

HBM4为何备受存储行业关注?
存储技术
描述
一位业内人士表示,“‘半导体游戏规则’可能在10年内改变,区别存储半导体和逻辑半导体可能变得毫无意义”。
HBM4,魅力为何如此?
01 技术的突破
2023年,在AI技术应用的推动下,数据呈现出爆炸式的增长,大幅度推升了算力需求。据悉,在AI大模型领域,未来AI服务器的主要需求将从训练侧向推理侧倾斜。而根据IDC的预测,到2026年,AIGC的算力62.2%将作用于模型推理。同时,预计到2025年,智能算力需求将达到当前的100倍。
据悉,自2015年以来,从HBM1到HBM3e各种更新和改进中,HBM在所有迭代中都保留了相同的1024位(每个堆栈)接口,即具有以相对适中的时钟速度运行的超宽接口。然而,随着内存传输速率要求不断提高,尤其是在DRAM单元的基础物理原理没有改变的情况下,这一速度将无法满足未来AI场景下的数据传输要求。为此,下一代HBM4需要对高带宽内存技术进行更实质性的改变,即从更宽的2048位内存接口开始。
接口宽度从每堆栈1024位增加到每堆栈2048位,将使得HBM4具备的变革意义。
当前,生成式人工智能已经成为推动DRAM市场增长的关键因素,与处理器一起处理数据的HBM的需求也必将增长。未来,随着AI技术不断演进,HBM将成为数据中心的标准配置,而以企业应用为重点场景的存储卡供应商期望提供更快的接口。
根据DigiTimes援引Seoul Economy的消息:下一代HBM4内存堆栈将采用2048位内存接口。
将接口宽度从每堆栈1024位增加到每堆栈2048位将是HBM内存技术所见过的最大变化。自2015年以来,从HBM1到HBM3e各种更新和改进中,HBM在所有迭代中都保留了相同的1024位(每个堆栈)接口。
采用2048位内存接口,理论上也可以使传输速度再次翻倍。例如,英伟达的旗舰Hopper H100 GPU,搭配的六颗HBM3达到6144-bit位宽。如果内存接口翻倍到2048位,英伟达理论上可以将芯片数量减半到三个,并获得相同的性能。
回顾HBM发展历史,由于物理限制,使用HBM1的显卡的内存上限为4GB。然而,随着时间的推移,SK海力士和三星等HBM制造商已经改进了HBM的缺点。
HBM2将潜在速度提高了一倍,达到每个堆栈256GB/s,最大容量达到8GB。2018年,HBM2进行了一次名为HBM2E的小更新,进一步将容量限制提高到24GB,并带来了另一次速度提升,最终达到峰值时的每芯片460GB/s。
当HBM3推出时,速度又翻了一番,允许每个堆栈最大819GB/s。更令人印象深刻的是,容量增加了近三倍,从24GB增加到64GB。和HBM2E一样,HBM3看到了另一个中期升级,HBM3E,它将理论速度提高到每堆栈1.2 TB/s。
在此过程中,HBM在消费级显卡中逐渐被更便宜的GDDR内存所取代。HBM越发成为成为数据中心的标准配置,以企业应用为重点场景的存储卡供应商们期望提供更快的接口。
有机遇就有挑战
目前,HBM主要是放置CPU/GPU的中介层上,并使用1024bit接口连接到逻辑芯片。SK海力士目标是将HBM4直接堆叠在逻辑芯片上,完全消除中介层。HBM4很可能与现有半导体完全不同,散热问题也随之而来。因此,要想为逻辑+存储这一集成体散热,可能需要非常复杂的方法,液冷和浸没式散热或是解决方案。 HBM主要是通过硅通孔技术进行芯片堆叠,以增加吞吐量并克服单一封装内带宽的限制,将数个DRAM裸片像楼层一样垂直堆叠。在HBM4技术实现上,一个模块中堆叠更多的内存芯片的技术复杂性必然将进一步提高,主要难题在于需要增加硅通孔数量并缩小凸块间距。
