

芯片封装:向上堆叠,翻越内存墙
EDA/IC设计
描述
本文来自“2023新型算力中心调研报告(2023)”。更多内容参考“《海光CPU+DCU技术研究报告合集(上)》 ”,“《海光CPU+DCU技术研究报告合集(下)》 ”和“龙芯CPU技术研究报告合集”。
积极引入新制程生产 CCD 的 AMD 对 SRAM 成本的感受显然比较深刻,在基 于台积电 5nm 制程的 Zen 4 架构 CCD 中,L2、L3 Cache 占用的面积已经达到整体的约一半比例。

△ Zen4 CCD 的布局,请感受一下 L3 Cache 的面积
向上堆叠,翻越内存墙
AMD 当前架构面临内存性能落后的问题,其原因包括核心数量较多导致的平均每核心的内存带宽偏小、核心与内存的“距离”较远导致延迟偏大、跨 CCD 的带宽过小等。这就促使 AMD 需要用较大规模的 L3 Cache 来弥补访问内存的劣势。而从 Zen 2 到 Zen 4 架构,AMD 每个 CCD 的 L3 Cache 都为 32MB,并没有“与时俱进”。为了解决 SRAM 规模拖后腿的问题,AMD 决定将 SRAM 扩容的机会独立于 CPU 之外。
AMD 在代号 Milan-X 的 EPYC 7003X 系列处理器上应用了第一代 3D V-Cache 技术。这些处理器采用 Zen 3 架构核心,每片 Cache(L3 Cache Die,简称 L3D)为 64MB 容量,面积约 41mm²,采用 7nm 工艺制造——回顾 ISSCC2020 的论文,7nm 恰恰是 SRAM 的微缩之路遇挫的拐点。
缓存芯片通过混合键合、TSV(Through Silicon Vias,硅通孔)工艺与 CCD(背面)垂直连接,该单元包含 4 个组成部分:最下层的 CCD、上层中间部分 L3D,以及上层两侧的支撑结构——采用硅材质,将整组结构在垂直方向找平,并将下方 CCX(Core Complex,核心复合体)部分的热量传导到顶盖。
AMD 在 Zen3 架构核心设计之初就备了这一手,预留了必要的逻辑电路以及 TSV 电路,相关部分大约使 CCD 增加了 4% 的面积。L3D 堆叠的位置正好位于 CCD 的 L2/L3 Cache区域上方,这一方面匹配了双向环形总线的 CCD 内的 Cache 居中、CPU 核心分居两侧的布局,另一方面是考虑到(L3)Cache的功率密度相对低于CPU核心,有利于控制整个 Cache 区域的发热量。

△ 3D V-Cache 结构示意图
Zen3 的 L3 Cache 为 8 个切片(Slice),每片4MB;L3D 也设计为 8 个切片,每片 8MB。两组 Cache 的每个切片之间是 1024 个 TSV 连接,总共 8192 个连接。AMD 宣称这外加的L3 Cache 只增加 4 个周期的时延。
随着 Zen4 架构处理器进入市场,第二代 3D V-Cache 也粉墨登场,其带宽从上一代的 2TB/s 提升到 2.5TB/s,容量依旧为 64MB,制程依旧为 7nm,但面积缩减为 36mm²。缩减的面积主要是来自 TSV 部分,AMD 宣称基于上一代积累的经验和改进,在 TSV 最小间距没有缩小的情况下,相关区域的面积缩小了 50%。代号 Genoa-X 的 EPYC 系列产品预计在 2023 年中发布。
SRAM 容量增加可以大幅提高 Cache 命中率,减少内存延迟对性能的拖累。AMD 3D V-Cache 以比较合理的成本,实现了 Cache 容量的巨大提升(在CCD 内 L3 Cache 基础上增加 2 倍),对性能的改进也确实是相当明显。代价方面,3D V-Cache 限制了处理器整体功耗和核心频率的提升,在丰富了产品矩阵的同时,用户需要根据自己的实际应用特点进行抉择。
那么,堆叠 SRAM 会是 Chiplet 大潮中的主流吗?

