

FPGA的数字信号处理:重写FIR逻辑以满足时序要求
描述
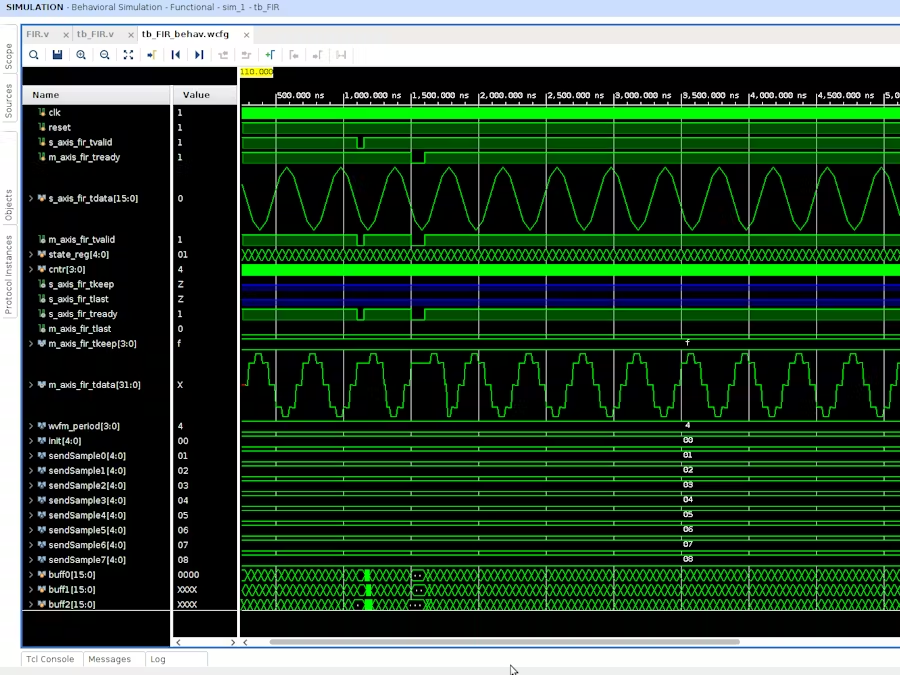
在上一篇文章中(FPGA 的数字信号处理:Verilog 实现简单的 FIR 滤波器)演示了在 Verilog 中编写自定义 FIR 模块的初始demo。该项目在行为仿真中正常,但在布局和布线时未能满足时序要求。
所以今天的文章让我们来看看当设计不能满足时序要求时如何分析并解决它。
当在目标 FPGA 芯片中布局和布线时,首先在 Vivado 中确定时序要求.
将 FIR 作为RTL 模块导入到block design中,其中通过AXI DMA 从存储器传输相位增量偏移值的DDS可以输入可变频率正弦曲线,这样就可以演示FIR的行为。
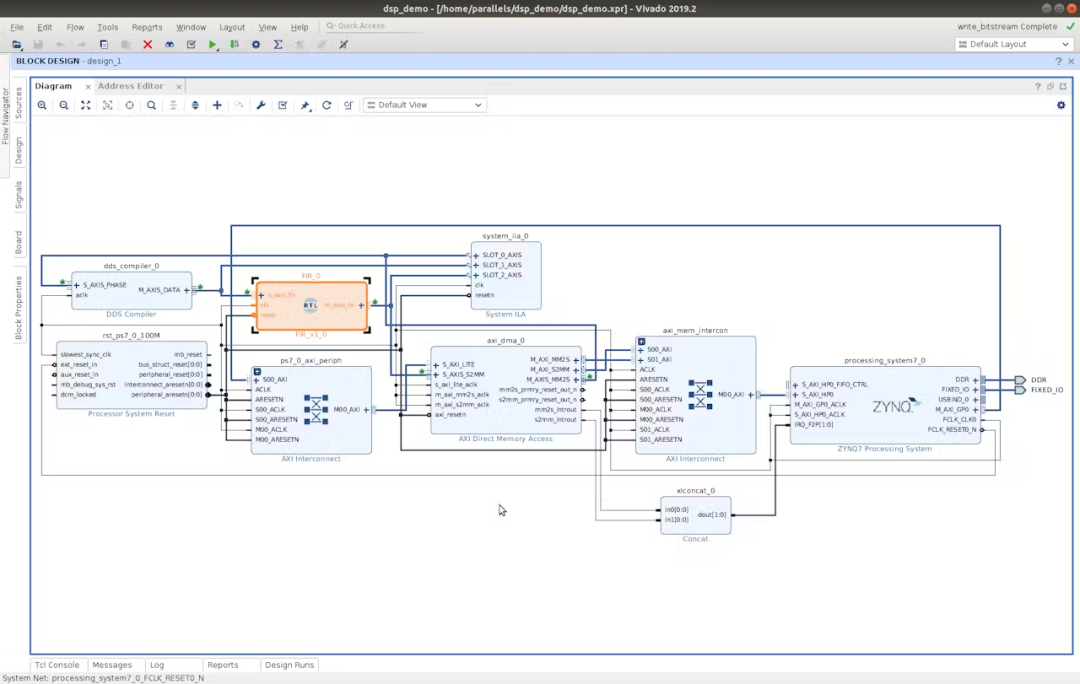
在 Vivado 中综合布局布线并打开设计后,会弹出严重警告,告知设计不符合时序要求。
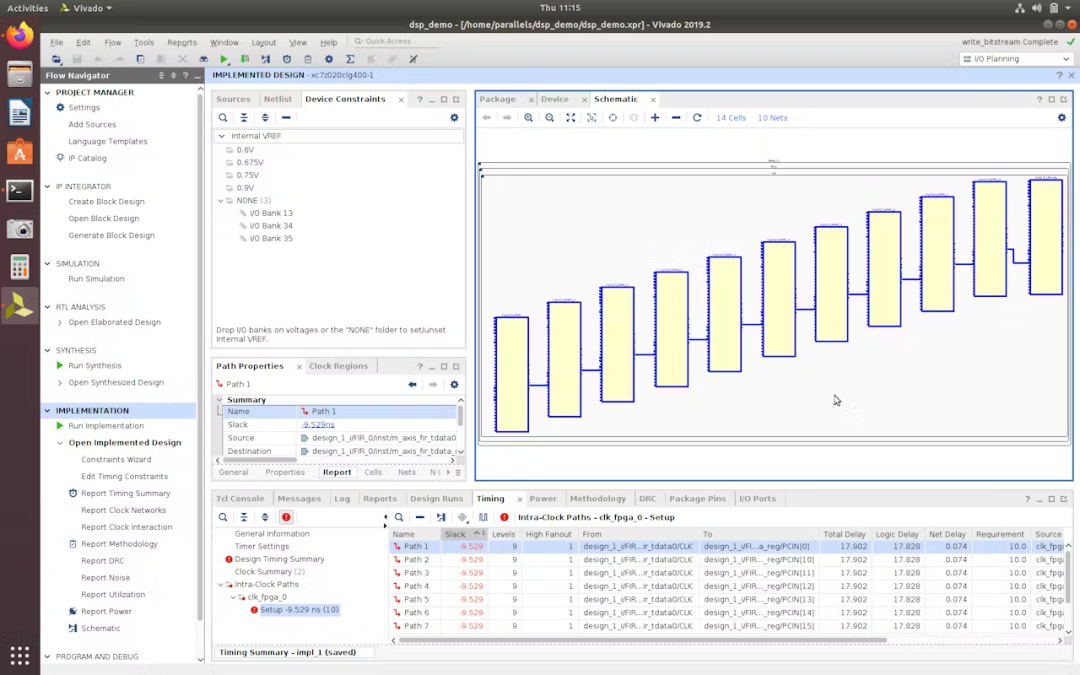
为了能够准确查看设计时序失败的原因,在已完成综合设计的底部窗口包含一个选项卡,用于 Vivado 在综合期间对设计执行的时序分析。当存在时序失败的信号路径时,用户可以过滤此时序分析以仅使用下图中显示的红色圆圈感叹号查看这些违规路径:
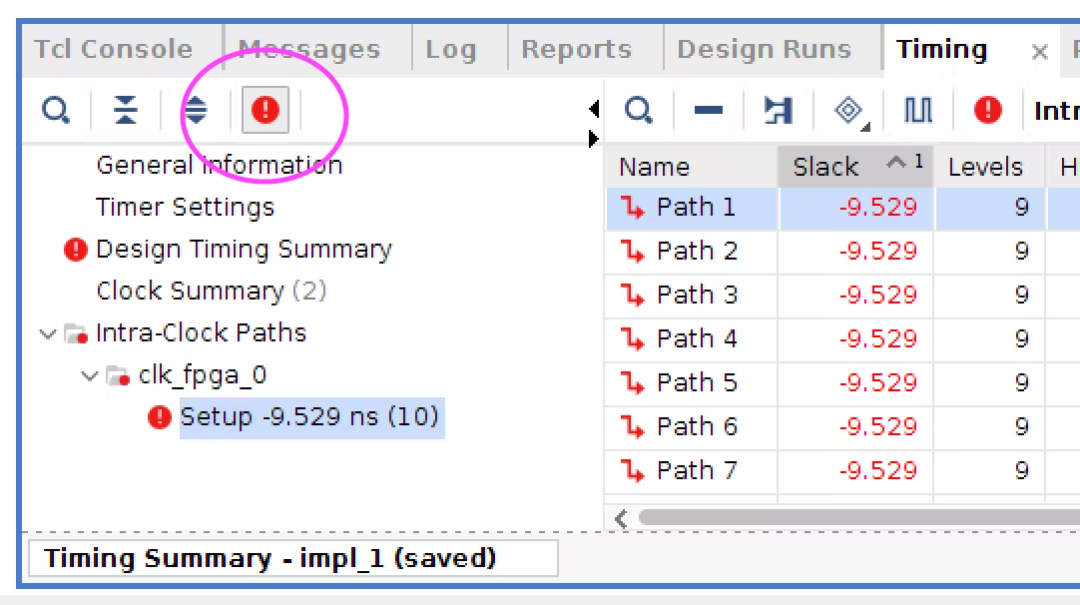
在这个特定的设计中,有几个信号路径未能达到其分配的时序,这意味着信号的物理距离太远而无法穿过芯片和/或在信号出去之前需要通过太多的逻辑级别。保持时间太长的信号意味着当将其计时到下一级寄存器中时,不能依赖它的值是否有效,从而使其余下游逻辑的行为不可靠/不可预测。