例如为了生产 HBM4 内存堆栈(包括 16-Hi 堆栈),三星需要完善 SangJoon Hwang 提到的几项新技术。其中一项技术称为 NCF(非导电薄膜),是一种聚合物层,可保护 TSV 的焊接点免受绝缘和机械冲击。另一种是 HCB(混合铜键合),这是一种键合技术,使用铜导体和氧化膜绝缘体代替传统焊料,以最大限度地减少 DRAM 器件之间的距离,并实现 2048 位接口所需的更小的凸块。这不是一项简单的工作。
02 入局
三星电子的技术团队执行副总裁兼 DRAM 产品主管 SangJoon Hwang在公司博客文章中写道“展望未来,HBM4 预计将于 2025 年推出,其技术针对正在开发的高热性能进行了优化,例如非导电薄膜 (NCF) 组装和混合铜接合 (HCB),”。
尽管三星预计 HBM4 将于 2025 年推出,但其生产可能会在 2025-2026 年开始,因为业界需要为该技术做大量准备。与此同时,三星将为客户提供数据传输速率为 9.8 GT/s 的 HBM3E 内存堆栈,每个堆栈的带宽为 1.25 TB/s。
在封装技术方面,三星采用了无凸点键合技术。无凸点键合是一种先进的封装技术,它将芯片与芯片之间直接进行连接,无需使用传统的微凸点键合。这种技术可以显著提高内存的I/O速度和可靠性,同时降低了制造成本。
三星在无凸点键合技术上的突破得益于其在封装领域的深厚积累和技术积累。通过不断研发和创新,三星成功地将无凸点键合技术应用到HBM4内存的生产中,实现了铜层与铜层之间的直接互连。这种直接互连的方式可以大幅度提高内存的传输速度和稳定性,同时降低了功耗。
三星在HBM4内存技术的发展中展现了强大的研发实力和技术创新能力。通过工艺学习和封装技术的创新,三星成功地将FinFET立体晶体管和无凸点键合技术应用到HBM4内存的生产中。这些新技术的应用使得HBM4内存具有更高的性能、更低的功耗和更低的制造成本。
今年早些时候,美光透露“HBMNext”内存将于 2026 年左右出现,提供 32GB 至 64GB 之间的每堆栈容量以及每堆栈 2 TB/s 或更高的峰值带宽,较 HBM3E 的每堆栈 1.2 TB/s 显着增加。要构建 64GB 堆栈,需要具有 32GB 内存设备的 16-Hi 堆栈。尽管 HBM3 规范也支持 16-Hi 堆栈,但到目前为止还没有人宣布此类产品,而且看起来如此密集的堆栈只会通过 HBM4 进入市场。
11月,据韩媒中央日报(Joongang.co.kr)报道,韩国内存芯片大厂SK海力士正计划携手英伟达(NVIDIA)开发全新的GPU,拟将其新一代的高带宽內存(HBM4)与逻辑芯片堆叠在一起,这也将是业界首创。SK海力士已与英伟达等半导体公司针对该项目进行合作,据报道当中的先进封装技术有望委托台积电,作为首选代工厂。
SK海力士目标是将未来的HBM4以3D堆叠的形式堆叠在英伟达、AMD等公司的逻辑芯片上,预计该HBM4内存堆栈将采用2048位接口。
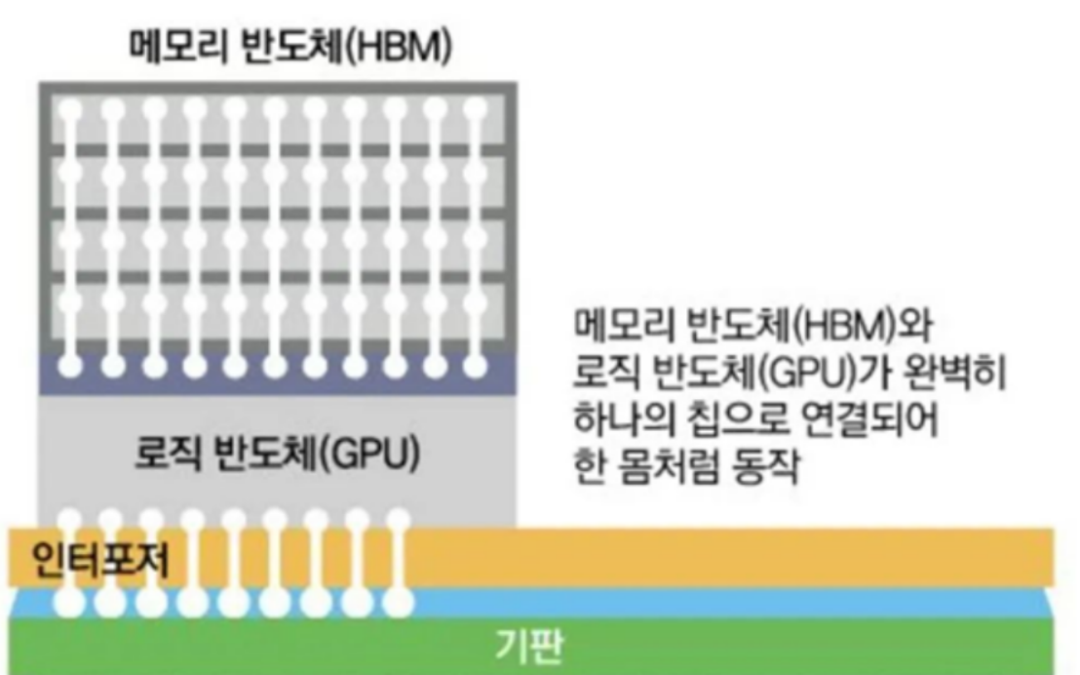
