同创)、安路科技、高云半导体、华微电子、智多晶、京微齐力等等,不过从逻辑单元容量来看,国内厂商主要集中在500K以下,更多产品线的逻辑单元容量在200K以下,中低端市场布局较为完善,但中高端领域目前国产FPGA仍未有大规模涉足。
复旦微电子在2018年推出了亿门级FPGA系列,逻辑单元容量可达700K,据了解,其新一代十亿门级的大容量FPGA有望在2023年内推出。而2019年英特尔推出的 Stratix 10 GX 10M FPGA逻辑单元已经高达10KK,相比之下国产FPGA在高端市场目前缺口还是较大的,但目前重要的是在中低端市场站稳,夺得更多的国内市场份额。
AI服务器FPGA的趋势
衡量FPGA的容量,有两个阶段,在2000年以前,FPGA厂商用门级数量规模来衡量FPGA的容量,因为ASIC的最小功能单元是“门”,而本质上FPGA与ASIC都可以同样功能,甚至在ASIC设计过程中都会使用到FPGA进行验证,所以“门”可以间接体现FPGA的容量。
后来2000年后,FPGA厂商逐渐开始转用统一的逻辑单元来表示FPGA容量,这主要是由于FPGA性能需求的升级,芯片内部的LUT结构和集成度不断改变,用门级数来表示FPGA容量越来越难。
如今FPGA不仅是单纯的FPGA,而是将RAM、DSP、收发器、DDR接口、CPU、GPU等许多功能嵌入到 FPGA 中,所以对于FPGA的评价指标,也变得更加复杂,需要根据不同应用去衡量参数。
在AI服务器中,FPGA往往起到加速计算的作用,FPGA的特性可以令其在深度学习中异构计算、并行计算方面有一定优势,且其具备低延时的特性,在AI服务器中FPGA还可以实现数据高速收发、交换等功能。同时,相比于CPU和GPU,FPGA单位能耗比还更低,特别在深度学习领域,近年来微软、百度、亚马逊等已经在数据中心大规模部署FPGA。
有数据显示,在保持相同神经网络模型计算结果的同时,FPGA平台的16位定点计算性能普遍是CPU的2到3倍,计算资源利用率更是CPU的接近20倍;与GPU相比,尽管计算性能没有明显领先,但功耗显著降低,所以FPGA在AI服务器中用于计算加速是有明显优势的。
在AI服务器中,FPGA的一些重要指标包括逻辑单元数、DSP的数量、收发器的传输速率等。另一方面,FPGA的制程工艺也是考量FPGA的一个重要标准,目前高端FPGA的制程基本是20nm以下,AMD目前最高端的产品线就采用台积电16nm制程。
同时逻辑单元数大于700K,基本在1KK以上的水平;DSP的数量较多,比如超过10000的DSP;较高的Bloch RAM容量,比如1000Mb以上;收发器速率高于50GB/s,还集成CPU等的处理单元和PCIe 5等先进接口。
总而言之,高端的FPGA往往以SoC的形式呈现。而为了更加便于数据中心、AI服务器等应用的导入,FPGA厂商也提供了比如数据中心加速卡的解决方案,比如AMD Alveo系列。
AI服务器中的主要算力芯片之ASIC
市场现状
近年来,TPU、NPU、VPU、DPU、BPU等各种名词层出不穷,其实这些从广义的概念看都属于ASIC。
ASIC其实与前面提到的FPGA有密切的关系,在ASIC开发的过程中,往往要用到FPGA验证。理论上一些芯片功能如果能用FPGA做出来,那么ASIC就同样可以做到,本质上是用两种不同的设计理念来让芯片实现部分相同的功能。
当然,FPGA的灵活程度是ASIC不可比拟的,ASIC自设计之初就被限定了功能,无法像FPGA一样在实际使用中还可以随时重新配置芯片功能。
