

数据中心CPU芯粒化及互联方案分析-PART2
描述
随着生成式AI注入数据中心的步伐加快,CPU 在数据中心的部署变得愈发重要,为应对数据中心CPU性能提升挑战,Chiplet和互联技术的双剑合璧,经芯片巨头在自身产品体系中的多次实践,显现出蓬勃的生机和其普适性的一面。
2023年1月,英特尔第四代至强可扩展处理器Sapphire Rapids(SPR)首次亮相。SPR是一款专门针对AI工作负载优化的CPU,具有典型的Multi-Die架构,其亮点包括更高的核心数量、改进的缓存层次结构以及增强的互联技术。对英特尔来说,它也是剑指AMD EPYC,意在夺回HPC市场的野心之作。
更多的核心,更强的性能

英特尔称,ERP整体性能和每瓦性能指标均处于领先地位。与前一代处理器相比,基础算力提升53%,人工智能性能提升10倍,5G vRAN性能提升2倍,网络&存储性能提升2倍,数据分析性能提升3倍,科学计算性能提升3.7倍。如此卓越的性能提升主要来自核心数量的大幅增长,以及高效的互联方案。

1、50%核心数量增长+单核性能增强
SPR是英特尔首个Chiplet设计的Xeon处理器,由四个相同的die(芯粒)组成,die间通过英特尔的EMIB技术连接。其中,每个Die包含15个CPU内核,并分别配有自己的内存和IO控制器等各功能单元。核心部分为英特尔7工艺的Golden Cove P核(大核),设计支持60核,实际启用56核,总核心数较上一代IceLake增长了50%。

SPR延续了英特尔的服务器处理器策略:优先考虑扩展核心数量,同时提供强大的计算能力,以大幅提高CPU在处理大量数据,如进行科学计算、机器学习、图形处理时的性能。
最终,SPR实现了105MB Total LLC,307GB/s Memory Bandwidth,在SPECrate@2017_int_base基准测试中,得分为495。
如前文所述,除了CPU核数提升之外,SPR在CPU单核性能上也做了优化,如提高了CPU的各级缓存的大小,还为每个核心引入了两个512位的FMA单元,同时支持一级对AMX指令集,旨在进一步提升性能。
2:优化缓存层次结构
除了核心性能的优化,Golden Cove的一项重大改进是缓存层次结构,这也是SPR与AMD EPYC系列的显著区别之一:每个Golden Cove核心除了包2MB L2缓存外,还搭载了1.875MB的LLC切片,每个Die总28.125M LLC为56个核心所共享(SPR总缓存达112.5 MB)。相较客户端Golden Cove,SPR在处理大量数据的应用程序时,能提供更好的性能表现。
对于需要频繁访问LLC的数据密集型工作负载,LLC集成在核心中可以大幅度减少LLC控制器和缓存间的连接,降低功耗。这种设计也为跨线程访问提供了极大的灵活性。在需要时,一个核心可以访问全部的LLC,一个LLC也可以服务于多个核心。
不过,这种跨线程访问的缺点也很明显,在某些情境,如需要跨越两个Die以上的远端存储访问时,可能会增加LLC控制器的工作负载,造成较高的延迟和Workload balance的不均衡。
3、优化设计成本
由于集成了多达60个核心(实际应用了56个)使得英特尔制造一个SoC芯片变得不切实际,从而转向Chiplet和2.5D先进封装,并通过Multi-Die架构简化设计和制造。
基于Multi-Die架构,英特尔只需要设计两组镜像的掩模,再旋转这两个模具即可。不过,这种架构也为Die间的互联带来了挑战。
互联:由繁至简
为了连接数量繁多的核心和缓存,英特尔在EMIB链路上运行了一个巨大的Mesh结构,将所有核心连接到它们各自的LLC切片,以及SPR上的其他组件,如内存控制器、各种加速器和其他I/O设备中,形成一个多Die的系统结构。
网络加速单元
作为升级的重点,SPR在每个Die中嵌入了一个DSA网络加速单元,可以在特定网络工作负载中实现数倍的效率提升。该加速单元具有400Gb/s互联带宽,160Gb/s压缩带宽,每秒能够做出400M的负载平衡决策。
DSA全称为Data Streaming Accelerator,主要针对内存的搬移和传输的操作进行加速,能提高存储、网络和数据密集型工作负载的性能,类似于GPU等外部加速器。
在数据中心中,DSA可以更有效地处理如进行如压缩/解压缩、加/解密、内存搬移等特定工作负载,带来大幅的性能提升。某些场景下,只需一个核心或部分核心就能够处理复杂的工作负载,提高芯片的能效比。这也是英特尔为代表的头部企业开始热衷在处理器中内置加速器的因素之一。
基于 RoCE V2 协议自研 RDMA 技术,奇异摩尔自研Domain Specific Accelerator 系列专用领域加速器系列,具备高速以太网互联能力,提供可编程的专用数据处理加速算法,同时集成了多种通用数据处理硬件加速器,高带宽,高吞吐,硬件灵活可配置、软件可编程,可实现芯粒/芯片间的高速传输。