s_axis_fir_tdata在这种情况下,进入 FIR 模块的 AXI Stream 输入接口的数据信号需要很长时间才能到达m_axis_fir_tdata目标寄存器处的输出。要查看比屏幕底部的时序分析窗口中的内容更多的详细信息,右键单击底部时序分析窗口中的违规信号路径,然后选择“查看路径报告(View Path Report)”选项。然后,将能够看到 Vivado 如何计算出该信号的允许建立时间,并与它实际给出的 HDL 设计编写方式进行比较。这会给一些提示,说明是什么导致建立时间延长。然而,我发现要真正可视化保持时序违规比在示意图中查看信号会更直观。
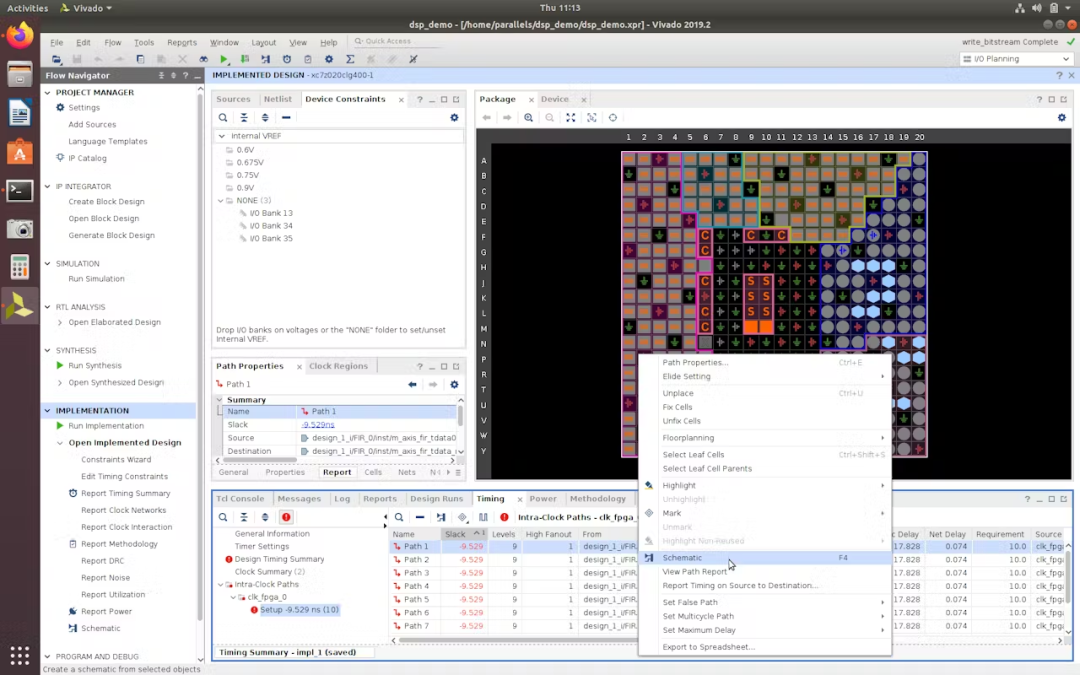
要在原理图中打开特定信号路径,再次右键单击底部时序分析窗口中的违规信号路径,然后选择“Schematic”选项。将打开一个新选项卡,显示信号路径在设计的物理布局中经过的逻辑。
在为axis_fir_tdata的数据总线中的一个位打开信号路径时,它揭示了设计在芯片中的布线,从图中可以看出信号必须通过 11 级逻辑串行后才能到达其目的地。
既然对已实施设计的分析已经揭示了哪些信号路径是哪个时序违规的问题,现在的问题是我们如何解决它?在这种情况下,很明显需要重新设计当前逻辑,以更并行的方式处理更小的数据块,从而缩短数据到其目标寄存器的总路径。
个人更喜欢在尝试编写任何实际的 Verilog 代码之前绘制出逻辑。当有这种设计执行的操作的可视化表示时,调试设计会容易得多,特别是对于跟踪此类时序违规等问题。
检查当前 FIR 模块的逻辑设计,其中数据总线违反了建立时序,很明显循环缓冲区串行填充然后将所有 15 个数据发送到累加块时,立即求和会产生大量的处理延迟。
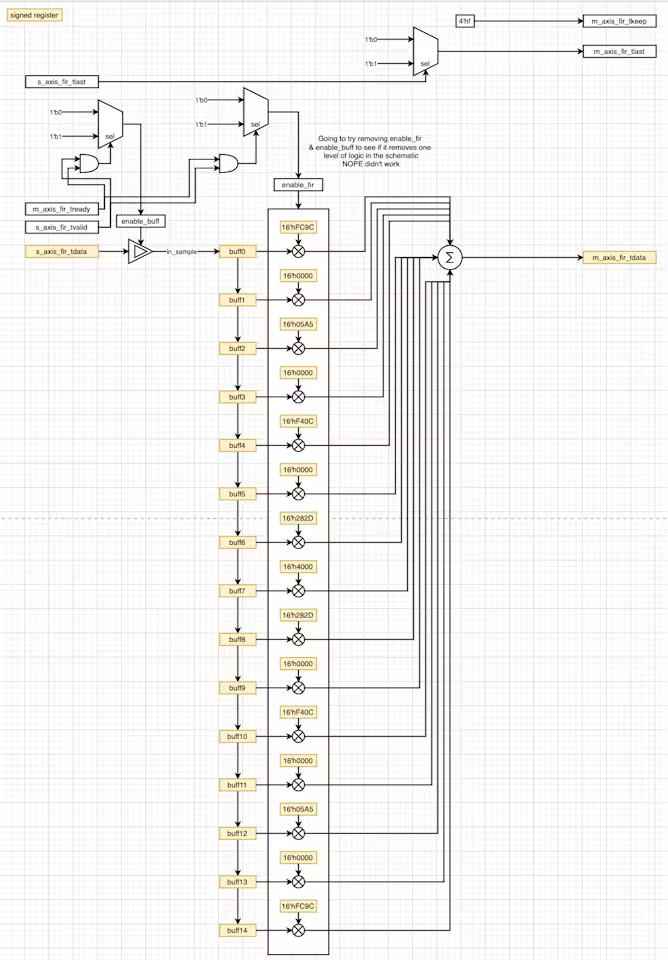
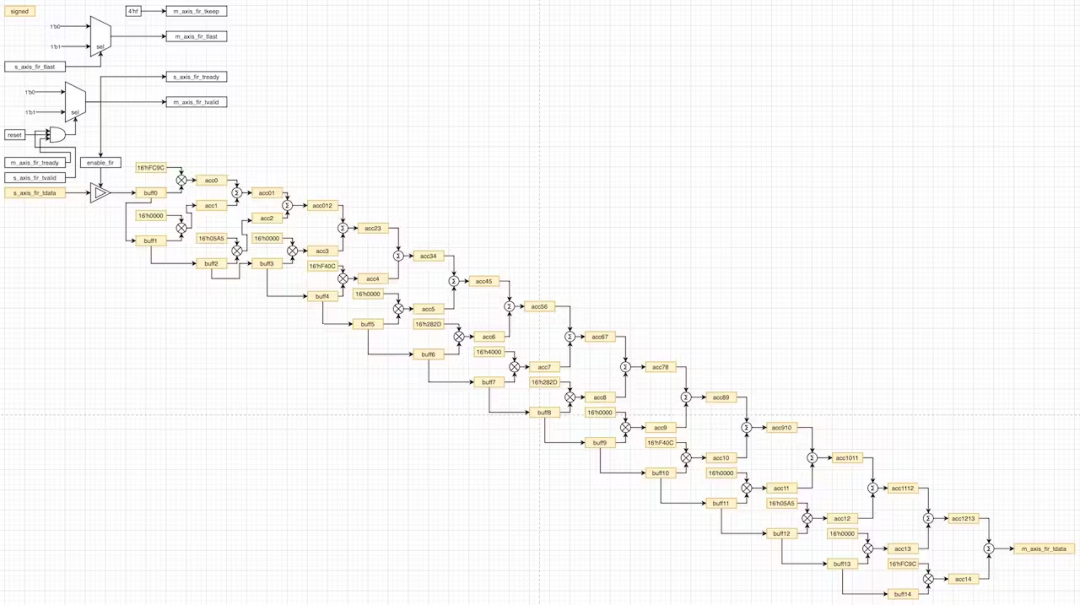