△ 应用 3D V-Cache 的 AMD EPYC 7003X 处理器
说到这里,其实是为了提出一个外部 SRAM 必须考虑的问题:更好的外形兼容性。堆叠于处理器顶部是兼容性最差的形态,堆叠于侧面的性能会有所限制,堆叠于底部则需要 3D 封装的进一步普及。对于第三种情况,使用硅基础层的门槛还是比较高的,可以看作是 Chiplet 的一个重大阶段。以目前 AMD 通过 IC 载板布线水平封装 CCD 和 IOD 的模式,将 SRAM 置于 CCD 底部是不可行的。至于未来 Zen 5、Zen 6 的组织架构何时出现重大变更还暂时未知。
对于数据中心,核数是硬指标。表面上,目前 3D V-Cache 很适合与规模较小的 CCD 匹配,毕竟一片 L3D 只有几十平方毫米(mm²)的大小。但其他高性能处理器的核心尺寸比 CCD 大得多,在垂直方向堆叠 SRAM 似乎不太匹配。但实际上,这个是处理器内部总线的特征决定的问题:垂直堆叠 SRAM,不论其角色是 L2 还是 L3 Cache,都更适合 Cache 集中布置的环形总线架构。
x86 服务器 CPU 对 eDRAM 则没有什么兴趣。 在处理器内部,其面积占用依旧不可忽视,且其本质是 DRAM,目前仍未看到 DRAM 能够推进到 10nm 以下制程。IBM 的 Power10 基于三星的 7nm 制程,便不再提及 eDRAM 的问题。
在处理器外部,eDRAM 并非业界广泛认可的标准化产品,市场规模小,成本偏高,性能和容量也相对有限。
后起之秀HBM(High Bandwidth Memory,高带宽内存)则很好地解决了上述问题:
首先,不去 CPU 所在的 die 里抢地盘;
其次,纵向堆叠封装,可通过提升存储密度实现扩容;
最后,在前两条的基础上,较好的实现了标准化。 HBM 的好处都是通过与 CPU 核心解耦实现的,代价是生态位更靠近内存而不是 Cache,以时延换容量,很科学。 向下发展:基础层加持 英特尔数据中心 Max GPU 系列引入了 Base Tile的概念,姑且称之为基础芯片。相对于中介层的概念,我们也可以把基础芯片看作是基础层。基础层表面上看与硅中介层功能类似,都是承载计算核心、高速 I/O(如 HBM),但实际上功能要多得多。硅中介层的本质是利用成熟的半导体光刻、沉积等工艺(65nm 等级),在硅上形成超高密度的电气连接。而基础层更进一步:既然都要加工多层图案,为什么不把逻辑电路之类的也做进去呢?

△ 英特尔数据中心 Max GPU
Intel 在 ISSCC2022 中展示了英特尔数据中心 Max GPU 的Chiplet(小芯片)架构,其中,基础芯片面积为 640mm²,采用了 Intel 7 制程——这是目前Intel用于主流处理器的先进制程。为何在“基础”芯片上就需要使用先进制程呢?因为 Intel 将高速 I/O 的 SerDes 都集成在基础芯片中了,其作用有点儿类似 AMD 的 IOD。这些高速 IO 包括 HBM PHY、Xe Link PHY、PCIe 5.0,以及,这一节的重点:Cache。这些电路都比较适合 5nm 以上的工艺制造,将它们与计算核心解耦后重新打包在一个制程之内是相当合理的选择。
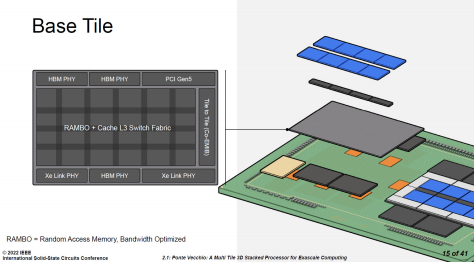
△ 英特尔数据中心Max GPU的基础芯片。注意,此图中的两组 Xe Link PHY应为笔误。芯片下方应为两个 HBM PHY 和一个Xe Link PHY 英特尔数据中心 Max GPU 系列通过 Foveros 封装技术在基础芯片上方叠加 8 颗计算芯片(Compute Tile)、4 颗 RAMBO 芯片(RAMBO Tile)。计算芯片采用台积电 N5 工艺制造,每颗芯片都自有 4MB L1 Cache。RAMBO是“Random Access Memory, Bandwidth Optimized”的缩写,即为带宽优化的随机访问存储器。独立的 RAMBO 芯片基于 Intel 7 制程,每颗有 4 个 3.75MB 的 Bank,共 15MB。每组 4 颗 RAMBO 共提供了 60MB 的 L3 Cache。此外,在基础芯片中也有 RAMBO,容量有 144MB,外加 L3 Cache 的交换网络(Switch Fabric)。
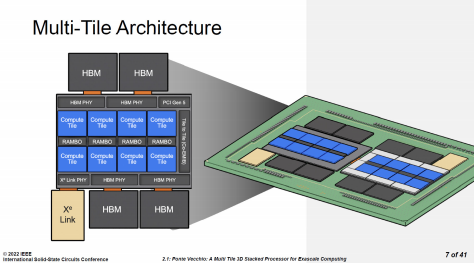
△ 英特尔数据中心 Max GPU 的 Chiplet 架构 因此,在英特尔数据中心 Max GPU 中,基础芯片通过了 Cache 交换网络,将基础层内的 144MB Cache,与 8 颗计算芯片、4 颗 RAMBO 芯片的 60MB Cache 组织在一起,总共 204MB L2/L3 Cache,整个封装是两组,就是 408MB L2/L3 Cache。
英特尔数据中心 Max GPU 的每组处理单元都通过 Xe Link Tile 与另外 7 组进行连接。Xe Link 芯片采用台积电 N7 工艺制造。