虽然ASIC的设计流程漫长,但ASIC相比FPGA由于进行了完整的定制,专为特定程序优化电路,在进行特定任务时性能会更加稳定,并且运行效率、能效比都会优于FPGA。
根据Bob Broderson数据,FPGA的能效比集中在1-10MOPS/mW之间。ASIC的能效比处于专用硬件水平,超过100MOPS/mW,是FPGA的10倍以上。
目前来看,在AI服务器场景中,ASIC主要用于推理服务器,针对已经训练完成的模型来设计高效的运算硬件。但当前AI大模型领域正处于爆发初期,ASIC在AI服务器上的份额或许会呈现后发趋势,在相关应用的AI模型成熟后,未来在云端推理方面将有较大的市场空间。正如地平线CEO余凯曾说的,“一旦软件算法固定下来,专用集成电路ASIC一定是未来的方向”。
KBVResearch报告数据显示,到2025年,全球ASIC芯片市场规模预计将达到247亿美元,在2019到2025年间的复合年增长率为8.2%。
也正因为目前应用方面的一些难点,暂时来看,全球ASIC市场还未出现明显的领先者,海内外厂商都在高速发展的过程中。
海外的主要玩家有谷歌、Habana(英特尔收购)等,谷歌目前已经推出了四代 TPU产品,TPU v5据称即将在今年内面世;英特尔在2019年收购了Habana,随后在2022年推出了Gaudi 2;云服务器巨头亚马逊也在持续布局开发ASIC,此前亚马逊计划在Alexa语音助手运算上采用ASIC,以降低对英伟达的依赖;微软近几年都有消息传出,正在开发一款名为Athena的AI训练专用ASIC,据称还将采用台积电5nm制程,不过还未有这款芯片的具体消息。
国内玩家有海思、寒武纪、燧原科技、百度、阿里等,其中海思、百度、阿里由于其公司业务场景对ASIC存在天然需求,因此选择ASIC能降低其服务器建设成本。海思在2019年推出了昇腾910,百度也在同年推出了昆仑芯片、阿里也在2019年推出了含光800。
其中华为通过ASIC部署了端到端的完整生态,比如使用昇腾910时,需要搭配华为的大模型支持框架MindSpore和盘古大模型等;阿里则将含光800用于自家业务平台的加速,比如为淘宝等平台提供算力支持;百度的昆仑芯则主要在自身服务器、算力集群等应用,对政企客户等提供算力。
以公开的算力数据来算,海思的昇腾910在BF16浮点算力为320Tflops,已经超越谷歌最新一代产品TPUv4的275Tflops,在INT8定点算力上同样大幅领先。同时遂原科技和寒武纪的产品在整体性能上也与谷歌的TPUv4相差不远,当然,由于应用上的区别,可能是设计上有不同倾向,比如TPUv4互联带宽较高,1000GB/s远远领先于遂原科技和寒武纪的产品。
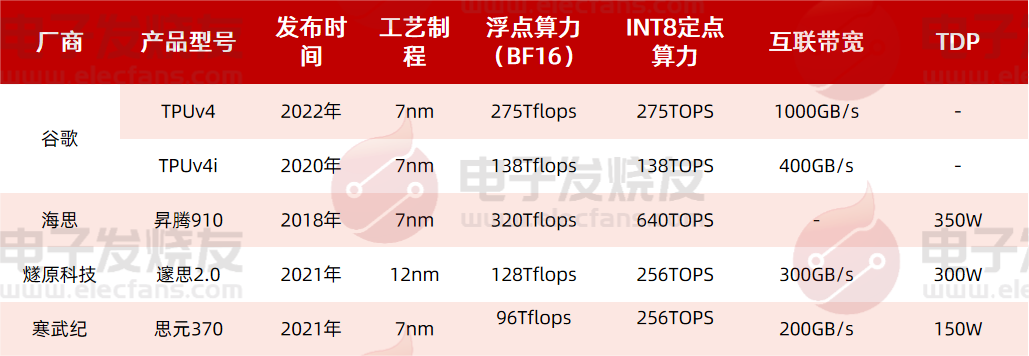
燧原科技在2021年推出了邃思2.0,采用12nm制程,单精度 FP32 算力为 40TFLOPS,单精度张量 TF32 算力为 160TFLOPS,整数精度 INT8 算力为 320TOPS,可用于云端AI训练;同期寒武纪也推出了思元370芯片,采用7nm先进制程,算力最高可达 256TOPS (INT8),可灵活应用于云端推理、训练等领域。
AI服务器上ASIC的发展趋势
ASIC作为一种专用的集成电路,它的发展永远是跟随算法需求而定,这种表现在谷歌、百度、阿里、华为等云服务厂商中可能尤为明显。
