

后摩尔时代的Chiplet D2D解决方案
描述
摘要:在后摩尔时代,集成电路设计理念正向Chiplet架构转变。本文从D2D接口IP设计,D2D封装和D2D测试三个方面介绍了Chiplet D2D的解决方案,并给出了采用此解决方案的XSR 112G D2D的测试结果。
1.后摩尔时代向Chiplet的战略转变
当前摩尔定律逐步趋向物理极限,半导体行业正在发生重大的战略转变。基于Chiplet架构的芯片设计理念逐渐成为行业主流。这一战略转变的驱动因素主要有以下几种:
1)单芯片的尺寸变得太大,无法制造;
2)充分利用已有KGD(Known Good Die)芯片实现复杂功能芯片,可以减少设计周期和成本,并提高良率。
在这些驱动因素下,整个Chiplet行业在2031年有望达到471.9亿美元[1],如图1所示,Chiplet市场在2021~2031十年期年复合增长率保持36.4%;其中实现Die to Die(D2D)互连的接口IP市场在2026达到3.24亿美元[2],D2D IP市场在2021~2026五年期年复合增长率高达50%,如下图2所示。
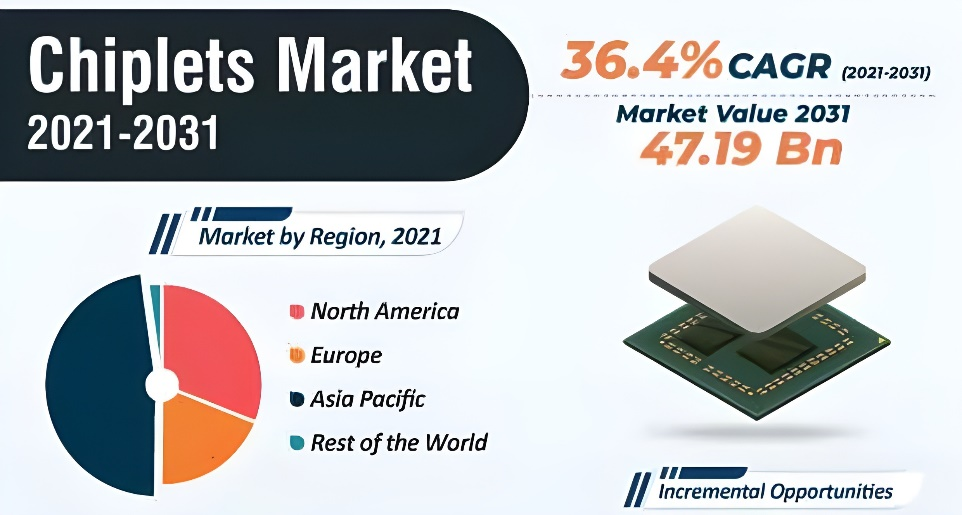
图1 Chiplet市场
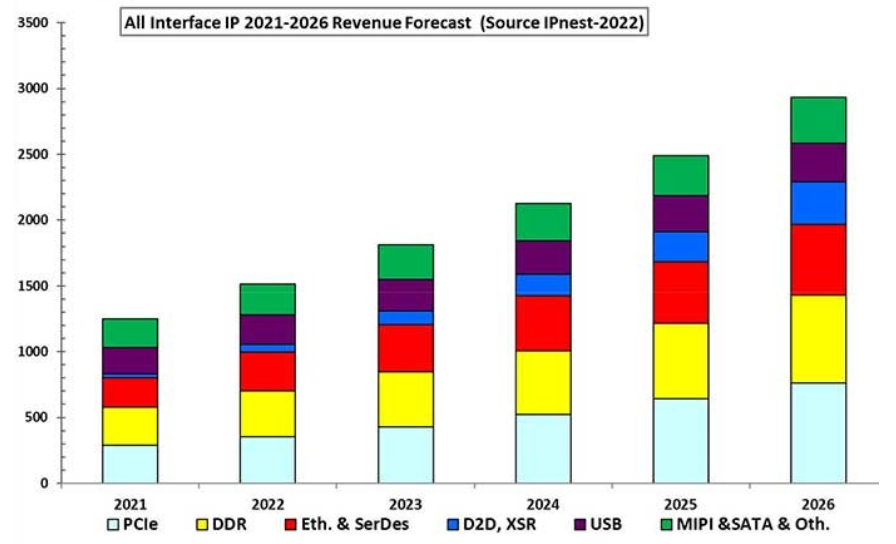
图2 D2D IP市场趋势
Chiplet应用场景主要分两种,第一种是将同工艺大芯片分割成多个小芯片,然后通过接口IP互连在一起实现算力堆叠;第二种是将不同工艺不同功能的芯片通过接口IP互连并封装在一起实现异构集成,如图3所示。算力堆叠主要应用于CPU、TPU和AI芯片等,对接口IP的要求是低延迟和低误码率,通常采用并行接口IP。异构集成,主要应用于CPU、FPGA和通信芯片等,对接口IP的要求是标准化,兼容性,可移植性和生态系统等,通常采用串行接口IP。
