

首个国内《芯粒互联接口标准》Chiplet接口测试成功
接口/总线/驱动
描述
近日,北极雄芯宣布自主研发的首个基于国内《芯粒互联接口标准》的Chiplet互联接口PBLink回片测试成功。PBLink接口具备低成本、低延时、高带宽、高可靠、符合国产接口标准、兼容封装内外互连、注重国产自主可控等特点。
接口采用12nm工艺制造,每个D2D单元为8通道设计,合计提供高达256Gb/s的传输带宽,可采用更少的封装互连线以降低对封装的要求,最少仅需要3层基板进行2D互连;基于专门优化的精简协议层和物理层,可实现ns级别的端到端延迟,各项指标符合《芯粒互联接口标准》要求及设计预期;此外,PB Link可灵活支持封装内Chiplet – Chiplet互联以及10-15cm的封装外板级Chip – Chip互联,灵活适配各类下游应用场景需求。公司率先推出的是基于传统封装(153μm Standard Package)的芯粒解决方案,并预计在2024~2025年推出针对超高性能场景的高密度互连版本(55μm InFO Package)。

图1 北极雄芯256Gb/s带宽的
D2D测试片回片测试成功
北极雄芯专注于为客户提供基于Chiplet的定制化高性能计算解决方案,公司于2023年初发布了国内首款基于Chiplet异构集成的人工智能计算芯片“启明930”,并持续投入各类通用型HUB Chiplet,功能型Chiplet以及高速芯粒互联接口的研发。本次回片测试成功的PBLink将用于公司下一代核心HUB Chiplet以及部分功能型Chiplet上,预计于2024年内实现整体量产。
Chiplet(芯粒技术) – 后摩尔时代的行业演进方向
过去半个世纪,摩尔定律下的工艺进步在不断推动半导体产业的发展,促使电路频率以及晶体管密度不断提升,芯片的性能密度不断增加。而近年来,随着工艺迭代逐渐进入瓶颈期,集成电路的发展进入“后摩尔时代”,单位面积硅片下晶体管集成密度无法进一步压缩,而通过增加单芯片面积来提升性能又面临显著的“面积墙”以及一系列的良率、成本等问题。从全球半导体产业发展趋势来看,5nm及以下更先进工艺的投入产出比在商业可行性上面临诸多挑战,而在当前国际形势和自主可控的供应链边界能力下,国内半导体产业甚至在12nm工艺节点即须直面芯片性能如何进一步提升的问题。
在摩尔定律逐步失效的背景下下,Chiplet(芯粒技术)逐步成为行业共识的演进方向。通过将多芯片在封装内互联的方式实现性能扩展或系统级的功能的集成,不但可有效解决大面积芯片面临的良率低、量产成本高等问题,亦可面向不同场景需求提供灵活的组合。近年来,海内外知名半导体企业均基于自身产品场景需求,采用不同的Chiplet集成方式推出了新一代芯片,例如基于2块或多块相同芯片进行高性能合封的AMD Zen1、Apple M1/2 Ultra、Intel Sapphire Rapids,或基于异构模块集成的AMD Zen4、AMD MI300、Intel Ponte Vecchio、华为昇腾等。
芯粒互联接口(D2D) – Chiplet集成的关键技术
Chiplet集成能够极大程度上优化高性能计算芯片的商业落地可行性,但从技术层面而言,每颗被集成的小芯粒在互联后依然能够达到系统级整体性能要求至关重要,因此在不同场景需求下采用的芯粒互联接口技术(D2D)与Chiplet集成后整体性能密切相关,最终旨在通过封装内的芯粒互联实现“像片上互连一样”的效果,并同时兼顾低成本、低延时、高带宽、高可靠性的需求。
在实际应用领域中,不同场景的数据传输特点带来对所采用接口技术及封装技术的较大需求差异。例如CPU等通用计算场景中,数据传输具有随机性高、数据流结构差异大、缓存一致性要求高等特点,因此在CPU Chiplet集成中往往极为重视对延迟等指标的优化,采用并口传输方案,大规模走线较为依赖先进封装技术的配套支持。在GPGPU等面向服务器领域的通用并行计算场景中,数据传输具有单次量大、数据流结构可预知性高、可提前搬运预载等特点,因此在Chiplet集成中需要重点对带宽等指标进行优化,可采用并口或串口方案,对先进封装亦有较高的依赖。而在特定AI加速场景中,又需综合考虑成本敏感度、作业环境等各方面要求,采用不同的接口技术及封装方案以满足终端用户的差异化的需求:如以智能驾驶领域为例,先进封装方案往往并不满足车规要求,而且量产成本也较高,在采用Chiplet异构集成时往往需考虑在成熟封装方案基础上反过来优化相应的D2D技术。
综上而言,芯粒互联接口的技术路线与其所应用的场景技术需求、成本敏感度、封装供应链完备程度等密切相关,短期内在高性能计算领域很难有统一的接口标准满足各类产品在技术及商业上的需求,设计公司往往需要根据不同场景的差异化需求开发不同的D2D接口方案,例如Apple用于M1/M2 Ultra的UltraFusion技术、NVIDIA的NVLink技术等均为根据自身产品使用场景优化的D2D接口方案。