不过在2020年,英特尔发布了全新可定制解决方案,同时也将“结构化ASIC”的概念带火。从上文我们也了解到,FPGA与ASIC关系密切,同时又各有优势,英特尔提出的“结构化ASIC”,就是一种各项特性上介于FPGA和ASIC之间的芯片。
这种结构化ASIC在量产成本、逻辑门利用率、能耗、效能速度等表现上优于FPGA,但又不如纯ASIC表现得优异,同时也具有FPGA的可编程化逻辑功效,以及加速芯片的研发设计速度与修改弹性,使芯片能更快完成并投入市场。
简单来说,结构化ASIC是一种“半成品”的ASIC,它的性能和功耗接近标准单元ASIC,同时能够节省一半的一次性工程费用和设计时间。但也有所损失,因为密度只有标准单元ASIC的50%到75%,所以结构化ASIC的成本会是标准单元ASIC的1.5-2倍。
按照英特尔的说法,采用结构化ASIC后,芯片编程不能像FPGA一样可以在现场修改,而是需要在芯片工厂完成对芯片的编程。尽管成本仍然高达数十万美元,但只需要几个月时间就可以完成,传统ASIC则至少需要两年。
所以目前ASIC的一个最大痛点是,设计时间和资源消耗,这在如今快速迭代的AI大模型和AI算法中,是难以成为主流的。而从结构化ASIC的发展来看,事实上这个概念并非英特尔首创,但过去由于半导体工艺制程的高速发展,使得制程带来的性能红利要远远大于ASIC的带来的能效提升,因此结构化ASIC没有受到市场重视。
而近年来摩尔定律逐渐放缓,芯片制程工艺也已经迈入一个较为稳定的阶段,因此现阶段ASIC应用的主要限制就在于设计周期和流片等工程费用投入。或许结构化ASIC能够成为下一阶段ASIC的一个重要发展方向,加速ASIC在AI服务器上的部署。
值得一提的是,电子发烧友网主办的第七届人工智能大会将在2023年8月23日正式召开,
在过去的三届大会中,我们举办的“中国人工智能卓越创新奖”评选活动得到了业界的普遍认可和广泛好评。2023年我们将继续这一殊荣的评选,举办“2023第四届中国人工智能卓越创新奖”评选活动,旨在发掘和表彰人工智能领域优秀人才、企业、技术以及产品。
“2023第四届中国人工智能卓越创新奖”奖项提名于即日起到6月30日截至,提名详情可扫描下方二维码了解。

声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
-
芯科技,解密ChatGPT畅聊之算力芯片2023-12-27 2393
-
云端算力芯片为什么是科技石油?2023-07-12 2097
-
【核芯观察】ChatGPT背后的算力芯片(二)2023-05-28 4632
-
ChatGPT背后的算力芯片2023-05-21 5121
-
科技大厂竞逐AIGC,中国的ChatGPT在哪?2023-03-03 2375
-
如何测算ChatGPT算力需求?2023-03-02 3227
-
ChatGPT大火!庞大的AI算力需求面临巨大挑战2023-02-15 765
-
【AI简报第20230210期】 ChatGPT爆火背后、为AIoT和边缘侧AI喂算力的RISC-V2023-02-12 2765
-
1000TOPS背后的“大算力芯片”2022-12-12 5979
-
昆仑芯AI芯片以AI算力服务实体经济 筑底算力经济新基建2022-10-19 4040
-
多芯核结构ARM芯片的选择2011-09-05 3787
全部0条评论

快来发表一下你的评论吧 !