核心的想法是尝试填充循环缓冲区,将每个缓冲区乘以适当的系数,最后一次性对 15 个算子的每一个求和,但是这次我们考虑重新设计逻辑,让循环缓冲区中仅花费乘法和累加(求和)两个寄存器一个级联的时间。
新 FIR 模块的 Verilog 代码:
`timescale 1ns / 1ps module FIR( input clk, input reset, input signed [15:0] s_axis_fir_tdata, input [3:0] s_axis_fir_tkeep, input s_axis_fir_tlast, input s_axis_fir_tvalid, input m_axis_fir_tready, output reg m_axis_fir_tvalid, output reg s_axis_fir_tready, output reg m_axis_fir_tlast, output reg [3:0] m_axis_fir_tkeep, output reg signed [31:0] m_axis_fir_tdata ); /* This loop controls tkeep signal on AXI Stream interface */ always @ (posedge clk) begin m_axis_fir_tkeep <= 4'hf; end /* This loop controls tlast signal on AXI Stream interface */ always @ (posedge clk) begin if (s_axis_fir_tlast == 1'b1) begin m_axis_fir_tlast <= 1'b1; end else begin m_axis_fir_tlast <= 1'b0; end end // 15-tap FIR reg enable_fir; reg signed [15:0] buff0, buff1, buff2, buff3, buff4, buff5, buff6, buff7, buff8, buff9, buff10, buff11, buff12, buff13, buff14; wire signed [15:0] tap0, tap1, tap2, tap3, tap4, tap5, tap6, tap7, tap8, tap9, tap10, tap11, tap12, tap13, tap14; reg signed [31:0] acc0, acc1, acc2, acc3, acc4, acc5, acc6, acc7, acc8, acc9, acc10, acc11, acc12, acc13, acc14; /* Taps for LPF running @ 1MSps */ assign tap0 = 16'hFC9C; // twos(-0.0265 * 32768) = 0xFC9C assign tap1 = 16'h0000; // 0 assign tap2 = 16'h05A5; // 0.0441 * 32768 = 1445.0688 = 1445 = 0x05A5 assign tap3 = 16'h0000; // 0 assign tap4 = 16'hF40C; // twos(-0.0934 * 32768) = 0xF40C assign tap5 = 16'h0000; // 0 assign tap6 = 16'h282D; // 0.3139 * 32768 = 10285.8752 = 10285 = 0x282D assign tap7 = 16'h4000; // 