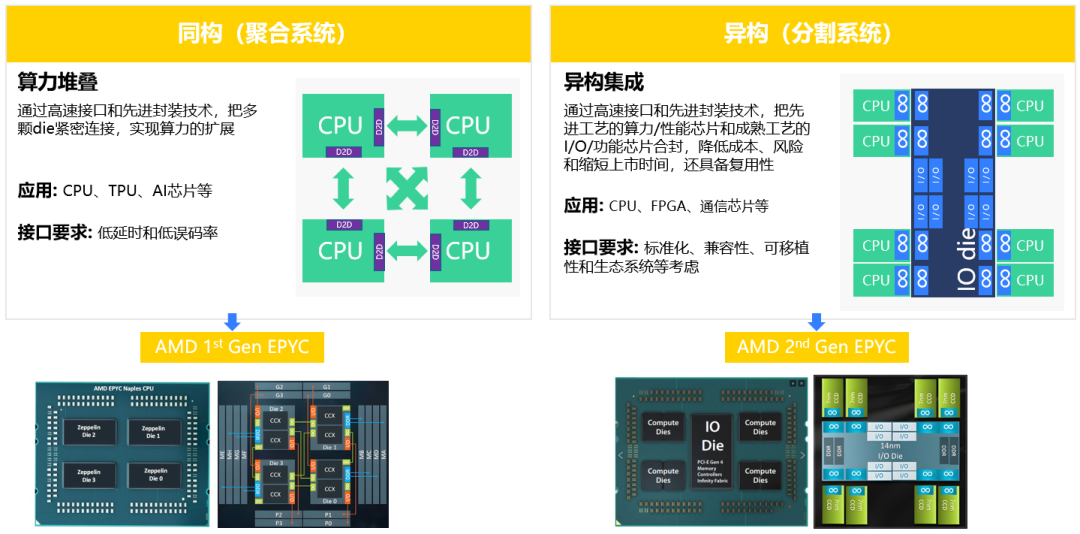
图3 典型应用场景
为了便于组装不同供应商开发的芯粒,需要标准化的芯粒间互连标准,行业联盟已共同定义出多种芯粒互连标准,如XSR,BoW,OpenHBI,UCIe等。它们的主要性能指标如图4所示。其中,XSR采用差分串行结构,目前最高速率达112Gbps,可用于异构集成连接IO die;后3种采用单端并行结构,目前最高速率是UCIe的32Gbps, 同时它还定义了完整的协议层,继承了CXL和PCIe的生态优势,可用于算力堆叠中计算IP间的互连。
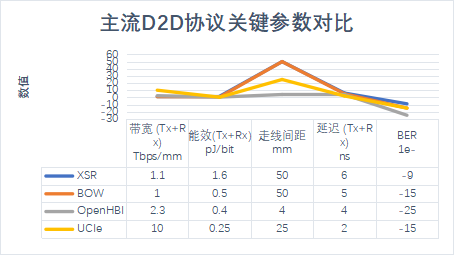
图4 主流D2D的关键指标
完整的D2D解决方案包括:D2D接口IP设计、D2D封装设计和D2D测试,下面分别做详细介绍。
2.D2D接口IP设计解决方案
D2D接口IP由物理层(PHY)和控制器组成,如下图5所示。物理层PHY是封装介质的电气接口。从分层结构上分为模拟PHY和数字PHY,模拟PHY包括电气AFE(发射器、接收器)以及边带信道,可实现两个晶粒之间的参数交换和协商。数字PHY包括链路初始化、训练和校准算法以及测试和修复功能。从接口类型上分并行接口和串行接口。
控制器由链路层(Link layer)和逻辑物理层(Physical Layer Logical)。链路层负责上层协议接口适配,协议仲裁和协商,以及基于 CRC,可选的FEC(Forward Error Correction)和重传机制来确保链路可靠地传输数据;逻辑物理层负责链路训练和管理功能以及具体的PHY适配(比如加扰,解扰,块对齐,OS插入和提取等)。在链路初始化时,逻辑物理层会等待 PHY 完成链路初始化,通过链路状态机进入工作模式。链路层会通过协商确定使用哪个协议(如果实施了多个协议)。