图:SK海力士HBM4计划连接方式(来源:韩国中央日报)
外媒Tom’s Hardware指出,这种设计与AMD V-Cache类似,后者将一小块L3缓存(cache)直接放在CPU顶部,新技术则是则将GPU所有HBM內存放在GPU顶部或几个芯片的顶部。
这种技术优点是缩小封装尺寸、提高容量和性能,但散热将是最大问题。比如采用V-Cache的AMD CPU,必须降低TDP和主频,以补偿3D cache产生的额外热量,像英伟达H100这种数据中心GPU,需要80-96GB的HBM,在容量和热量与V-cache完全难比拟。现在一块计算中心计算卡的功耗可能是几百瓦,即便只是HBM部分也相当耗电,要做好散热可能需要非常复杂的方式。
另外,选择这种集成方法也将改变芯片的设计和制造方式,存储器与逻辑芯片将采用相同的工艺技术,而且会在同一间晶圆厂生产,确保最终的性能。如果仅考虑DRAM的成本,那么确实会有较大幅度的增长,所以各方都还没有真正认真考虑这一方案。
据了解,SK海力士正在与包括英伟达在内的芯片设计公司讨论HBM4集成设计方案。SK海力士和英伟达可能从一开始就进行了合作,而且会选择在台积电生产,将使用晶圆键合技术将SK海力士的HBM4堆叠在逻辑芯片上。
此前,SK海力士的一位负责人曾强调,“最关键的作用是制造工厂(FAB)和封装部门之间的紧密沟通,因为HBM需要在后处理方面进行先发制人的投资。”他补充道:“SK海力士已经能够开发出与竞争对手不同的封装技术,并从合作伙伴那里获得长期独家的关键材料。”
面对三星的竞争,SK海力士并不担心。“虽然三星电子可以通过同时提供存储器和逻辑芯片工艺来引领HBM领域。”但SK海力士的一位负责人表示,“客户不希望一家公司占据主导地位,他们目前重视英伟达、台积电和SK海力士之间的合作。”
审核编辑:黄飞
-
AI加速器需求倒逼HBM4量产加速,三家国际存储巨头亮出进度表2026-05-27 7351
-
特斯拉欲将HBM4用于自动驾驶,内存大厂加速HBM4进程2024-11-28 3910
-
全球首款HBM4量产:2.5TB/s带宽超越JEDEC标准,AI存储迈入新纪元2025-09-17 6919
-
SK海力士提前完成HBM4内存量产计划至2025年2024-05-06 1754
-
台积电在欧洲技术研讨会上展示HBM4的12FFC+和N5制造工艺2024-05-17 1870
-
台积电将采用HBM4,提供更大带宽和更低延迟的AI存储方案2024-05-20 2111
-
台积电准备生产HBM4基础芯片2024-05-21 1802
-
SK海力士HBM4芯片前景看好2024-05-30 1961
-
HBM3E量产后,第六代HBM4要来了!2024-07-28 7728
-
三星电子加速推进HBM4研发,预计明年底量产2024-08-22 1813
-
特斯拉或向SK海力士、三星采购HBM4芯片2024-11-21 1951
-
美光发布HBM4与HBM4E项目新进展2024-12-23 1906
-
Cadence推出HBM4 12.8Gbps IP内存系统解决方案2025-05-26 1911
-
SK海力士宣布量产HBM4芯片,引领AI存储新变革2025-09-16 2336
-
英伟达三大存储芯片供应商已获HBM4供货资格2026-06-08 902
全部0条评论

快来发表一下你的评论吧 !