0.5000 * 32768 = 16384 = 0x4000 assign tap8 = 16'h282D; // 0.3139 * 32768 = 10285.8752 = 10285 = 0x282D assign tap9 = 16'h0000; // 0 assign tap10 = 16'hF40C; // twos(-0.0934 * 32768) = 0xF40C assign tap11 = 16'h0000; // 0 assign tap12 = 16'h05A5; // 0.0441 * 32768 = 1445.0688 = 1445 = 0x05A5 assign tap13 = 16'h0000; // 0 assign tap14 = 16'hFC9C; // twos(-0.0265 * 32768) = 0xFC9C /* This loop controls tready & tvalid signals on AXI Stream interface */ always @ (posedge clk) begin if(reset == 1'b0 || m_axis_fir_tready == 1'b0 || s_axis_fir_tvalid == 1'b0) begin enable_fir <= 1'b0; s_axis_fir_tready <= 1'b0; m_axis_fir_tvalid <= 1'b0; end else begin enable_fir <= 1'b1; s_axis_fir_tready <= 1'b1; m_axis_fir_tvalid <= 1'b1; end end reg [3:0] cnt; reg signed [31:0] acc01, acc012, acc23, acc34, acc45, acc56, acc67, acc78, acc89, acc910, acc1011, acc1112, acc1213; /* Circular buffer w/ Multiply & Accumulate stages of FIR */ always @ (posedge clk or posedge reset) begin if (reset == 1'b0) begin m_axis_fir_tdata <= 32'd0; end else if (enable_fir == 1'b1) begin buff0 <= s_axis_fir_tdata; acc0 <= tap0 * buff0; buff1 <= buff0; acc1 <= tap1 * buff1; acc01 <= acc0 + acc1; buff2 <= buff1; acc2 <= tap2 * buff2; acc012 <= acc01 + acc2; buff3 <= buff2; acc3 <= tap3 * buff3; acc23 <= acc012 + acc3; buff4 <= buff3; acc4 <= tap4 * buff4; acc34 <= acc23 + acc4; buff5 <= buff4; acc5 <= tap5 * buff5; acc45 <= acc34 + acc5; buff6 <= buff5; acc6 <= tap6 * buff6; acc56 <= acc45 + acc6; buff7 <= buff6; acc7 <= tap7 * buff7; acc67 <= acc56 + acc7; buff8 <= buff7; acc8 <= tap8 * buff8; acc78 <= acc67 + acc8; buff9 <= buff8; acc9 <= tap9 * buff9; acc89 <= acc78 + acc9; buff10 <= buff9; acc10 <= tap10 * buff10; acc910 <= acc89 + acc10; buff11 <= buff10; acc11 <= tap11 * buff11; acc1011 <= acc910 + acc11; buff12 <= buff11; acc12 <= tap12 * buff12; acc1112 <= acc1011 + acc12; buff13 <= buff12; acc13 <= tap13 * buff13; acc1213 <= acc1112 + acc13; buff14 <= buff13; acc14 <= tap14 * buff14; m_axis_fir_tdata <= acc1213 + acc14; end end endmodule
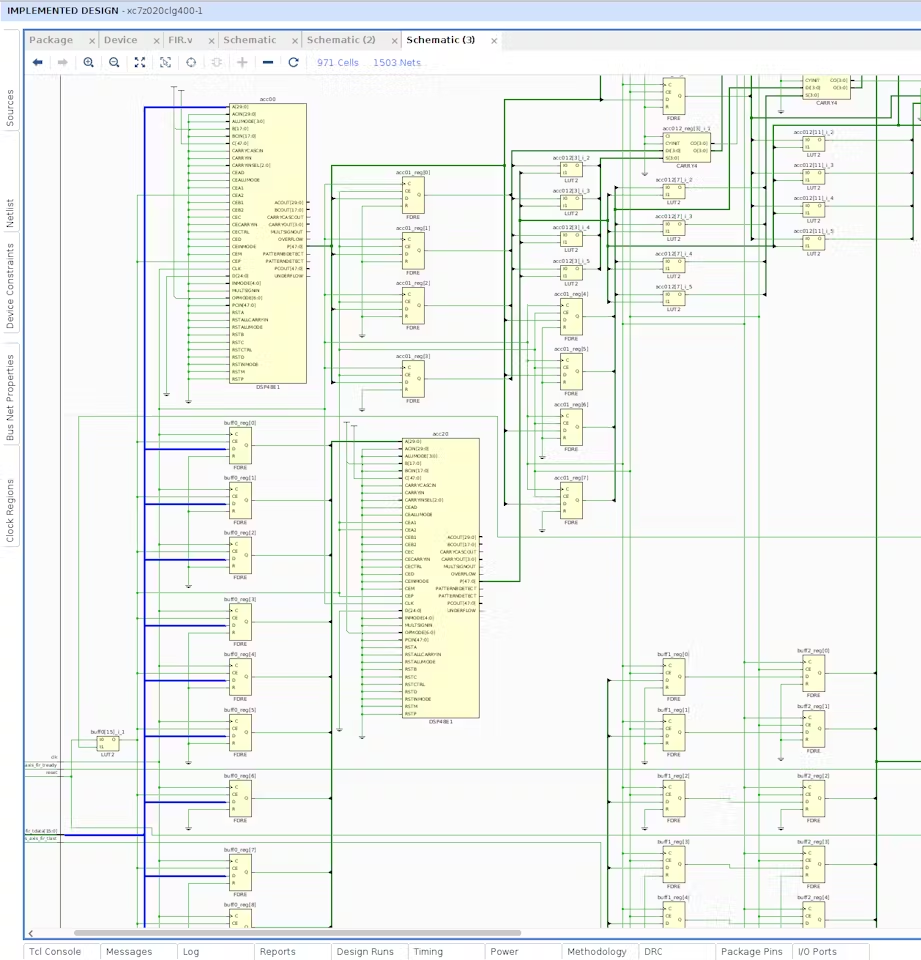
使用新 FIR 模块的 Verilog 代码重新运行综合布局布线后就可以产生满足所有时序要求的设计。打开之前违反建立时序的相同数据信号路径的原理图,可以直观地证明信号路径是如何整体缩短的。
新原理图显示axis_fir_tdata总线中每个位的信号路径都被并行处理,有效地缩短了它们到达目标寄存器的时间,这就是减少信号建立时间的原因。
当新设计满足时序要求时,接下来就是验证重写后的逻辑是否仍然与旧逻辑一样。重新运行行为仿真将很快回答这个问题。
由于希望用新代码替换之前的逻辑,发现设置断点并在更新波形图时单步执行 Verilog 的每一行的功能可以实现我们的目的。
启动行为仿真后,会注意到 HDL 的每条有效行的行号右侧都有一个红色圆圈。单击这些红色圆圈之一将启用该行上的断点。