控制器向上支持CXS、AXI、FDI(Filt aware D2D interface)接口来支持PCIe、CXL、UCIe以及SOC和RAW协议层;向下兼容RDI(Raw D2D interface)和PIPE接口来适配不同的物理电气层[3][4][5]。
下面分别介绍一下并口和串口的D2D PHY架构。
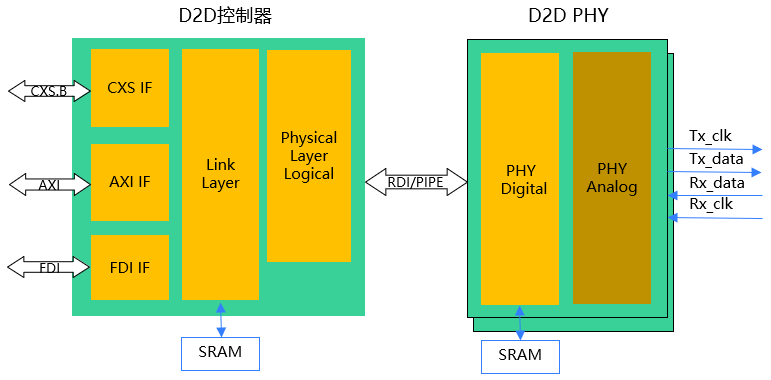
图5 D2D分层架构
2.1 并口D2D PHY架构
为了满足低延迟,高能效,低误码率要求,物理层接口采用单端并口传输,使用2.5D封装形式。并口D2D物理层结构如图6所示:
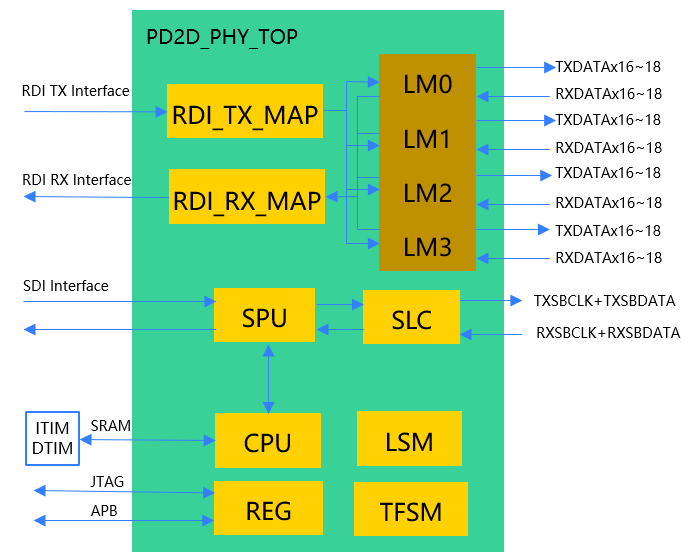
图6 并口D2D PHY系统框架
并口物理层模拟部分包括4个LM(Lane module),每个LM数据位宽为单向16bit,共64bit。可以根据所需带宽灵活配置LM数目。每个LM还可以配置1~2个Slicer用于Filt Header或CRC校验。每Lane具备高精度和高解析度自校准延迟线,RX线性连续时间均衡器(CTLE)和DFE均衡器以实现高速性能,并根据走线长度可关闭DFE均衡器,以降低功耗。
并口物理层数字部分包括的功能块有RDI_TX/RX_MAP实现RDI接口到LM的映射;SPU(Sideband Process Unit)/TFSM(Train FSM)/LSM(Link SM)实现PHY启动,Lane修复/反转,TX/RX训练,VREF训练,眼图训练,自适应,链路状态管理,链路双方配置等功能。
芯耀辉实现的并口物理层采用DDR模式传输数据,数据率为16Gbps,符合UCIe和CCITA发布的《小芯片接口总线技术要求》标准;使用Forward clock模式简化接收端设计,可以减小延迟,降低功耗;延迟时间从本端FDI到对端FDI小于2ns;能效0.5~1pJ/bit。