△ Xe HPC 的逻辑架构
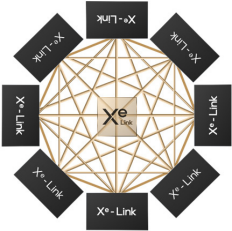
△ Xe Link 的网状连接
前面已经提到,I/O 芯片独立是大势所趋,共享 Cache 与 I/O 拉近也是趋势。英特尔数据中心 Max GPU 将 Cache 与各种高速 I/O 的 PHY 集成在同一芯片内,正是前述趋势的集大成者。至于 HBM、Xe
Link 芯片,以及同一封装内相邻的基础芯片,则通过 EMIB(爆炸图中的橙色部分)连接在一起。

△ 英特尔数据中心Max GPU爆炸图
根据英特尔在 HotChips 上公布的数据,英特尔数据中心 Max GPU 的 L2 Cache 总带宽可以达到 13TB/s。考虑到封装了两组基础芯片和计算芯片,我们给带宽打个对折,基础芯片和 4 颗 RAMBO 芯片的带宽是 6.5TB/s,依旧远远超过了目前至强和 EPYC 的 L2、L3 Cache 的带宽。其实之前 AMD 已经通过了指甲盖大小的 3D V-Cache 证明了 3D 封装的性能,那就更不用说英特尔数据中心 Max GPU 的 RAMBO 及基础芯片的面积了。

△ 英特尔数据中心Max GPU的存储带宽
回顾一下 3D V-Cache 的弱点——“散热”不良,我们还发现将 Cache 集成到基础芯片当中还有一个优点:将高功耗的计算核心安排在整个封装的上层,更有利于散热。再往远一些看,在网格化的处理器架构中,L3 Cache 并非简单的若干个块(切片),而是分成数十甚至上百单元,分别挂在网格节点上的。基础芯片在垂直方向可以完全覆盖(或容纳)处理器芯片,其中的 SRAM 可以分成等量的单元与处理器的网格节点相连。
换句话说,对于网格化的处理器,将 L3 Cache 移出到基础芯片是有合理性的。目前已经成熟的 3D 封装技术的凸点间距在 30~50 微米的量级,足够胜任每平方毫米内数百至数千个连接的需要,可以满足当前网格节点带宽的需求。更高密度的连接当然也是可行的,10 微米甚至亚微米的技术正在推进当中,但优先的场景是 HBM、3D NAND 这种高度定制化的内部堆栈的混合键合,未必适合 Chiplet 对灵活性的要求。
编辑:黄飞
-
芯片晶圆堆叠过程中的边缘缺陷修整2025-05-22 2047
-
元器件PIP(堆叠封装)和PoP(堆叠组装)的比较2009-11-20 7789
-
芯片堆叠封装技术实用教程(52页PPT)2024-11-01 4562
-
芯片的堆叠封装是怎么进化的电子学习 2022-12-10
-
内存芯片封装技术的发展与现状2018-08-28 3212
-
元器件堆叠封装结构2018-09-07 2967
-
芯片堆叠的主要形式2020-11-27 4816
-
内存芯片封装技术2010-03-17 1389
-
多层芯片堆叠封装方案的优化方法2012-01-09 1652
-
华为公布两项关于芯片堆叠技术专利2022-05-10 5426
-
华为芯片堆叠封装专利公开2022-08-11 10678
-
芯片堆叠技术在系统级封装SiP中的应用存?2023-02-11 3250
-
AI算力发展如何解决内存墙和功耗墙问题2023-04-12 3086
-
华为公布“芯片堆叠结构及其形成方法、芯片封装结构、电子设备”专利2023-08-09 3134
-
真空共晶炉/真空焊接炉——堆叠封装2025-10-27 1120
全部0条评论

快来发表一下你的评论吧 !