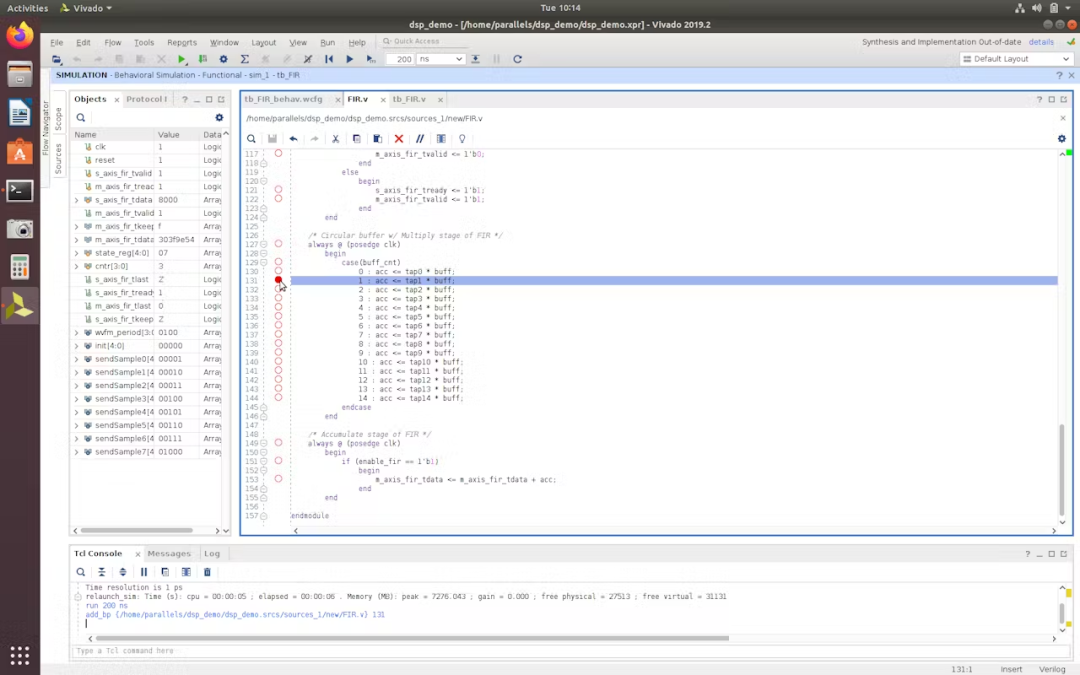
当仿真运行并遇到该断点时,可以使用顶部工具栏中的“步进”按钮(如下所示)或 F8 来逐步执行剩余的代码行。
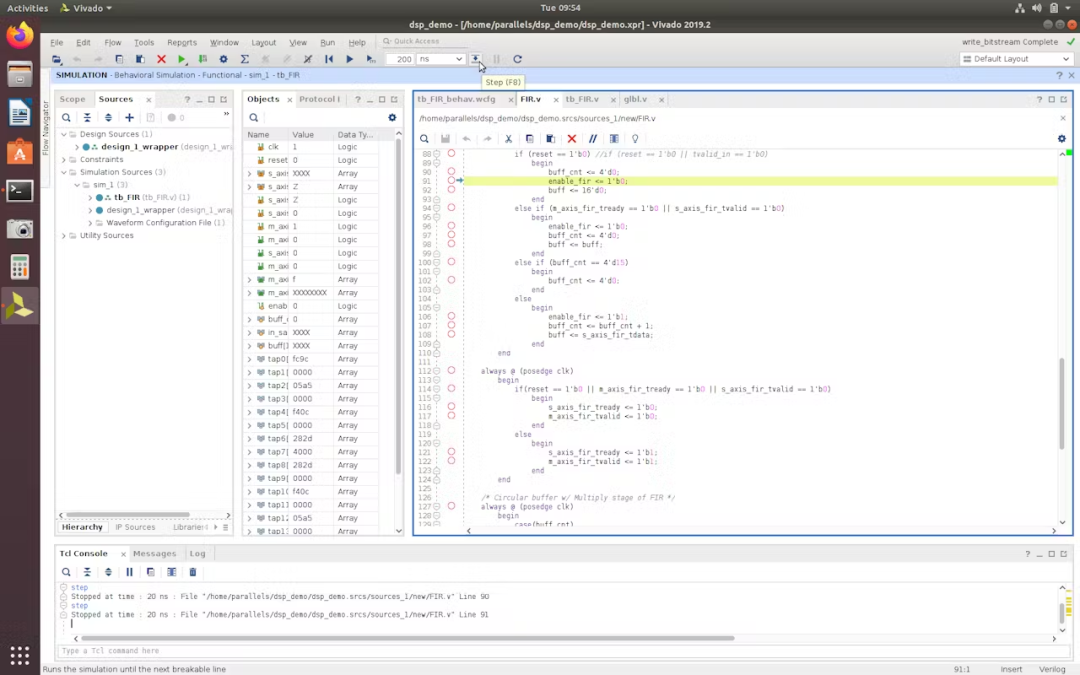
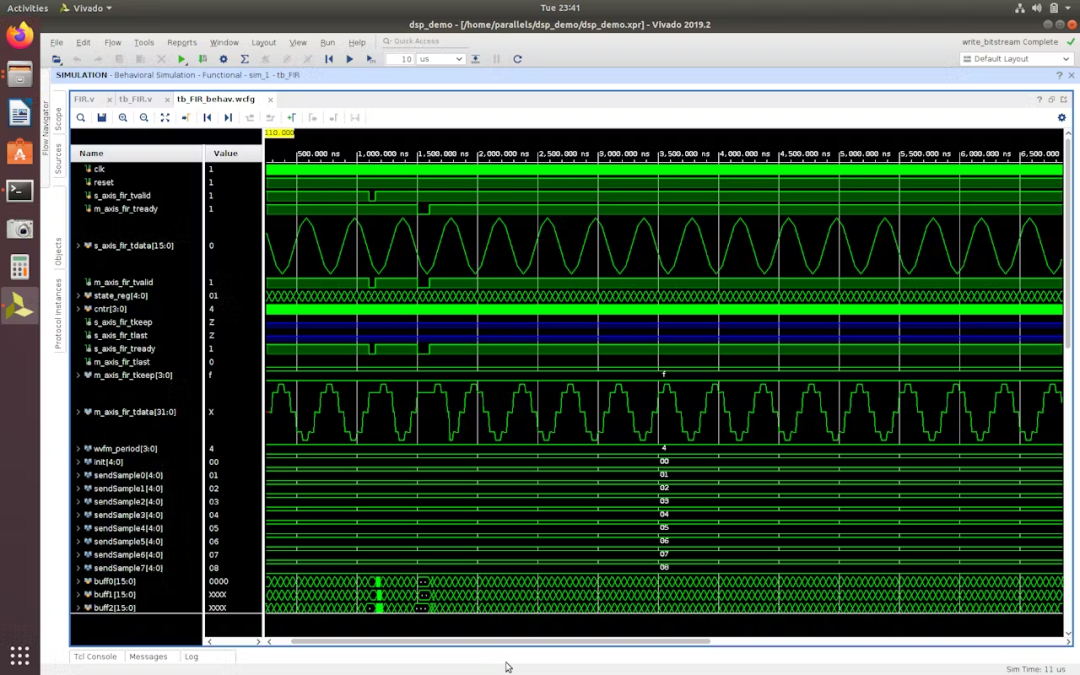
最后,我们看到 FIR 滤波器的新逻辑设计确实按预期运行!
总结
上面的两个例子能证明在目标 FPGA 芯片上,最终输出相同结果的两种不同的 HDL 编写方式对时序影响不同的重要性。这就是为什么在编写代码脑中“有电路”是很重要的原因。
审核编辑:汤梓红
-
进群免费领FPGA学习资料!数字信号处理、傅里叶变换与FPGA开发等2025-04-07 15352
-
FPGA的数字信号处理:重写FIR逻辑以满足时序要求2023-06-20 1207
-
数字信号处理的FPGA实现.第3版英文2021-10-18 1137
-
如何设计一个脉动阵列结构的FIR滤波器?2021-04-20 2095
-
如何使用FPGA实现数字信号处理算法的研究2021-02-01 1522
-
基于FPGA的数字信号处理2020-04-04 2443
-
利用FPGA怎么实现数字信号处理?2019-10-17 6415
-
数字信号处理的FPGA实现2015-12-23 1091
-
基于FPGA数字信号处理2015-10-30 1174
-
FPGA在数字信号处理中的简单应用2015-02-02 9108
-
【参考书籍】基于FPGA的数字信号处理——高亚军著2012-04-24 14046
-
数字信号处理的FPGA实现_刘凌译2011-11-04 878
全部0条评论

快来发表一下你的评论吧 !