2.2串口D2D PHY架构
为了满足高带宽,较长距传输,较低封装成本的要求,物理层接口采用差分串口传输,使用2D substrate封装形式。串口D2D物理层结构如下图7所示:
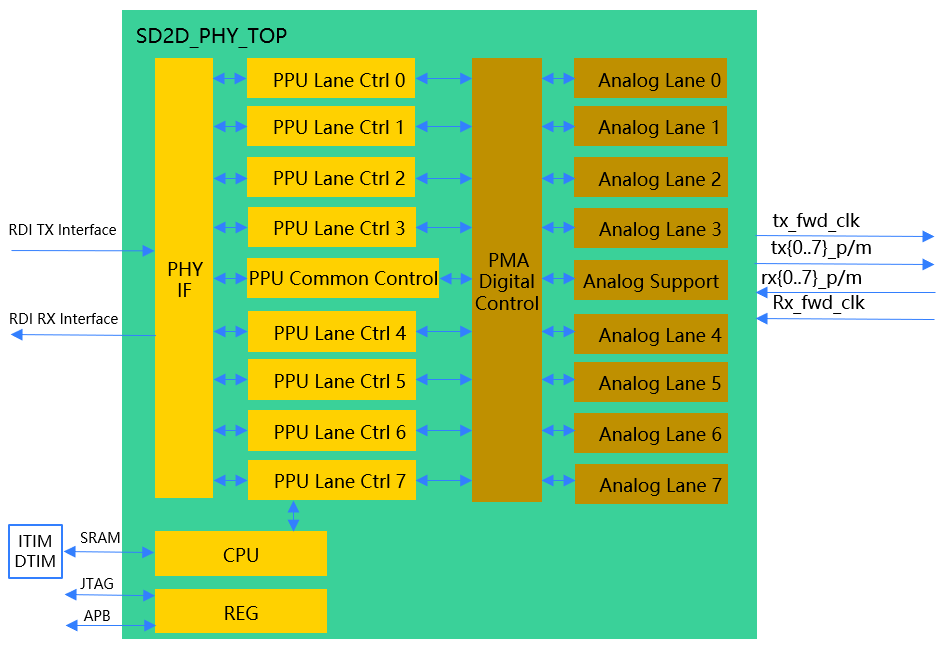
图7 串口D2D PHY架构
串口物理层模拟部分包括8通道Analog Lane,每通道由TX和RX组成,可实现双向8通道全双工差分信号传输,兼容NRZ和PAM4信令,数据率覆盖2.5~112Gbps[6]。为适应较差的信道,TX采用3 Taps FFE均衡器,RX采用线性均衡器。为了优化延迟,时钟架构可采用Forward clock架构。为了优化功耗,每个通道可独立开关,独立运行。
串口物理层数字部分包括PMA Digital Control和PHY处理单元(PPU)。主要实现PHY上下电时序控制;上电时TX/RX校准、自适应算法及顺序控制;正常运行时,实时自适应校准;内建测试逻辑控制等功能。
芯耀辉实现的串口物理层兼容CEI-112G-XSR协议,最高速率达112Gbps,可均衡通道损耗达-10dB,带宽线密度约1Tbps/mm,能效1.5pJ/bit,延迟时间小于6ns,误码率小于1e-15。
3.D2D封装方案
适合D2D的封装类型包括传统的2D有机基板(Substrate),先进2.5D封装(RDL Fanout和Silicon Interposer)及3D封装(Hybrid Bonding)。具体选用那种封装类型,需综合考虑IO数量,IO密度,数据率,成本,复杂度和接口类型等因素,如图8所示[7]。通常对于高速串行接口,数据率越高,IO数量越少,IO密度越低,复杂度和成本也越低,建议采用2D或者RDL Fanout 2.5D封装类型。对于高密度并行接口,数据率越低,IO数量越多,IO密度越高,复杂度和成本也越高,建议采用2.5D或者3D封装类型。