《芯粒互联接口标准》(ACC) – 基于国产供应链优化的互联标准
在当前国际形势下,国内半导体产业在高性能计算领域的产业化落地除了考虑不同场景技术层面的需求外,量产供应链的稳定保障亦至关重要。海外高端高性能计算芯片往往能够得到先进封装产业链的支持(如Intel EMIB技术、TSMC CoWoS技术等),国内封装产业在2.5D先进封装技术等方面亦取得了一定成果,但作为关键材料的ABF基板尚需依赖海外供应链,国内基板层数方面相对落后,在系统级较为重视的连接密度、线宽线距、通孔过孔盲孔工艺和毛刺控制方面与一线国际水平相比还有差距。
如何在现有相对落后的制造工艺、尚在发展中的先进封装技术以及相关核心材料供应链的基础上,做出满足性能预期且成本可控的产品,使得Chiplet真正具有商业可行性?
基于上述目标,并立足于国内供应链成熟程度的现状,2023年2月,中国Chiplet产业联盟联合国内系统、IP、封装厂商一起,制定了《芯粒互联接口标准》ACC1.0及《车规级芯粒互联接口标准》ACC_RV 1.0。
该接口标准已经走上国际舞台进行推广。北极雄芯创始人马恺声教授在2023年6月的第50届计算机架构顶级会议ISCA中,受邀参加第三届“高性能芯粒和互连架构国际研讨会HiPChips”,对Chiplet ACC接口进行宣讲。北极雄芯D2D接口对ACC的适配,促进了Chiplet生态共建,为日后生态伙伴的Chiplet单元互连奠定关键基础,并可广泛用于诸如服务器、汽车计算等关键领域。
该标准为高速串口标准,着重基于国内封装及基板供应链进行优化,以成本可控及商业合理性为核心导向。由于总带宽 = 数据线数 × 线速率,在一定带宽下,通过提高线速率即可降低线数,从而降低对封装的需求,实现对国产封装供应链的兼容,为提升国产高性能计算芯片的自主可控度奠定了坚实的基础。
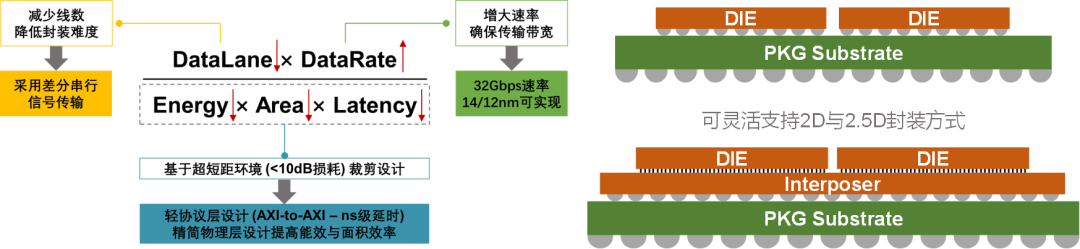
图5 《芯粒互联接口标准》(ACC)的特点
从技术层面,ACC标准作为高速串口标准,适用于固定的、可提前预知的数据流结构多Die封装。若可提前预知数据流结构,便可以提前进行数据搬运。数据对带宽敏感,对延迟敏感的要求,可通过数据预读取、编译进行优化。从应用领域来看,ACC标准更加适用于各类异构计算场景,如各类AI加速产品、GPU、FPGA、多核CPU Die内已经互联后与其他异构模块交互等。
北极雄芯 – 基于Chiplet的定制化高性能计算解决方案提供商
北极雄芯旨在为广大高性能计算场景提供基于Chiplet集成的定制化高性能计算解决方案。在当前国际形势及行业发展趋势下,基于国内具备商业化落地的可行性出发,兼顾场景需求、成本敏感度、国产供应链等各方面的因素,专注于面向自主可控性高的Chiplet技术及产品,关注在14/12nm工艺节点以及国产封装供应链下的可实现性。
公司在Chiplet领域深耕多年,已经率先发布了“启明930”— 国内首个基于Chiplet异构集成人工智能芯片的验证,并向若干下游客户交付了首个隐私安全计算芯粒产品。本次PBLink回片测试成功标志着公司基于国产供应链自主研发的芯粒高速互联接口已经在业内率先实现工艺验证,目前公司正投入研发下一代核心通用型HUB Chiplet以及适用于若干下游场景的功能型芯粒,搭载PBLink的首套量产级别Chiplet方案即将在2024年正式推向市场。
编辑:黄飞
-
IDE接口标准2008-06-30 5601
-
有线耳机接口标准2012-07-03 5981
-
MAC板labview 互联接口2021-08-10 5070
-
JTAG接口标准是什么?2021-12-24 1521
-
北极雄芯开发的首款基于Chiplet异构集成的智能处理芯片“启明930”2023-02-21 1545
-
lvds接口标准2008-07-01 32606
-
IDE接口标准简介2008-07-22 3034
-
AES/EBU接口标准2009-08-01 16467
-
串行通信接口标准2009-09-16 4270
-
DVI接口标准介绍2016-09-06 1835
-
几种串行通信接口标准详解2017-01-03 1576
-
PCI Express接口标准的特点及在FPGA中的应用2021-06-18 4108
-
华邦电子加入UCIe产业联盟,支持标准化高性能chiplet接口2023-02-15 889
-
解说全球电动汽车充电接口标准2024-12-19 6631
全部0条评论

快来发表一下你的评论吧 !