D2D:DDR5 & EMIB
互连系统方面,每个Die配有2个128位的DDR5内存接口,DDD5采用优化版的EMIB工艺,单个EMIB的D2D带宽高达500GB/s,功耗仅为0.5pj/bit,延迟(PHY Latency end-to-end TX+RX) 2.4ns。从die间功耗和延迟的方面来看,SPR已接近一个SoC。
为了进一步增强内存带宽,EMIB技术首次支持HBM扩展,并特别为SPR设计了一种HBM变体,通过EMIB连接四个HBM,实现内存性能方面的显著提升。

Chip2Chip:UPI & PCIe
在SPR中,每个Die还搭载了32个PCIe 5(CXL 1.1),以及24个UPI。配置为每个插槽80xPCIeGen5通道;以及24个UPI,支持最多8个芯片的互连,也意味着Sapphire Rapids芯片最多可以组建8路计算平台。

挑战与解决方案
因可简化设计,Multi-Die架构在2颗芯粒的互联架构中显现出显著的性价比优势,但一旦芯粒超过2个,就会面临互联挑战。

2023年5月,英特尔公布了SPR的下一代处理器,Emerald Rapids(ERP)。总体来说,英特尔基于SPR 相同的平台和较新的Raptor Cove核心,通过优化物理设计,实现了“巨大的PPW”改进。但令人瞩目的改变是,ERP的芯粒数量减少到两个,这一架构上的回退也从侧面反映出Mutil die模式下,多Die互联难度之高。
此外,因芯粒数量减少导致芯片尺寸过大,加之先进工艺的使用,也带来了成本高涨的问题;再次,在Mutil die架构中,为了维持高带宽和低功耗,EMIB的使用也会相应的增加成本,ERP的生产成本实际上比 SPR 更高。假设成品率和芯片可回收性完美,相比 SPR-MCC,EMR 只能在每个晶圆上生产 34 个 CPU,低于每个 SPR 晶圆 37 个 CPU。如果考虑到完美良率之外的任何因素,EMR 的成本就会更高。
相比之下,AMD 则选择了一种更为简单的方案,通过独立IO Die和CCD中的LLC集群,避免了复杂的多核互连问题。
下一站:Central IO Die
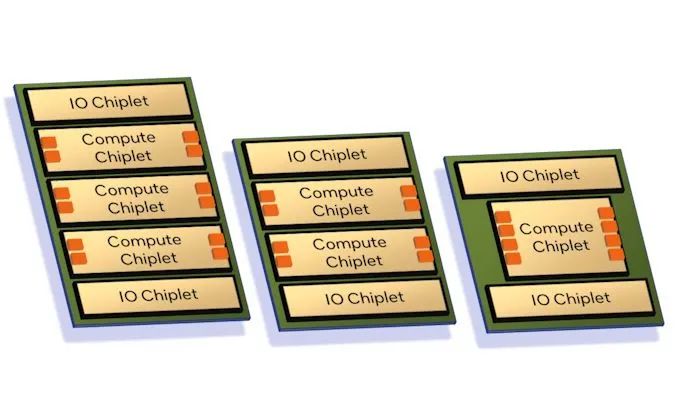
Hot Chips 2023 上,英特尔将旗下数据中心芯片分为两类,Granite 和 Sierra ,二者都基于chiplet设计,并首次使用了独立的 I/O 芯粒,通过 EMIB技术与计算单元封装在一起。英特尔服务器处理器正式转向Central IO Die架构。
随着核心数量的增长和多die模式的流行,过去几年中,各大计算芯片企业逐渐从Multi-Die模式转向Central IO Die模式。以 IO Die 为代表的新兴互联技术正在打破芯片内固有的互联方式。片内互联技术向“更高的集成度、更短的距离、更高的效率”转变。
在国内赛道,奇异摩尔作为片内互联领域的代表企业,核心产品涵盖2.5D interposer、2.5D IO Die、3D Base Die、NDSA、全系列Die2Die IP及相关Chiplet系统解决方案。
Central IO Die通过将IO功能从算芯片中分离出来,整合多种互联接口,让计算单元通过IO Die进行统一互联,可以极大程度的简化互联设计,增加带宽、并降低多Die间的互联延迟。AMD Zen系列、Ampere 和 AWS 的 Graviton3 都在采用一个或多个不同的 IO芯粒。数据中心处理器Central IO Die 的模式正在到来。
-
优化800G数据中心:高速线缆、有源光缆和光纤跳线解决方案2025-03-24 801
-
数据中心高密度MPO/MTP布线系统解决方案2017-01-18 4651
-
锐捷助互联网数据中心网络自动化、可视化运维2017-01-25 5594
-
数据中心布线方案:数据中心怎样选择光纤布线?2018-04-20 2515
-
数据中心光互联解决方案2020-07-03 3290
-
数据中心是什么2021-07-12 2112
-
模块化数据中心的主要组成部分2021-09-08 2101
-
互联网数据中心安全管理方案2012-08-12 2168
-
开关电源的原理与设计.part22015-11-30 611
-
全美经典电路.part22016-02-19 542
-
FPGA_Verilog学习资料part22016-03-14 777
-
Arduino从基础到实践part22016-12-13 698
-
电路原理(第7版).part22017-03-01 1303
-
STM32 USB培训_Part2 USB IP及其库的使用2017-09-21 798
-
电子设计常用表格Part22023-04-25 518
全部0条评论

快来发表一下你的评论吧 !