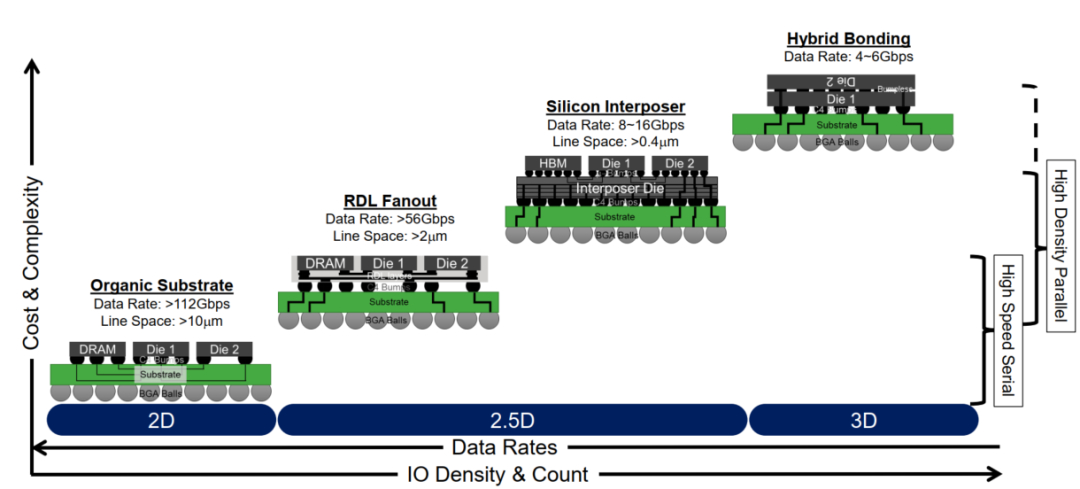
图8 D2D封装类型选择
考虑到出Pin密度,电源Drop,信号完整性,减小基板层数,降低成本等因素。Bump map和互连走线采用如图9所示结构[2]。图中TX信号bump和RX信号bump分开单独放一起,可以方便对端Die的互连,减小走线间Cross talk;两个Die之间bump采用相隔近的与相隔近的互连,相隔远的与相隔远的互连,可以减少基板叠层,减小信号走线间交叠,从而减少成本,提高信号完整性。但这样会造成线与线间延迟时间的轻微差别,可以通过Die内Deskew功能去除。从信号完整性角度来看,还需要考虑Bump阻抗不连续,Via阻抗不连续,走线阻抗不连续和噪声耦合等问题。
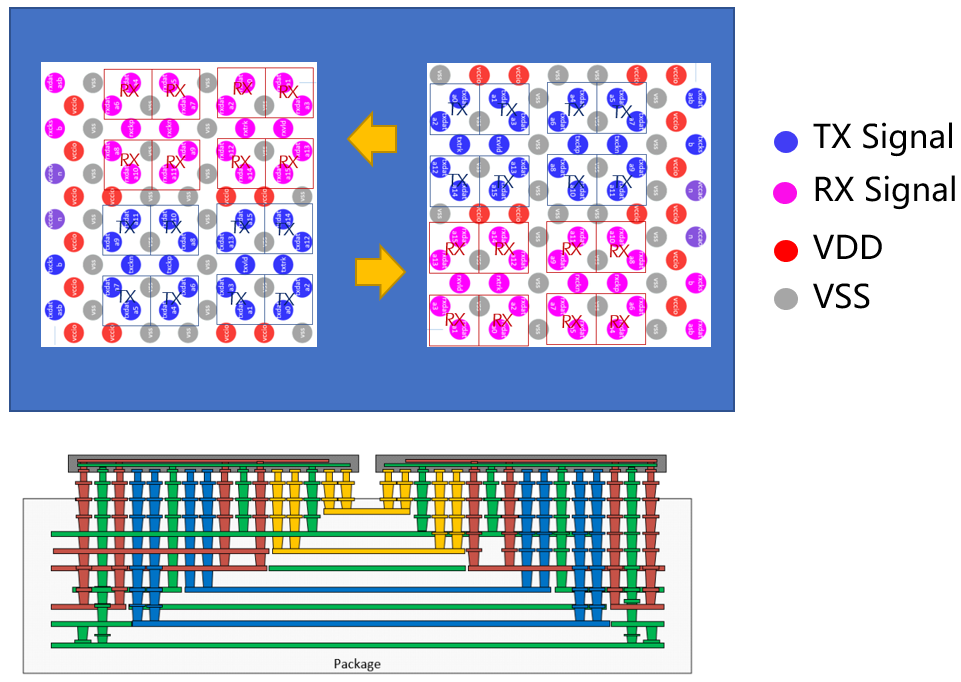
图9 Bump map方案
封装设计好后,需要抽取S参数,并利用IBIS-AMI模型验证信号质量。能建模IBIS-AMI并验证走线S参数的工具有很多,它们中大部分都提供了自动化IBIS-AMI建模流程,可以基于图形界面设计[8]。如图10和图11所示,用户可以使用软件内建的常用算法模型,来快速对TX的FFE去加重预加重均衡和模拟输出(AnalogOut)以及RX的模拟输入(AnalogIn),CTLE连续时间线性均衡,AGC自动增益放大, DFE自适应判决反馈均衡和CDR时钟恢复等进行建模,既可设置为NRZ模式也可设置为PAM4模式,而且内建的Channel模型可以很方便调用Touchstone格式的通道S参数。
图10中,Channel调用的通道S参数为-10dB@28GHz;TX设置为NRZ模式,数据率为56Gbps,摆幅为500mV,输入信号为PRBS31,FFE均衡不使能;RX 设置CTLE gain-boost从0dB到-10dB,AGC增益设置为1,DFE不使能,CDR使能。仿真得到的眼高175mV,眼宽15.76ps,COM为15.7dB。图11中,将设置改为PAM4模式,数据率为112Gbps,输入信号为QPRBS13,其它不变的情况下。仿真得到的眼图的三个眼高基本一致为40mV,眼的线性度RLM为99.8%。
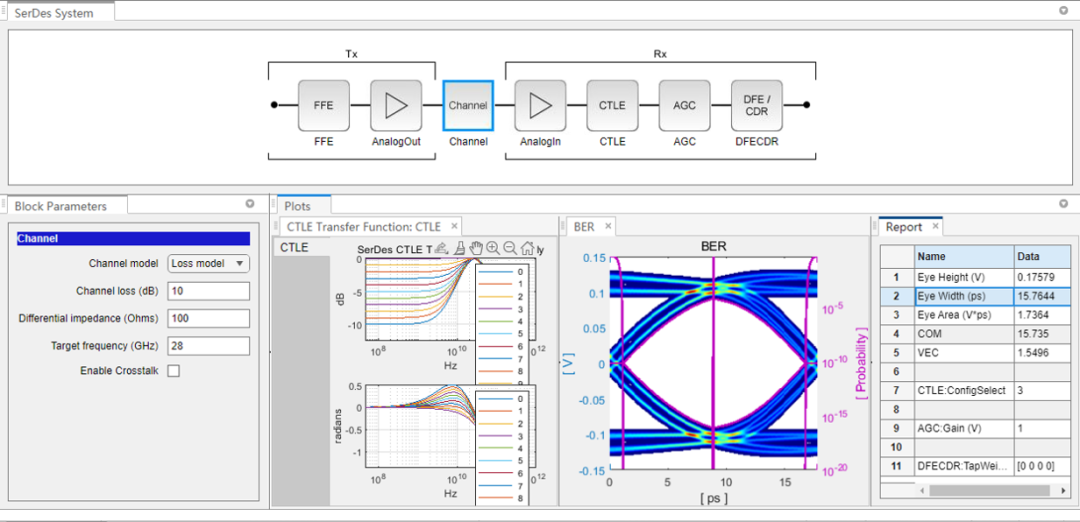
图10
用IBIS-AMI模型进行NRZ信号通道分析
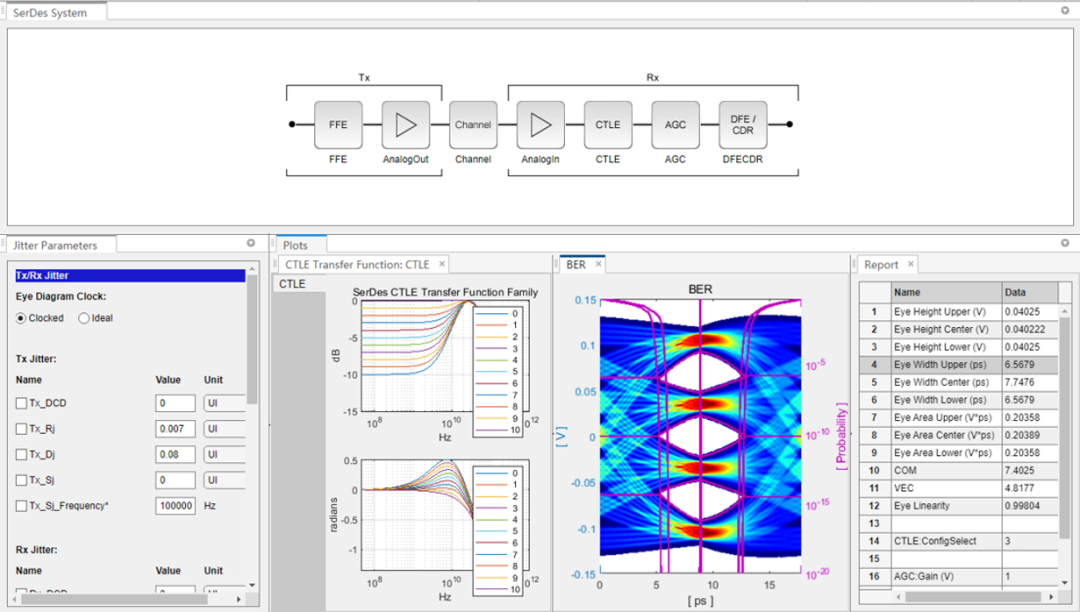
图11
用IBIS-AMI模型进行PAM4信号通道分析
4.D2D测试方案
以串口D2D为例。为了全面测试和debug数据链路,D2D接口IP在设计时,需考虑全面的环回测试路径,如图12所示。数据通路测试路径包括:数字侧近端环回路径A:本端数字部分内环测试;模拟侧近端环回路径B:本端模拟部分内环测试;模拟侧远端环回路径C:对端模拟部分外环测试;数字侧远端环回路径D:对端数字部分外环测试。时钟通路测试路径包括:时钟近端环回路径E:本端发送时钟至接收时钟的环回测试;时钟远端环回路径F:对端接收时钟至发送时钟的环回测试。
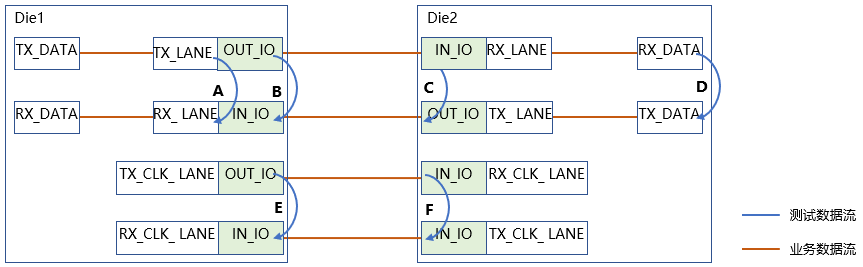
图12 环回测试模式
由于D2D高速引脚一般封装在Package内,不引出。这样对D2D IP的测试造成了一定的不方便。因此,测试方案和Package设计都需要特殊考虑。如图13所示[9][10],测试需要2个Die(Octal Macro)实现TX到RX的环回测试。为了验证D2D IP能过不同的通道损耗,通道损耗设计为1dB~10dB@28GHz。为了真实测试出D2D IP的性能,需要对从PCB连接器处到封装基板的走线做去嵌处理。
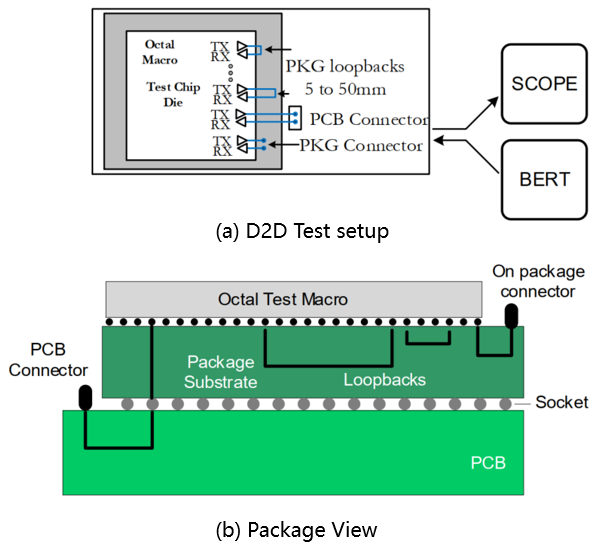
图13
D2D test setup and package view
采用以上测试方案,通道损耗为-10dB@28GHz时,芯耀辉设计的112G 串口D2D 样片TX输出的测试结果如图14所示。图中56G-NRZ测试采用PRBS31码型,眼高为363mV,Rj为345fs(rms);56G-PAM4测试采用QPRBS13码型,三个眼高从上到下分别为224.6mV,235.6mV,229.0mV,RLM=97.7%;112G-PAM4测试采用QPRBS13码型,三个眼高从上到下分别为为99mV,109.2mV,97mV,RLM=95.3%。测试结果满足CEI-112G-XSR协议要求。

图14 XSR D2D TX测试结果
5.结束语
多晶粒Chiplet已成为芯片设计行业主流系统方案,D2D接口规范为设计人员带来了极具竞争力的性能优势,包括高能效 (pJ/b),高带宽线密度 (Tbps/mm) 和低延迟 (ns),支持主流IO协议以及任何用户定义的协议,支持多种封装类型。本文从接口IP设计到封装设计再到测试方案,详细介绍了Chiplet D2D解决方案。参照此方案可轻松实现多晶粒系统互连。
2022年4月,芯耀辉作为首批会员加入了UCIe组织,推出支持UCIe协议且兼容多样化D2D和C2C场景的“并口D2D PHY IP”以及高能效比和高宽带利用率的“串口112G D2D SerDes PHY IP”的完整D2D解决方案,如图15所示。同年10月,芯耀辉承接了国家科技部重点研发专项,作为国家队成员着力推动国内Chiplet标准CCITA的产业化落地。公司一直专注于高速接口IP领域,积累了丰富的经验和技术能力,已经为客户提供了5G、数据中心、网络交换机等相关芯片IP产品,率先实现了市场客户的量产。随着产业进一步的发展,以及相关的下游的封装等一些技术的成熟,Chiplet在国内的发展前景可期。
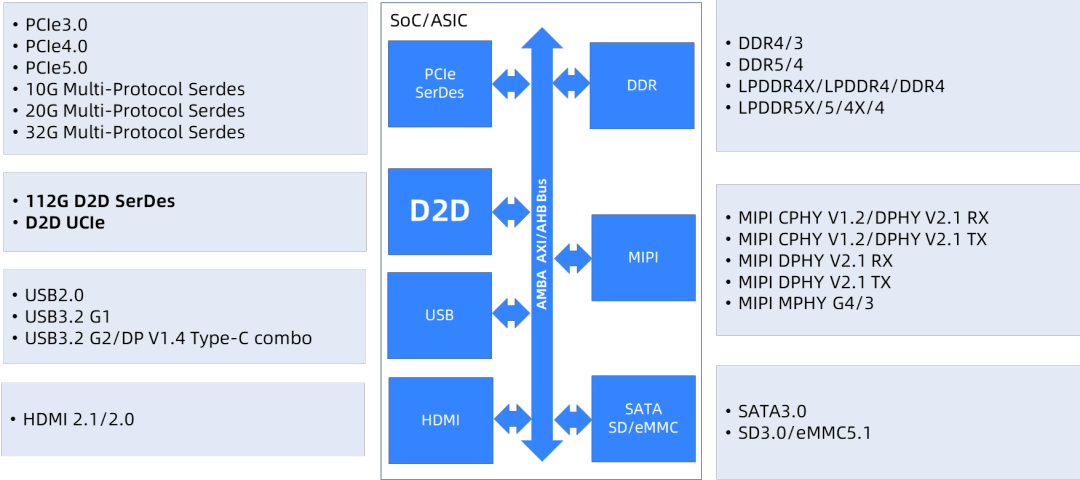
图15 芯耀辉完整IP解决方案
-
韬定律:后摩尔时代走向“时间缩微”,光互联与SOA的新可能性2026-05-28 181
-
根据“后摩尔时代”芯片行业如何发展?2017-06-27 6008
-
IC在后摩尔时代的挑战和机遇2010-02-21 1567
-
聚焦MWC 2016:TCL通讯展示D2D解决方案2016-02-23 1304
-
蜂窝网络中支持全双工D2D通信的资源分配算法2017-01-07 1051
-
基于公平性的D2D时隙调度算法2017-12-05 1115
-
基于优先级的D2D中继方案2018-01-25 1362
-
后摩尔时代集成电路产业特性及发展趋势2021-01-10 11515
-
聚焦后摩尔时代,后摩尔时代集成电路产业如何突破2022-04-08 2365
-
全球首个符合ASIL-D的车规级Chiplet D2D互连IP流片2023-06-15 1143
-
Chiplet关键技术与挑战2023-07-17 2606
-
后摩尔时代芯片互连新材料及工艺革新2023-08-25 1870
-
奇异摩尔与智原科技联合发布 2.5D/3DIC整体解决方案2023-11-12 2396
-
Chiplet与3D封装技术:后摩尔时代的芯片革命与屹立芯创的良率保障2025-07-29 1856
-
华大九天推出芯粒(Chiplet)与2.5D/3D先进封装版图设计解决方案Empyrean Storm2025-08-07 5319
全部0条评论

快来发表一下你的评论吧 !
